本文主要是介绍再谈Intel x86_64 LBR功能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、LBR
- 1.1 LBR简介
- 1.2 LBR format
- 1.3 PDCM
- 1.4 MSR_LBR_SELECT
- 二、代码演示
- 2.1 用户态demo
- 2.2 msr-tools
- 2.3 taskset
- 2.4 MSR寄存器地址
- 2.5 完整代码
- 三、perf使用lbr
- 总结
- 参考资料
前言
在这篇文章 Intel x86_64 LBR & BTS功能 中我简单的描述了Intel处理器的 LBR功能,最近我又看了Intel手册相关章节,决定再详细写一篇 LBR功能的介绍和使用。
先简单介绍下MSR寄存器:
MSR(Model Specific Register)是x86架构中的概念,指的是在x86架构处理器中,一系列用于控制CPU运行、功能开关、调试、跟踪程序执行、监测CPU性能等方面的寄存器。
不同的CPU型号或不同的CPU厂商(Intel&AMD),它的MSR寄存器可能是不一样的,它会根据具体的CPU型号的变化而变化,每款新的CPU都有可能引入新的MSR寄存器。
一、LBR
1.1 LBR简介
LBR 通过保存产生的分支和其它的控制流程在处理器的寄存器来记录软件的执行历史路径。LBR记录的FROM地址和TO地址保存在两个MSR寄存器中。
MSR_LASTBRANCH_N_FROM_IP:保存操作的源 IP,即跳转的from地址。
MSR_LASTBRANCH_N_TO_IP:保存操作的目的IP,即跳转的to 地址。

LBR的数目根据处理器的型号不同而不一样,如下图所示。
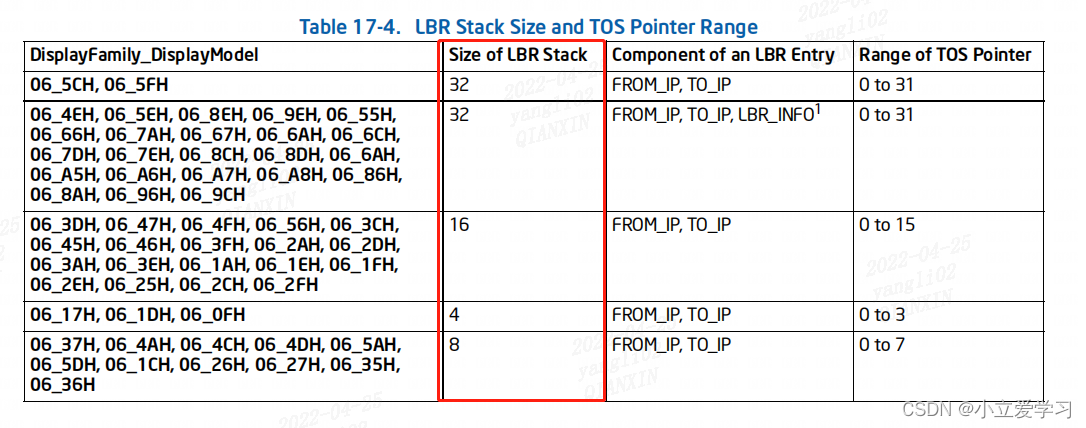
LBR记录存储在寄存器中的顺序是按照时间来的,最近的分支LBR entry 存储在 IA32_LBR_0_FROM_IP/IA32_LBR_0_TO_IP/
IA32_LBR_0_INFO中,然后下一个存储在就是IA32_LBR_1_FROM_IP/IA32_LBR_1_TO_IP/IA32_LBR_1_INFO中,以此类推。
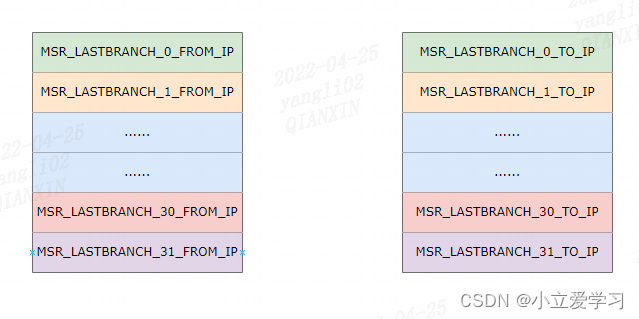
我以 LBR Stack size = 32为例子,如下图所示:
1.2 LBR format
在我们使用LBR之前,应该查询关于存储在LBR堆栈中的地址的格式。主要有四种编码格式
通过查询MSR IA32_PERF_CAPABILITIES寄存器的 bit[5:0],即0-5位。

(1)000000B
32-bit record format — Stores 32-bit offset in current CS of respective source/destination.
