本文主要是介绍XXL-Job使用GLUE(Java)调度REST接口,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这里就不介绍xxl-job的使用教程了,很简单很好用。
本次仅仅分享使用xxl-job调用REST接口的过程。
首先xxl-job-admin你应该先跑起来,然后新建一个SpringBoot项目里面加上xxl-job的依赖,xxl-job的config等配置信息
Maven中加入xxl-job-core的依赖
<!-- ===========XXL-JOB-CORE=============== --><dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>2.1.0</version></dependency>在application.properties中追加以下内容
xxl.job.admin.address = http://127.0.0.1:8080/xxl-job-admin
xxl.job.executor.appname = rone-spark
xxl.job.executor.ip = 127.0.0.1
xxl.job.executor.port = 9999
xxl.job.executor.logpath = /data/applogs/xxl-job/jobhandler
xxl.job.executor.logretentiondays = -1然后在新建一个xxl-job-config类
package com.rone.demo.XXLJob;import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${xxl.job.admin.address}")private String adminAddresses ;//="http://localhost:8080/xxl-job-admin" ;@Value("${xxl.job.executor.appname}")private String appName ;//="RoneDemo";@Value("${xxl.job.executor.ip}")private String ip ;//= "127.0.0.1";@Value("${xxl.job.executor.port}")private int port ;//= 9999;/* @Value("${xxl.job.accessToken}")*/private String accessToken;@Value("${xxl.job.executor.logpath}")private String logPath ;//@Value("${xxl.job.executor.logretentiondays}")private int logRetentionDays = -1;@Bean(initMethod = "start", destroyMethod = "destroy")public XxlJobSpringExecutor xxlJobExecutor() {logger.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppName(appName);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}}
这里注意
import org.springframework.http.*;
import org.springframework.web.client.RestTemplate;
这两个依赖是SpringBoot调用REST接口的包,因为我们要call REST所以要使用这两个依赖,一定要加上。
package com.rone.demo.XXLJob;import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.handler.annotation.JobHandler;
import com.xxl.job.core.log.XxlJobLogger;
import org.springframework.stereotype.Component;
import org.springframework.http.*;
import org.springframework.web.client.RestTemplate;
/*** 任务Handler示例(Bean模式)** 开发步骤:* 1、继承"IJobHandler":“com.xxl.job.core.handler.IJobHandler”;* 2、注册到Spring容器:添加“@Component”注解,被Spring容器扫描为Bean实例;* 3、注册到执行器工厂:添加“@JobHandler(value="自定义jobhandler名称")”注解,注解value值对应的是调度中心新建任务的JobHandler属性的值。* 4、执行日志:需要通过 "XxlJobLogger.log" 打印执行日志;*/
@JobHandler(value="sparkJobHandler")
@Component
public class RunSparkHandler extends IJobHandler {@Overridepublic ReturnT<String> execute(String warPath) throws Exception {XxlJobLogger.log("============================Run Spark Job=======================");XxlJobLogger.log("war Path : =================" + warPath);XxlJobLogger.log("============================Call Successfully=======================");return SUCCESS;}
}
接着就是直接run了,新建执行器,appName一定要与application.properties里面配置的一样,还有机器地址与端口要与配置文件中的一致
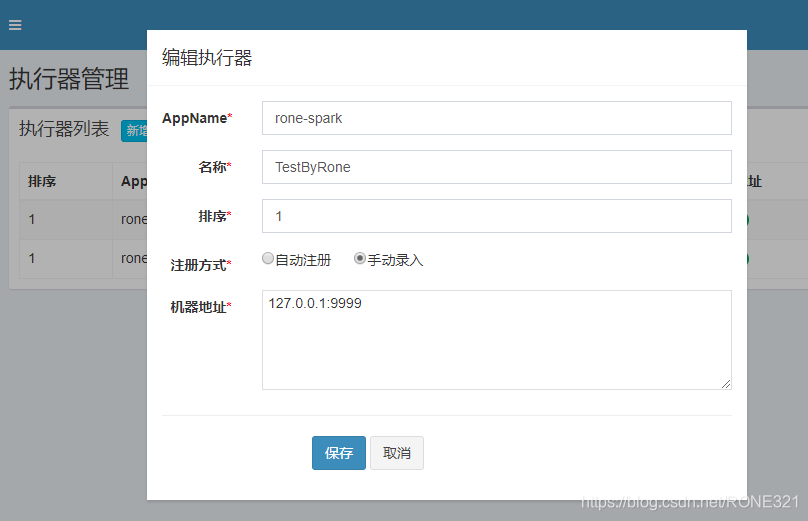
新建一个任务,选择我们刚刚建立的执行器,运行模式选择GLUE(Java),其它的参照一下就好。
 接着选择操作->GLUE IDE
接着选择操作->GLUE IDE
 我们会新开一个标签页,在新开的见面写我们需要call的端口与地址
我们会新开一个标签页,在新开的见面写我们需要call的端口与地址
 这里是详细代码,由于隐私问题我把Spark地址与端口改成了example请见谅
这里是详细代码,由于隐私问题我把Spark地址与端口改成了example请见谅
package com.xxl.job.service.handler;import com.xxl.job.core.log.XxlJobLogger;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.IJobHandler;//注意这里是我们在excutor中引入的两个RestTemplate相关包
import org.springframework.http.*;
import org.springframework.web.client.RestTemplate;public class DemoGlueJobHandler extends IJobHandler {String LIVY_HOST = "http://192.168.1.1";String HDFS_HOST = "cdh01";//192.168.1.1String LIVY_PORT = "8990";String HDFS_PORT = "50070";String SESSIONS = "sessions";String STATEMENTS = "statements";String BATCHES = "batches";@Overridepublic ReturnT<String> execute(String param) throws Exception {XxlJobLogger.log("Test RestFull");RestTemplate client = new RestTemplate();HttpHeaders headers = new HttpHeaders();String pData = "{\"file\":\"hdfs://"+HDFS_HOST+":"+HDFS_PORT+"/user/spark/SparkLR.jar\",\"className\":\"com.rone.DBUtils.MySQLOperations\"}";HttpEntity<String> entity = new HttpEntity<>(pData,headers);ResponseEntity<Map> resp = client.exchange(LIVY_HOST+":"+LIVY_PORT+"/"+BATCHES+"/", HttpMethod.POST, entity, Map.class);return ReturnT.SUCCESS;}}

然后测试执行就OK了,
这篇关于XXL-Job使用GLUE(Java)调度REST接口的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






