本文主要是介绍伯克利最新研究成果:让机器人比你还了解自己的偏好,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果我们都能让家用机器人帮我们做家务就太好了。家务是我们想要完成的任务,做家务会让我们的房子更符合我们的喜好;我们希望我们的房子以一种不同于现在的方式存在。然而,大多数“不同”的方式不是很可取:

当然,我们的机器人不会笨到在我们叫它打扫房子的时候到处乱扔东西吧?不幸的是,经过强化学习训练的人工智能系统只能优化奖励功能中指定的功能,对我们可能无意中遗漏的任何东西都漠不关心。通常情况下,机器人系统常常由于忘记去囊括一些应该保持不变的事物,导致很容易得到错误的奖励。因为我们已经习惯了满足这些偏好,而且有很多这样的偏好。考虑下面的房间,想象我们想要一个机器人服务员,在餐桌上高效地为客人服务。我们可以用一个奖励函数来实现这个目标,这个函数在机器人上菜时提供1个奖励,然后用折扣来激励机器人提高效率。这样的奖励机制会出什么问题呢?我们需要如何修改奖励函数来把这一点考虑进去呢?花点时间想想。

以下是我们列出的不完整的清单:
机器人在上菜的时候,可能会在干净的家具上追踪污垢和油污,但它没有理由把污垢清理干净,因为它还急着上菜。
在匆忙送餐的过程中,机器人可能会打翻酒瓶柜,或者把把盘子滑到人面前,打翻玻璃杯。
在紧急情况下,比如停电的时候,我们不希望机器人一直上菜——如果它不能帮助我们,至少别添乱。
机器人可能会上空的或不完整的盘子,桌子上没有人想要的盘子,甚至会把盘子分成更小的盘子,这样就会有更多的盘子。
请注意,我们并不是在讨论鲁棒性和分配转移的问题:虽然这些问题值得解决,但关键是,即使我们实现了鲁棒性,简单的奖励函数仍然会激励上述不需要的行为。
我们经常听到非正式的解决方案,机器人应该在完成任务的同时尽量减少对环境的影响。这可能帮助我们避免前面提到的前三个问题,尽管最后一个问题仍然是规范游戏的一个例子。这种想法导致了对测量的影响,这种测量尝试量化一个代理所具有的“影响”,通常是通过观察实际发生的情况和机器人不做任何事情时可能发生的情况之间的差异。然而,这也惩罚了我们想让机器人做的事情。例如,如果我们让机器人给我们买咖啡,它可能会买咖啡而不是自己煮咖啡,因为这会对水、咖啡机等产生“影响”。最终,我们只希望阻止负面影响,这意味着我们需要人工智能更好地了解什么是正确的奖励功能。