(2)000001B
64-bit LIP record format — Stores 64-bit linear address of respective source/destination.
(3)000010B / 000011B / 000100B / 000101B
64-bit EIP record format — Stores 64-bit offset (effective address) of respective source/destination.
(4)000110B / 000111B
64-bit LIP record format — Stores 64-bit linear address (CS.Base + effective address) of respective source/destination.
1.3 PDCM
在使用LBR之前先查询是否支持性能和调试功能。
通过CPUID指令查询是否提供处理器对架构 MSR IA32_PERF_CAPABILITIES 的支持。
CPUID.01H:ECX[PERF_CAPAB_MSR] (bit 15).
关于cpuid指令可以看我这篇文章:Intel x86_64使用cpuid指令获取CPU信息
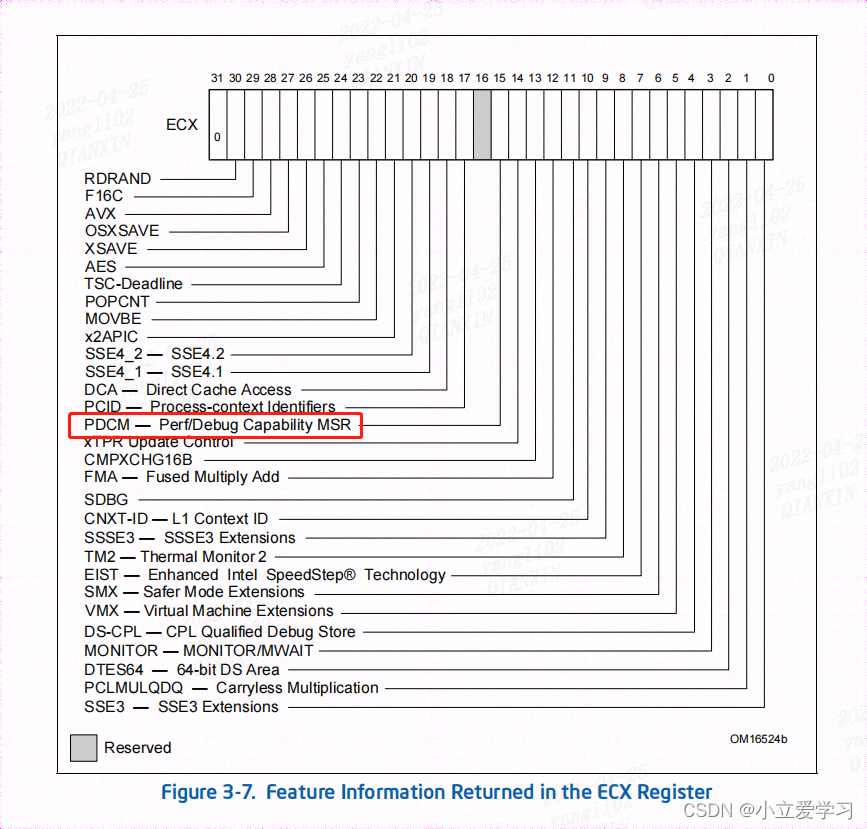
PDCM:值为 1 表示处理器支持性能和调试功能 MSR IA32_PERF_CAPABILITIES
判断代码如下:
#include <linux/kernel.h>
#include <linux/module.h>//Processor’s support for the architectural MSR IA32_PERF_CAPABILITIES
#define PDCM_IS_SUPPORT (1<<15)//内核模块初始化函数
static int __init lkm_init(void)
{ unsigned int eax = 0;unsigned int ebx = 0;unsigned int ecx = 0;unsigned int edx = 0;cpuid(1, &eax, &ebx, &ecx, &edx);if(!(ecx & PDCM_IS_SUPPORT)) {printk("Don't support PDCM feature\n");return 0;}printk("support PDCM feature\n");return 0;}//内核模块退出函数
static void __exit lkm_exit(void)
{printk(KERN_DEBUG "exit\n");
}module_init(lkm_init);
module_exit(lkm_exit);MODULE_LICENSE("GPL");1.4 MSR_LBR_SELECT
MSR_LBR_SELECT(该寄存器的地址为1C8H) 在 RESET 时会清零,并且 LBR filtering被禁用,即所有的分支记录类型都将被捕获。
MSR_LBR_SELECT提供位字段,用于指定不被LBR捕获的分支类型。
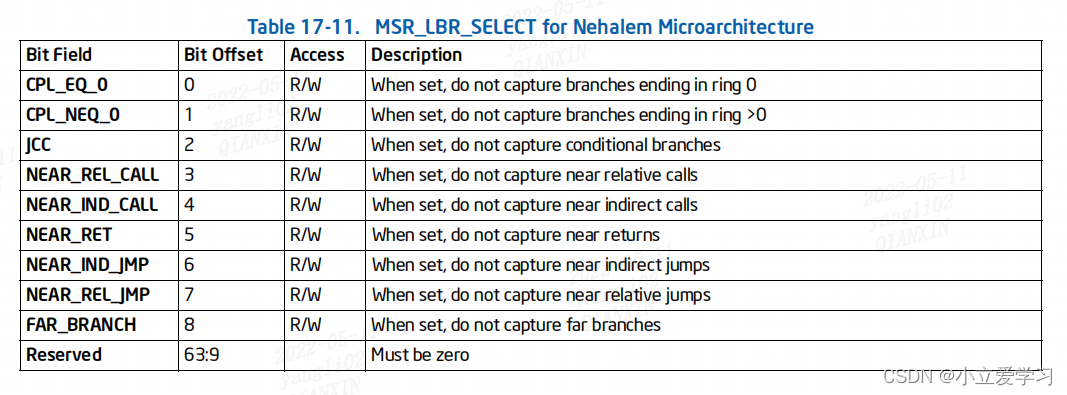
比如:
将MSR_LBR_SELECT的bit0置为1,那么LBR将不会捕获内核态(ring = 0)的分支跳转指令。
将MSR_LBR_SELECT的bit1置为1,那么LBR将不会捕获用户态(ring > 0)的分支跳转指令。
二、代码演示
实验平台:
Intel x86_64
centos 7.8
注意是在物理机上实验,虚拟机不支持LBR。
这里我为了简单起见,采用shell脚本来进行代码演示,用来捕获用户态的代码执行流的记录。
2.1 用户态demo
这里是一个最简单的while循环demo,这个dmeo将会产生许多的jmp指令。
#include <stdio.h>int main()
{int i = 0;while(1) {i++;}return 0;
}
让我们来看看其二进制反汇编代码,objdump -d a.out:

从反汇编我们可以看出while循环一直在执行jmp指令,产生的跳转记录如下:
{From : 4004fc , to : 4004f8} //jmp指令
2.2 msr-tools
在这里我通过msr-tools工具包在linux shell命令上来读取或写MSR寄存器值。
下载地址有两个,我选择的是下面的一个:
https://pkgs.org/download/msr-tools
https://mirrors.edge.kernel.org/pub/linux/utils/cpu/msr-tools/
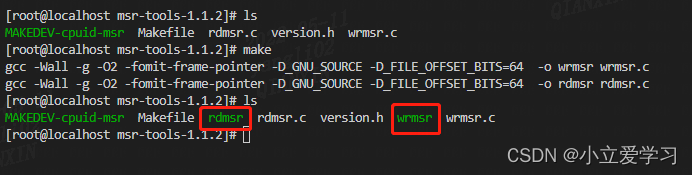
下面便是wrmsr和rdmsr的使用方法,我标记为红色的将是我要用的参数选项。
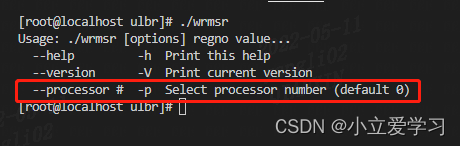
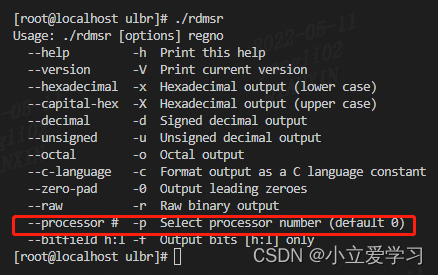
2.3 taskset
taskset 用于在给定 PID 的情况下设置或读取正在运行的进程的 CPU 亲和性或者启动一个新的进程时设置其 CPU亲和性。CPU 亲和性是一种调度程序属性,它将进程“绑定”到系统上给定的一组 CPU上。Linux 调度程序将遵循给定的 CPU 亲和性,并且该进程不会在任何其他 CPU 上运行
我这里主要是用来把给定的进程指定在某个cpu上工作。
(1)运行a.out程序时,将该进程绑定在CPU 1上运行
taskset -c 1 ./a.out
