本文主要是介绍Leo赠书活动-06期 【强化学习:原理与Python实战】文末送书,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉
🍎个人主页:Leo的博客
💞当前专栏: 赠书活动专栏
✨特色专栏: MySQL学习
🥭本文内容: Leo赠书活动-06期 【强化学习:原理与Python实战】文末送书
🖥️个人小站 :个人博客,欢迎大家访问
📚个人知识库: 知识库,欢迎大家访问
目录
- 1.前言
- 2.时间旅行和平行宇宙
- 3.强化学习
- 4.策略梯度算法
- 5.代码示例
- 6.🥇赠书活动规则
1.前言
时间循环是一类热门的影视题材,其设定常常如下:主人公可以主动或被动的回到过去。与此同时,主人公会希望利用这样的机会改变在之前的经历中不完美的结果。为此,主人公调整自己的行为,使得结果发生变化。

一些和时间循环有关的电影
例如,时间循环电影开山之作《土拨鼠之日》(Groundhog Day)讲述了男主被困在土拨鼠日(2月2日)这一天,在日复一日的重复中不断调整自己的行为,终于成功追求到心爱的女主角并跳出时间循环。
试想,如果你是落入时间循环的主角,那应该如何决策才能趋利避害呢?
2.时间旅行和平行宇宙
在讨论决策的方法之前,首先要指出,只有在某些时间旅行设定下,才可能发挥主观能动性趋利避害。
时间旅行的设定要从时间悖论谈起。时间悖论是指由于时间旅行而引发的悖论。下面来看一个时间悖论的例子:我网购了一箱盲盒希望能抽到值钱的限量款。但是我收到盲盒并拆开后发现里面都是不值钱的普通款,并没有值钱的限量款。这时候我就可以考虑时间旅行,告诉过去的自己说别买盲盒,因为我抽不到限量款。然后过去的我听从了我的建议,导致我没有买盲盒。这就引发了悖论:我既然没有买盲盒,怎么知道我如果买了盲盒抽不到限量款?我既然不知道我买了盲盒也抽不到限量款,我怎么会告诉过去的自己这个事情?这里就有矛盾。

时间旅行引发的悖论
对于这样的时间悖论,有以下几种常见解释:
- 时间不可逆。这种解释认为,时间维度和其他空间维度不同,它是不对称的、不可逆的。所以,时间旅行不存在。这种解释否认了时空旅行的存在性,悖论就不可能发生。
- 命定悖论:命定悖论不是一个悖论,而是对时间悖论的解释。这种解释认为,时间旅行不能改变结果,所有的结果都是“命中注定的”,是已经考虑了时间旅行后的综合结果。例如,在盲盒的例子中,我是否买盲盒,已经是考虑了时间旅行的结果。即使未来的我告诉过去的我不要买盲盒,过去的我依然会固执地买了盲盒,最终知道盲盒里没有限量款。
- 平行宇宙:这种解释认为,时间旅行者进行时间旅行时,并不是到旅行到其原来所在的宇宙,而是旅行到其他宇宙(称为“平行宇宙”)。原来宇宙中的结果不会改变,改变的只可能是其他平行宇宙中的结果。比如在盲盒的例子中,拆了盲盒的我所在的宇宙中我依然还是买了盲盒、拆了盲盒,而我是告诉另外一个宇宙的自己不要买盲盒,所以另外一个宇宙中的自己并没有买盲盒、拆盲盒。
不同的时间悖论解释对应着不同的设定。在不同的设定下我们的能做的也不相同。
在时间不可逆的设定中,时间循环不存在,所以没啥可研究的。
在命定悖论的设定中,一切都是命中注定的,一切事情是你已经发挥了主观能动性的结果,不可能存在其他不同的结果。
在平行宇宙设定中,虽然不能改变当前宇宙中的结果,但是有希望在其他宇宙中获得更好的结果,这才是值得我们讨论的设定。
3.强化学习
那么在平行宇宙的设定下,我们应该怎样决策才能趋利避害呢?学术界对此已经有了完美的解决方案,那就是强化学习。
强化学习的通常设定如下:在系统里有智能体和环境,智能体可以观察环境、做出动作决策,环境会在动作决策的影响下演化,并且会给出奖励信号来指示智能体的成功程度。智能体希望得到的总奖励信号尽可能多。
智能体可以一遍又一遍的和环境交互。每一轮序贯交互称为一个回合。智能体可以和环境一个回合又一个回合的交互,并在交互过程中学习并改进自己的策略。我们可以把一个训练回合看作在一个宇宙内,通过在多个宇宙的训练结果,让自己在后续宇宙中的结果更优。
强化学习有很多算法,下面我们来介绍其中的一种比较简单的算法——策略梯度算法。
4.策略梯度算法
强化学习有很多算法,下面我们来介绍一个比较简单的算法——策略梯度算法(Vanilla Policy Gradient,VPG)。
策略梯度算法把智能体的策略建模为带参数的概率分布,记为。其中,是可以调节的策略参数,是环境在时刻的状态,是可以直接观察到的;是一个概率分布。是智能体观察到状态后选择的动作:采用策略参数的情况下,在处做出动作的概率是。不同的策略参数对应者不同的策略。在每个回合中,得到的回合总奖励为。策略梯度算法通过修改策略参数,使得回合总奖励的期望尽可能大。