我们的关键观点是,尽管人类可能很难明确自己的偏好,但有些偏好在现实世界中是隐含的:世界状态是人类优化自己偏好的结果。这就解释了为什么我们经常想让机器人在默认情况下“做什么”——如果我们已经按照自己的偏好优化世界的状态,那么大部分想要试图改变的方式都会出现糟糕的结果,所以什么也不做通常(但不总是)是一个机器人更好的选择。
由于世界的现有状态是人类偏好优化的结果,我们应该能够使用这种状态来推断人类关心什么。例如,我们当然不希望在我们整洁的房间里弄脏地板;否则我们自己也会这么做。我们也不能对肮脏的地板漠不关心,因为在某个时候,我们会穿着脏鞋子在房间里走来走去,结果弄脏了地板。唯一的解释是我们希望地板是干净的。
一个简单的设置
让我们看看是否可以将这一见解应用到最简单的可能设置中:具有少量状态、少量操作、已知动态模型(即“世界如何工作”的模型)但不正确的奖励函数的gridworlds。这是一个足够简单的设置,我们的机器人知道它的行为的所有后果。然而,问题仍然存在:虽然机器人知道将会发生什么,但它仍然无法区分好的结果和坏的结果,因为它的奖励功能是不正确的。在这些简单的环境中,很容易找出正确的奖励函数是什么,但是在一个真实的、复杂的环境中这是不可行的。
例如,考虑右边的房间,Alice让她的机器人导航到紫色的门。如果我们把这个编码成一个奖励函数,只奖励在紫色门的机器人,机器人会走到紫色门的最短路径,撞倒花瓶,因为没有人说它不应该这么做。机器人完全知道它的计划导致它打破花瓶,但默认情况下,它没有意识到它不应该打破花瓶。
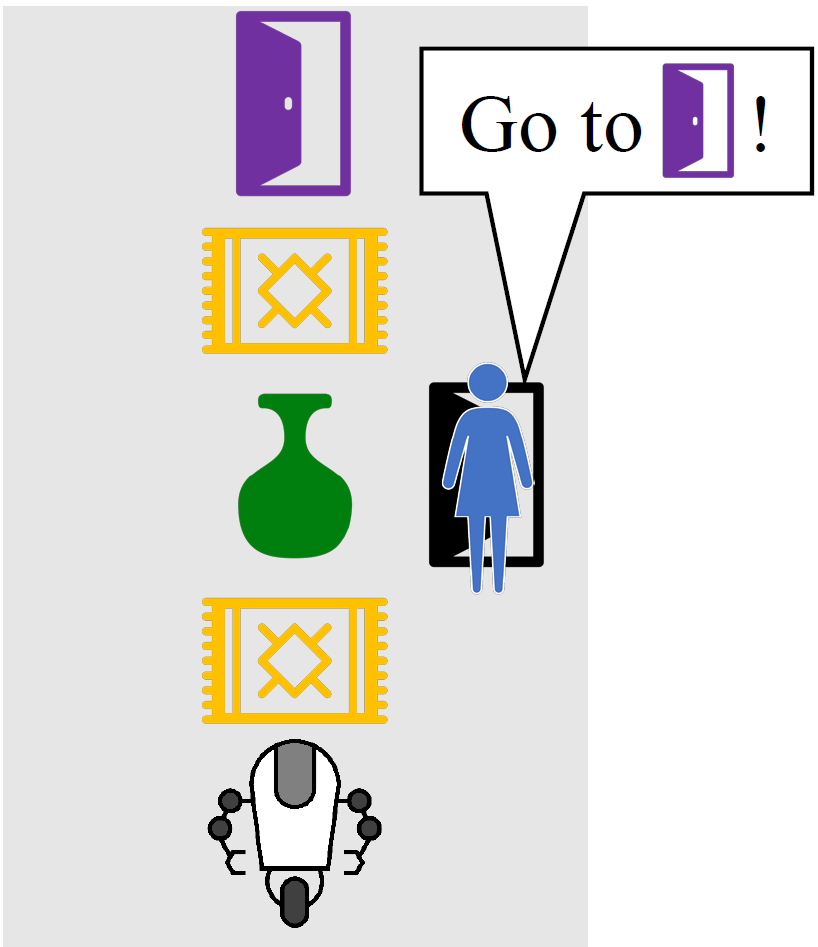
在这个环境中,它是否帮助我们意识到Alice正在为她的偏好优化房间的状态?好吧,如果Alice不在乎花瓶是否碎了,她过去可能会打碎它的。如果她想把花瓶打碎,她过去肯定会打碎的。所以唯一一致的解释是Alice关心花瓶完好无损,如下面的gif图片所示。