(2)获取a.out进程运行在哪个CPU上:
taskset -p 进程号
2.4 MSR寄存器地址
查询当前CPU与LBR有关的MSR寄存器地址
可以通过cpuid指令获取CPU的DF_DM,我这里直接通过lscpu命令查看:

根据DF_DM查询Intel手册:
MSR_IA32_DEBUGCTL 寄存器的地址 0x1D9
MSR_LBR_TOS寄存器的地址:0x1C9
MSR_LBR_SELECT寄存器的地址:0x1C8
支持32对 FROM TO 记录:
MSR_LASTBRANCH_0_FROM_IP - MSR_LASTBRANCH_31_FROM_IP:0x680 - 0x69F
MSR_LASTBRANCH_0_TO_IP - MSR_LASTBRANCH_31_TO_IP:0x6C0 - 0x6DF
2.5 完整代码
# Model Specific Registers address
MSR_LASTBRANCH_0_FROM_IP=680
MSR_LASTBRANCH_0_TO_IP=6C0
MSR_IA32_DEBUGCTL=1D9
MSR_LBR_TOS=1C9
MSR_LBR_SELECT=1C8# Define ADDR_FROM and ADDR_FROM Var
ADDR_FROM=$MSR_LASTBRANCH_0_FROM_IP
ADDR_TO=$MSR_LASTBRANCH_0_TO_IP# Configuration
CORE=1 # Run the target workload on core 1 (taskset -c 1 process)
N_LBR=32 # Number of LBR records # enable MSR kernel module
sudo modprobe msr# enable LBR
sudo ./wrmsr -p ${CORE} 0x${MSR_IA32_DEBUGCTL} 0x1# do not capture branches in ring 0
sudo ./wrmsr -p ${CORE} 0x${MSR_LBR_SELECT} 0x1# wait a bit for the workload to issue enough branches
sleep 0.1# read all LBR records
for i in `seq 1 ${N_LBR}`;
#for(( i = 0; i < ${N_LBR}; i++))
doecho "LBR record : $i"echo 0x$ADDR_FROM echo "from address: "sudo ./rdmsr -p ${CORE} 0x${ADDR_FROM}echo 0x$ADDR_TOecho "to address: "sudo ./rdmsr -p ${CORE} 0x${ADDR_TO}# increament ADDR_FROM (in hex) by 1 ADDR_FROM=`echo "obase=16; ibase=16; ${ADDR_FROM} + 1;" | bc`# increament ADDR_TO (in hex) by 1 ADDR_TO=`echo "obase=16; ibase=16; ${ADDR_TO} + 1;" | bc`
done
(1)设置进程CPU亲和性:
taskset -c 1 ./a.out &
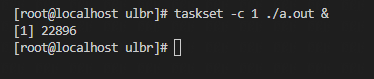
1:表示CPU1(运行在第二个CPU上)。
22896 :表示进程的PID号。
(2)运行shell脚本,查看结果:
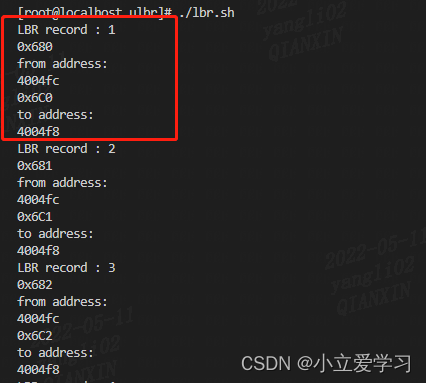
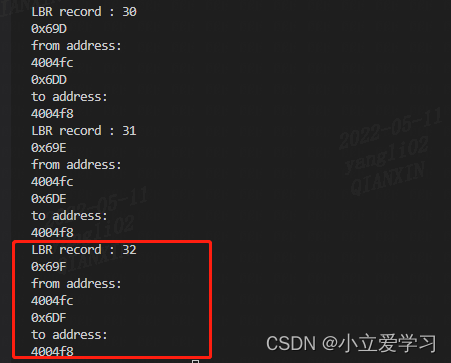
可见获取到了用户态程序的控制执行流程,并与预期一致:
{From : 4004fc , to : 4004f8} //jmp指令
三、perf使用lbr
NAMEperf-record - Run a command and record its profile into perf.data
DESCRIPTIONThis command runs a command and gathers a performance counter profile from it, into perf.data - without displaying anything.This file can then be inspected later on, using perf report.-F, --freq=Profile at this frequency.-a, --all-cpusSystem-wide collection from all CPUs (default if no target is specified).-gEnables call-graph (stack chain/backtrace) recording.