为了让回合总奖励的期望尽可能大,策略梯度算法试图通过修改策略参数来增大,以达到增大的目的。这个算法的步骤如下图所示。

为什么增大就能增大回报期望呢?我们可以这样想:在采用策略参数的情况下,在状态处做出动作的概率是。如果我们把这个概率值称为决策部分的似然值,那么决策部分的对数似然值就是。那么在整个回合中所有的动作做出所有的概率就是,或者说决策部分的对数似然值是。如果这回合的回报好,即比较大(比如是很大的正值),那么我们会希望以后更常出现这样的决策,就会希望增大对数似然值。如果这回合的回报差,即比较小(比如是绝对值很大的负值),那么我们会希望以后不要再出现这样的决策,就会希望减小对数似然值。
所以,我们可以把作为加权的权重,试图增大就有机会增加回报期望。
当然,上述解释并不是非常严格的数学证明。按照强化学习的理论,其理论基础是策略梯度定理,有兴趣的读者可以看《强化学习:原理与Python实战》查阅其定理的内容、证明和解释。
5.代码示例
现在我们来通过一个代码案例,演示策略梯度算法的使用。
为了简单,我们选择了一个简单的环境:车杆平衡(CartPole-v0)。
车杆平衡问题由强化学习大师级人物Andrew Barto等人在1983年的论文《Neuronlike adaptive elements that can solve difficult learning control problem》里提出后,大量的研究人员对该环境进行了研究、大量强化学习教程收录了该环境,使得该环境成为最著名的强化学习环境之一。
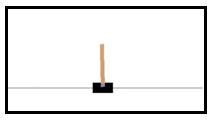
车杆平衡CartPole问题(图片来源:https://gym.openai.com/envs/CartPole-v0/)
车杆平衡问题如图,一个小车(cart)可以在直线滑轨上移动。一个杆(pole)一头连着小车,另一头悬空,可以不完全直立。小车的初始位置和杆的初始角度等是在一定范围内随机选取的。智能体可以控制小车沿着滑轨左移或是右移。出现以下情形中的任一情形时,回合结束:
- 杆的倾斜角度超过12度;
- 小车移动超过2.4个单位长度;
- 回合步数达到回合最大步数。
每进行1步得到1个单位的奖励。我们希望回合能够尽量的长。
任务CartPole-v0回合最大步数为200。
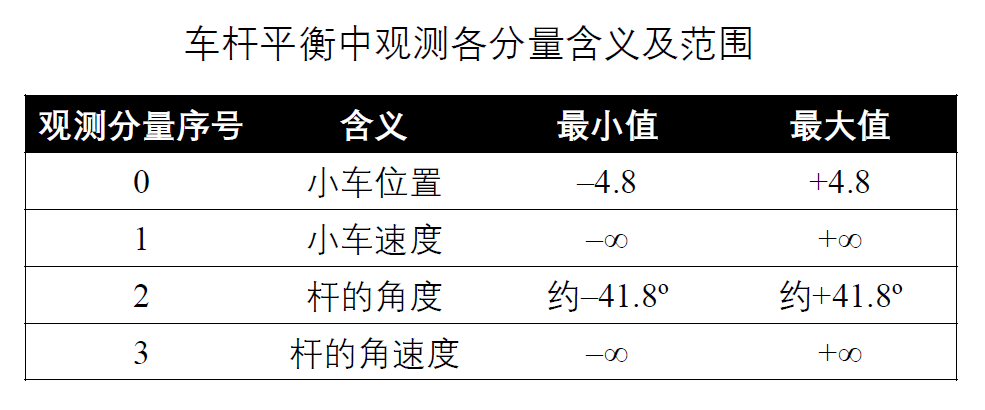
这个问题中,观察值有4个分量,分别表示小车位置、小车速度、木棒角度和木棒角速度,其取值范围如表所示。动作则取自{0,1},分别表示向左施力和向右施力。
用法:想要用这个环境,需要先安装Python库Gym。安装Gym库的方法可以参见
https://github.com/ZhiqingXiao/rl-book/blob/master/zh2023/setup/setupwin.md
安装好Gym库后,可以用下列代码导入环境。
代码 导入环境
import gym
env = gym.make("CartPole-v0")
在实现智能体之前,我们先来实现智能体和环境的交互函数。函数play_episode()让智能体和环境交互一个回合。这个函数有三个参数:
- 环境对象env:它可以通过gym.make(“CartPole-v0”)直接获得。
- 智能体对象agent:我们一会儿要实现智能体类,它就是智能体类的对象。这个智能体需要实现一些成员,包括agent.reset(mode)、agent.step(observation, reward, terminated)、agent.close()。后文会介绍如何实现这些成员。
- 模式参数mode:字符串类型,可以是’train’和’test’。这个参数会进一步传到agent.reset(mode)中。如果是’train’那么智能体会处于训练模式,会更新参数;如果是’test‘则智能体会处于训练模式。
在函数内部,先初始化环境和智能体。然后环境和智能体不断交互,直到回合结束或截断(截断指达到了回合最大的步数)。然后返回回合步数和回合总奖励。
代码 智能体和环境交互一个回合。
def play_episode(env, agent, mode=None):# 初始化observation, _ = env.reset()reward, terminated, truncated = 0., False, Falseagent.reset(mode=mode)episode_reward, elapsed_steps = 0., 0# 交互whileTrue:action = agent.step(observation, reward, terminated)if terminated or truncated:breakobservation, reward, terminated, truncated, _ = env.step(action)episode_reward += rewardelapsed_steps += 1# 结束agent.close()return episode_reward, elapsed_steps