在这个例子中,机器人推断出它不应该做出打碎花瓶的动作,但是机器人也可以推断出它应该积极追求的目标。例如,如果机器人在一棵苹果树附近观察到一篮子苹果,它可以合理地推断出Alice想要收获苹果,因为苹果本身并没有走到篮子里——Alice一定是花了很大的力气去摘苹果并把它们放在篮子里。
通过模拟过去来奖励学习
我们通过考虑机器人在部署时观察初始状态s0的MDP,并假设这是人类对T时间步长进行未知奖励优化的结果,从而使这个想法正式化。
在我们开始真正的算法之前,考虑一个完全棘手的算法,它应该会做得很好:对于每个可能的奖励函数,模拟Alice在得到奖励时的轨迹,看看结果状态是否与s0兼容。这组相容的奖励函数给出了Alice奖励函数的候选值。这是我们在上面的gif中隐式使用的算法。
直观地说,这是因为:
对Alice来说,任何需要付出努力的事情(比如保持花瓶完好无损)在绝大多数奖励功能中都不会发生,而是会迫使奖励功能去激励这种行为(比如奖励完好无损的花瓶)。
对于Alice来说,任何不需要付出努力的事情(例如,一个花瓶变得满是灰尘)都会发生在大多数奖励函数中,因此推断出的奖励函数不需要激励那个行为(例如,满是灰尘/干净的花瓶没有特别的价值)。
另一种思考方法是我们可以考虑所有可能的过去轨迹它们都与s0相容,推断出使这些轨迹最有可能的奖励函数,并让这些奖励函数作为可能的候选,根据它们解释的过去轨迹的数量进行加权。出于类似的原因,这种算法应该也能工作。换句话说,听起来我们想用逆强化学习来推断过去可能的每条轨迹的回报,并将结果汇总起来。这仍然很难,但是我们可以利用这个观点,把它变成一个容易处理的算法。
我们遵循最大因果熵逆强化学习(MCEIRL),它是small MDPs的常用算法。在这个框架中,我们知道了MDP的动作空间和动态,以及状态的一组良好特征,在这些特征中假设奖励是线性的。此外,将人建模为Boltzmann-rational:假设Alice从给定状态采取特定操作的概率与状态操作值函数Q的指数成正比,该指数使用软值迭代计算。鉴于这些假设,我们可以计算p(τ∣θA),分布在可能的轨迹τ=s−Ta−T**…s−1a−1s0,在这种条件下Alice的奖励是θA。MCEIRL可以找到θA最大化的一组概率轨迹{τi}。