--call-graphSetup and enable call-graph (stack chain/backtrace) recording, implies -g. Default is "fp".Allows specifying "fp" (frame pointer) or "dwarf"(DWARF's CFI - Call Frame Information) or "lbr"(Hardware Last Branch Record facility) as the method to collectthe information used to show the call graphs.In some systems, where binaries are build with gcc--fomit-frame-pointer, using the "fp" method will produce boguscall graphs, using "dwarf", if available (perf tools linked tothe libunwind or libdw library) should be used instead.Using the "lbr" method doesn't require any compiler options. Itwill produce call graphs from the hardware LBR registers. Themain limitation is that it is only available on new Intelplatforms, such as Haswell. It can only get user call chain. Itdoesn't work with branch stack sampling at the same time.When "dwarf" recording is used, perf also records (user) stack dumpwhen sampled. Default size of the stack dump is 8192 (bytes).User can change the size by passing the size after comma like"--call-graph dwarf,4096".
[root@localhost perf]# perf record -F 99 -a --call-graph lbr
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.726 MB perf.data (225 samples) ][root@localhost perf]# perf script
perf 9409 [000] 524426.499793: 1 cycles:ppp:26a328 native_write_msr_safe (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)209794 __intel_pmu_enable_all.isra.13 (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)209800 intel_pmu_enable_all (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)20591a x86_pmu_enable (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a4c8d perf_pmu_enable (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a5862 ctx_resched (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a59eb __perf_event_enable (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)39e368 event_function (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a008a remote_function (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)311101 generic_exec_single (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3111af smp_call_function_single (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)39f213 cpu_function_call (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a3f21 event_function_call (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a4021 _perf_event_enable (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)39f07a perf_event_for_each_child (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a87e0 perf_ioctl (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)456210 do_vfs_ioctl (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)4564b1 sys_ioctl (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)974ddb system_call (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)26a328 native_write_msr_safe (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)