接下来我们来看智能体类VPGAgent类。
这个类的实现用到了PyTorch库。之所以使用PyTorch,是因为算法要更新以增大,而这样的优化问题可以借助PyTorch来实现。我们可以用PyTorch搭建出以为可训练变量的表达式(即损失函数),用优化器来最小化。
除了基于PyTorch实现外,也可以基于TensorFlow来实现对应的功能。文末既给出了两套代码的链接,一套基于PyTorch,另一套基于TensorFlow,你可以任选一个。这两套代码都收录在了书籍《强化学习:原理与Python实现》中。
我们来看看基于PyTorch的类VPGAgent的详细实现。它的构造函数__init__(self, env)准备了策略函数self.policy_net是Softmax激活的线性层,指定了优化器为Adam优化器。初始化函数reset(self, mode)在训练模式下,准备好存储轨迹的列表self.trajectory,以便于后续交互时存储轨迹。交互函数step(self, observation, reward, terminated)根据观测给出动作概率,并且训练模式下存储交互记录到self.trajectory中。结束函数close(self)在训练模式下调用学习函数learn(self)。学习函数learn(self)利用self.trajectory中存储的记录进行训练:先得到得到状态张量state_tensor、动作张量action_tensor和回合奖励张量return_tensor。再利用状态张量和动作张量计算对数概率。在计算对数概率时,使用了torch.clamp()函数限制数值范围,以提升数值稳定性。利用回合奖励张量和对数概率张量进而计算得到损失张量loss_tensor,最后用优化器optimizer减小损失。
代码 智能体
import torch
import torch.distributions as distributions
import torch.nn as nn
import torch.optim as optimclass VPGAgent:def __init__(self, env):self.action_n = env.action_space.nself.policy_net = nn.Sequential(nn.Linear(env.observation_space.shape[0], self.action_n, bias=False),nn.Softmax(1))self.optimizer = optim.Adam(self.policy_net.parameters(), lr=0.005)def reset(self, mode=None):self.mode = modeif self.mode == 'train':self.trajectory = []def step(self, observation, reward, terminated):state_tensor = torch.as_tensor(observation, dtype=torch.float).unsqueeze(0)prob_tensor = self.policy_net(state_tensor)action_tensor = distributions.Categorical(prob_tensor).sample()action = action_tensor.numpy()[0]if self.mode == 'train':self.trajectory += [observation, reward, terminated, action]return actiondef close(self):if self.mode == 'train':self.learn()def learn(self):state_tensor = torch.as_tensor(self.trajectory[0::4], dtype=torch.float)action_tensor = torch.as_tensor(self.trajectory[3::4], dtype=torch.long)return_tensor = torch.as_tensor(sum(self.trajectory[1::4]), dtype=torch.float)all_pi_tensor = self.policy_net(state_tensor)pi_tensor = torch.gather(all_pi_tensor, 1, action_tensor.unsqueeze(1)).squeeze(1)log_pi_tensor = torch.log(torch.clamp(pi_tensor, 1e-6, 1.))loss_tensor = -(return_tensor * log_pi_tensor).mean()self.optimizer.zero_grad()loss_tensor.backward()self.optimizer.step()agent = VPGAgent(env)
这样我们就实现了智能体。接下来,我们进行训练和测试。为了完整性,在此附上训练和测试的代码。训练的代码不断进行回合,直到最新的几个回合总奖励的平均值超过某个阈值。测试的代码则是交互100个回合求平均。
代码 智能体和环境交互多个回合以训练智能体
import itertools
import numpy as npepisode_rewards = []
for episode in itertools.count():episode_reward, elapsed_steps = play_episode(env, agent, mode='train')episode_rewards.append(episode_reward)logging.info('训练回合 %d: 奖励 = %.2f, 步数 = %d',episode, episode_reward, elapsed_steps)if np.mean(episode_rewards[-20:]) > env.spec.reward_threshold:break
plt.plot(episode_rewards)
代码 智能体与环境交互100回合来测试智能体性能
episode_rewards = []
for episode in range(100):episode_reward, elapsed_steps = play_episode(env, agent)episode_rewards.append(episode_reward)logging.info('测试回合%d:奖励 = %.2f,步数 = %d',episode, episode_reward, elapsed_steps)
logging.info('平均回合奖励 = %.2f ± %.2f',np.mean(episode_rewards), np.std(episode_rewards))
完整的代码和运行结果参见:
- PyTorch版本:
https://zhiqingxiao.github.io/rl-book/en2023/code/CartPole-v0_VPG_torch.html - TensorFlow版本:
https://zhiqingxiao.github.io/rl-book/en2023/code/CartPole-v0_VPG_tf.html
通过这篇文章,我们了解时间循环中可能的几种设定,并了解了在平行宇宙设定下可以使用强化学习来改进决策。最后,我们还通过一个编程小例子了解策略梯度算法。
推荐阅读

*《强化学习:原理与Python实战》*
揭密ChatGPT关键技术PPO和RLHF
理论完备:
涵盖强化学习主干理论和常见算法,带你参透ChatGPT技术要点;
实战性强:
每章都有编程案例,深度强化学习算法提供TenorFlow和PyTorch对照实现;
配套丰富:
逐章提供知识点总结,章后习题形式丰富多样。还有Gym源码解读、开发环境搭建指南、习题答案等在线资源助力自学。
6.🥇赠书活动规则
🌟关注我的博客:关注我的博客,所有新鲜的博客文章和活动信息都不会错过。
📲添加博主wx:添加Leocisyam,如果添加不了,请私信博主。
💬参与方式:关注公众号程序员Leo或者文末扫码关注,回复抽奖,即可参与抽奖。
🎁公布结果:2023年11月13日晚,我会亲自抽取4️⃣名幸运读者,并在微信私信通知,请大家注意查收哈。
这篇关于Leo赠书活动-06期 【强化学习:原理与Python实战】文末送书的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