不用考虑所有可能的轨迹并在所有轨迹上运行MCEIRL来最大化它们各自的概率,相反,我们最大化我们看到的证据的概率:单一状态s0。为了得到s0上的分布,我们将机器人初始化前的人类行为边缘化: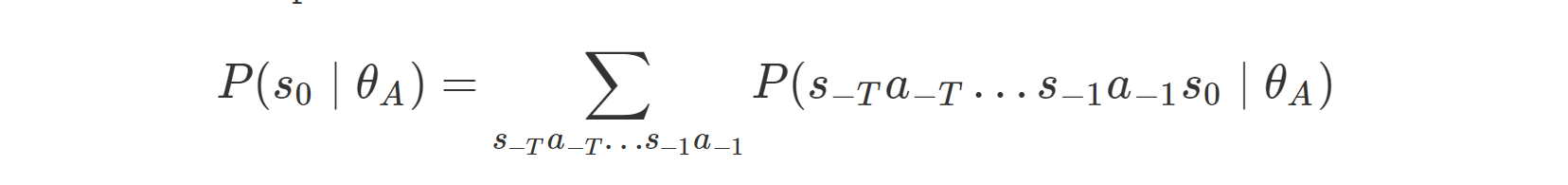
然后我们找一个奖励θA上面的可能性,来最大化使用梯度上升,使用动态编程来分析梯度的计算。我们称这种算法为“通过模拟过去来奖励学习(RLSP)”,因为它通过考虑过去发生的事情,从单一状态推断出未知的人类奖励。
使用推断的奖励
虽然RLSP推断出一种奖励,它可以捕捉初始状态中包含的关于人类偏好的信息,但我们不清楚该如何使用这种奖励。这是一个具有挑战性的问题,我们有两个的信息来源,s0的推断奖励,奖励θspec指定,它们会冲突。如果Alice有凌乱的房间,θA不会激励清洁,即使θspec可能。
理想情况下,我们应该注意两种奖励冲突的情况,并询问Alice希望如何进行。然而,在这项工作里,我们用简单启发式添加两个奖励,从而证明我们使用的算法,给我们一个最终的奖励θA +λθspec,λ是hyperparameter控制之间的权衡的回报。
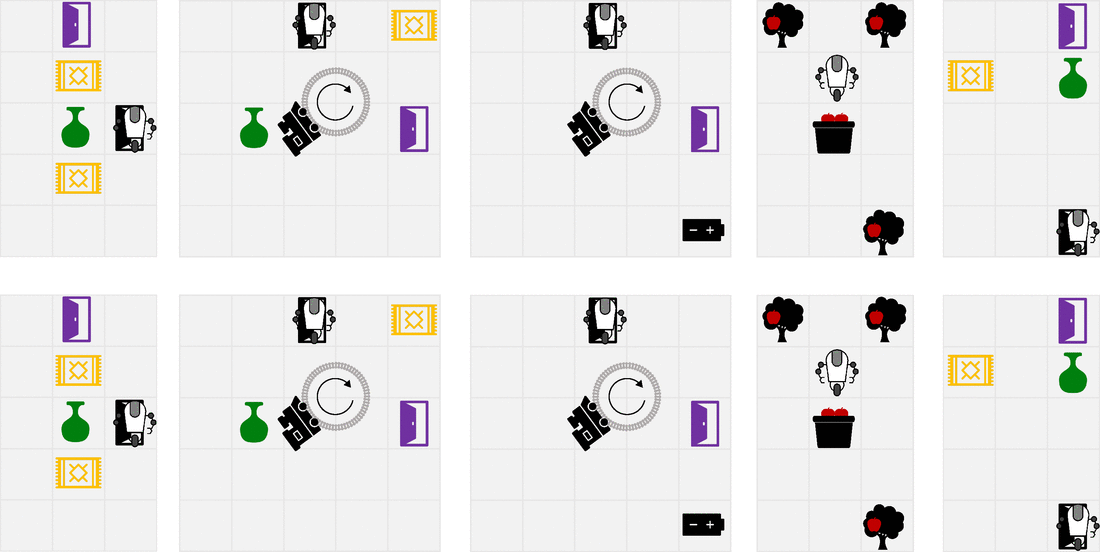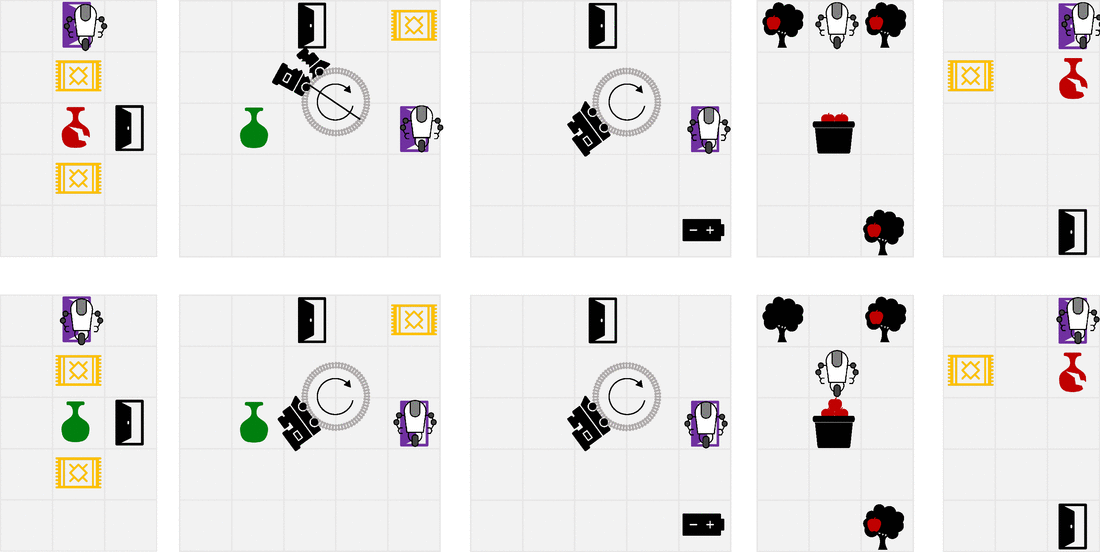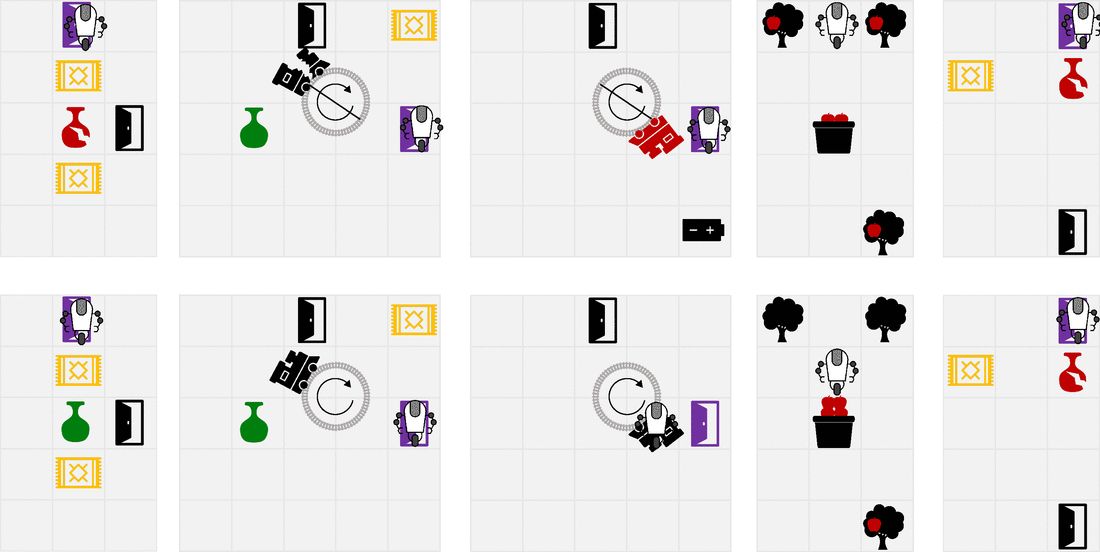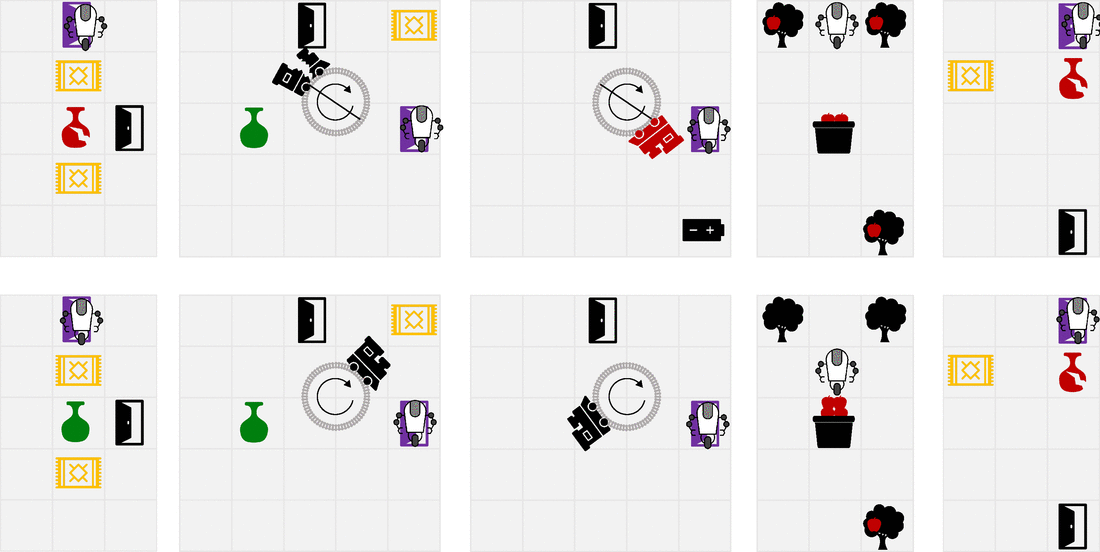
我们设计了一套简单的gridworlds来展示RLSP的属性。上面一行显示优化(不正确的)指定奖励时的行为,而下面一行显示在考虑RLSP推断的奖励时得到的行为。文中对各种环境作了较为详尽的描述。最后一个环境尤其显示了我们方法的局限性。在一个房间里,如果花瓶远离Alice最可能的轨迹,Alice可能打破花瓶的轨迹都很长,对RLSP概率的贡献很小。因此,观察完好无损的花瓶并不能告诉机器人Alice是否想主动避免打破花瓶,因为无论如何它都不太可能打破花瓶。
