本文主要是介绍Activiti6工作流引擎:Form表单,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
表单约等于流程变量。StartEvent 有一个Form属性,用于关联流程中涉及到的业务数据。
一:内置表单
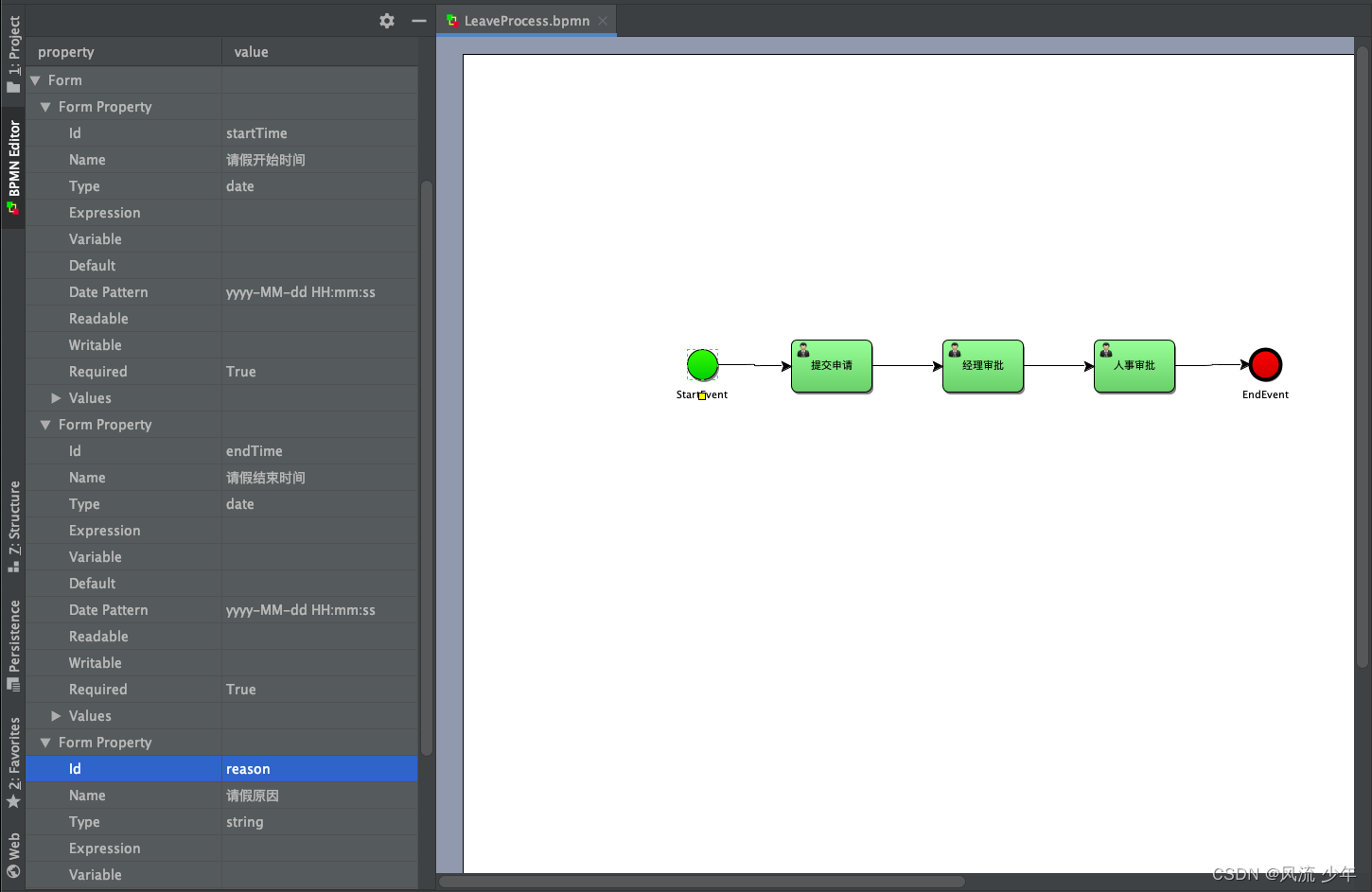
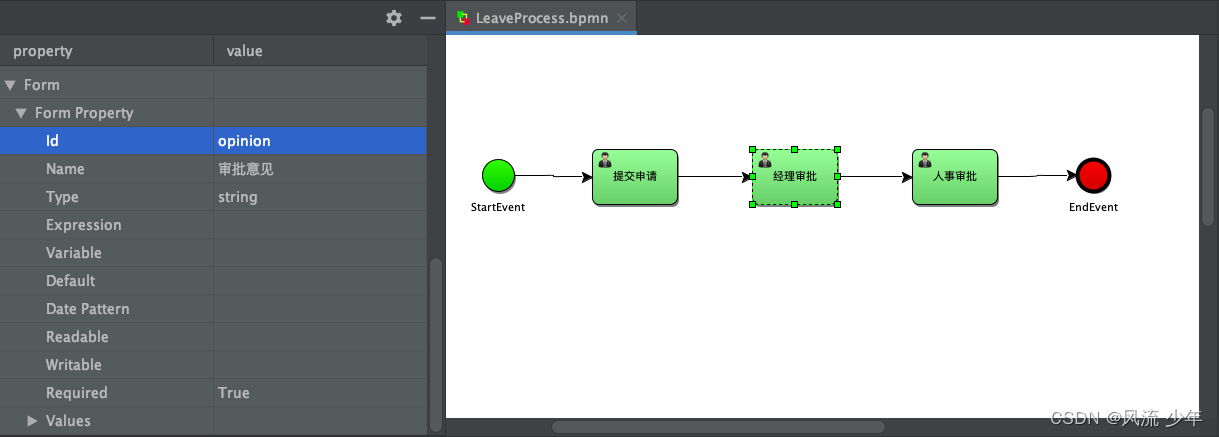
每个节点都可以有不同的表单属性。
1.1 获取开始节点对应的表单
@Autowired
private FormService formService;@Test
void delopyProcess() {ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();Deployment deploy = processEngine.getRepositoryService().createDeployment().addClasspathResource("processes/LeaveProcess.bpmn").name("表单请假流程").deploy();
}@Test
void getStartFormData() {String processDefinitionId = "LeaveProcess:1:7504";StartFormData startFormData = formService.getStartFormData(processDefinitionId);List<FormProperty> formProperties = startFormData.getFormProperties();for (FormProperty formProperty : formProperties) {System.out.println(formProperty.getId() + ":" + formProperty.getType() + " "+ formProperty.getName() + ":" + formProperty.getValue());}
}

1.2 启动流程实例
@Test
void startProcess() {// 传统方式Map<String, Object> variables = new HashMap<>();variables.put("startTime", "2023-11-11 09:00:00");variables.put("endTime", "2024-11-11 09:00:00");variables.put("reason", "世界那么大,我想去看看");runtimeService.startProcessInstanceByKey("LeaveProcess", variables);
}@Test
void startProcess2() {// 表单方式,都是保存到ACT_RU_VARIABLE,不同的是对于对变量的数据类型的处理。// form表单对应的变量都是String类型,并且日期会作为long类型存储。Map<String, String> variables = new HashMap<>();variables.put("startTime", "2022-11-11 09:00:00");variables.put("endTime", "2023-11-10 09:00:00");variables.put("reason", "活着不是为了工作,工作是为了活得更有意义");formService.submitStartFormData("LeaveProcess:1:7504", variables);
}


二:外部表单
这篇关于Activiti6工作流引擎:Form表单的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