注意,LBR通常受限于堆栈深度(8、16或32帧),因此它可能不适合于深层堆栈或火焰图生成,因为火焰图需要走到公共根进行合并。
以下是使用默认帧指针遍历采样的相同程序:
[root@localhost perf]# perf record -F 99 -a -g
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.635 MB perf.data (100 samples) ][root@localhost perf]#
[root@localhost perf]# perf script
swapper 0 [000] 524994.265011: 1 cycles:ppp:26a328 native_write_msr_safe (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)209794 __intel_pmu_enable_all.isra.13 (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)209800 intel_pmu_enable_all (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)20591a x86_pmu_enable (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a4c8d perf_pmu_enable (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a5862 ctx_resched (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a59eb __perf_event_enable (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)39e368 event_function (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)3a008a remote_function (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)311373 flush_smp_call_function_queue (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)311a73 generic_smp_call_function_single_interrupt (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)25715d smp_call_function_single_interrupt (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)9770a2 call_function_single_interrupt (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)7ae10e cpuidle_idle_call (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)2366de arch_cpu_idle (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)2fc3ba cpu_startup_entry (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)94feb7 rest_init (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)11861c6 start_kernel ([kernel.vmlinux].init.text)118572f x86_64_start_reservations ([kernel.vmlinux].init.text)1185885 x86_64_start_kernel ([kernel.vmlinux].init.text)2000d5 start_cpu (/usr/lib/debug/lib/modules/3.10.0-957.el7.x86_64/vmlinux)
如果不需要很长的堆栈可以使用lbr来追踪指令流。
总结
上述就是简单的使用LBR来获取应用程序的程序执行流程,可用来进行安全领域的对抗检测。
参考资料
Intel 手册 vol 3
https://sorami-chi.hateblo.jp/entry/2017/12/17/230000
https://github.com/soramichi/LBR-sample/blob/master/README.en.md
https://www.brendangregg.com/perf.html
这篇关于再谈Intel x86_64 LBR功能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