接下来是什么?
现在我们有了一个基本的算法,可以从一种状态了解人类的偏好,下一步自然是将其扩展到现实环境中,在这种环境中,状态无法枚举,动力学未知,奖励函数不是线性的。这可以通过调整现有的反向RL算法来实现,类似于我们如何将最大因果熵IRL调整到单状态设置。
在未知的动态环境中,我们不知道“世界是如何运转的”,这尤其具有挑战性。我们的算法很大程度上依赖于这样一个假设:我们的机器人知道世界是如何运转的——这就是为什么它能够模拟Alice过去“必须做的”事情。我们当然不能仅仅通过观察世界的单一状态来了解世界是如何运作的,所以我们必须在行动的同时学习一个动态模型,然后可以用来模拟过去(随着模型变得更好,这些模拟将会变得更好)。
未来工作的另一个方法是分解推断奖励为θA,task的调查方法,它表明Alice的哪个任务是正在执行的任务(“去黑门”),θframe捕捉到哪些任务Alice喜欢保持不变(“别打破那个花瓶”)。鉴于独立θframe,机器人可以优化θspec +θframe和忽略部分Alice正在执行的任务奖励函数。
因为θframe很大程度上是让许多人共享,我们可以推断出它使用的模型在多个人类优化自己的独特θH,task,但θframe相同,或者我们可以随时间改变一个人的任务。另一个方向是为Alice希望保持不变的内容(比如约束)假设一个不同的结构,并分别学习它们。
你可以通过阅读我们的论文或查看我们在ICLR 2019年的海报了解更多关于这项研究。代码在这里可用。
参考链接:
https://bair.berkeley.edu/blog/2019/02/11/learning_preferences

这篇关于伯克利最新研究成果:让机器人比你还了解自己的偏好的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





