本文主要是介绍5-爬虫-打码平台、打码平台自动登录打码平台、selenium爬取京东商品信息、scrapy介绍安装、scrapy目录结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 打码平台
1.1 案例
2 打码平台自动登录打码平台
3 selenium爬取京东商品信息
4 scrapy介绍安装
5 scrapy目录结构
1 打码平台
# 1 登录某些网站,会有验证码---》想自动破解-数字字母:python模块:ddddocr-计算题,成语题,滑块...:第三方打码平台,人工操作# 2 打码平台-云打码,超级鹰# 3 咱们破解网站登录的思路-使用selenium----》打开网站----》(不能解析出验证码地址)---》使用截图
1.1 超级鹰案例
import requests
from hashlib import md5class ChaojiyingClient(object):def __init__(self, username, password, soft_id):self.username = usernamepassword = password.encode('utf8')self.password = md5(password).hexdigest()self.soft_id = soft_idself.base_params = {'user': self.username,'pass2': self.password,'softid': self.soft_id,}self.headers = {'Connection': 'Keep-Alive','User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',}def PostPic(self, im, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,}params.update(self.base_params)files = {'userfile': ('ccc.jpg', im)}r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,headers=self.headers)return r.json()def PostPic_base64(self, base64_str, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,'file_base64': base64_str}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)return r.json()def ReportError(self, im_id):"""im_id:报错题目的图片ID"""params = {'id': im_id,}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)return r.json()if __name__ == '__main__':chaojiying = ChaojiyingClient('超级鹰账号', '超级鹰账号的密码', '903641') # 用户中心>>软件ID 生成一个替换 96001im = open('a.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//print(chaojiying.PostPic(im, 1004)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()# print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码2 打码平台自动登录打码平台
import timefrom selenium import webdriver
from selenium.webdriver.common.by import By
from PIL import Image
from chaojiying import ChaojiyingClientbro = webdriver.Chrome()
bro.maximize_window()try:# 1 打开页面bro.get('https://www.chaojiying.com/user/login/')# 2 找到用户名,密码,验证码的输入框username = bro.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input')password = bro.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input')code = bro.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input')time.sleep(2)username.send_keys('账号')time.sleep(2)password.send_keys('密码')# 3 验证码破解---》网页屏幕截图---》根据验证码图片的位置和大小,从网页截图中扣出验证码图片---》调用超级鹰--》完成破解---》填入# 网页截图bro.save_screenshot('main.png')# 找到img的大小和位置img = bro.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/div/img')location = img.locationsize = img.sizeprint('大小是:', img.size)print('位置是:', img.location)# 获取图的 起始位置坐标 结束位置坐标img_tu = (int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height']))# 使用pillow截图# #打开img = Image.open('./main.png')# 抠图fram = img.crop(img_tu)# 截出来的小图fram.save('code.png')# 调用超级鹰--》完成破解chaojiying = ChaojiyingClient('超级鹰账号', '密码', '903641')im = open('code.png', 'rb').read()res = chaojiying.PostPic(im, 1902)if res.get('err_no') == 0:code_img_text = res.get('pic_str')# 写入到验证码中code.send_keys(code_img_text)time.sleep(3)submit = bro.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input')submit.click()time.sleep(5)except Exception as e:print(e)
finally:bro.close()3 selenium爬取京东商品信息
import time
import json
from selenium import webdriverbro = webdriver.Chrome()
bro.get('https://passport.jd.com/new/login.aspx?ReturnUrl=https%3A%2F%2Fwww.jd.com%2F')
bro.implicitly_wait(10)
bro.maximize_window()
input('需要手动扫码登录,登录成功后敲回车')cookies = bro.get_cookies()
with open('jd.json', 'w', encoding='utf-8') as f:json.dump(cookies, f)time.sleep(2)
bro.close()import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.chrome.options import Optionsdef get_goods(bro):# 往下滑动屏幕bro.execute_script('scrollTo(0,document.documentElement.scrollHeight-600)')# 来到了商品结果页面,找到页面中所有类名叫 gl-item 的lili_list = bro.find_elements(By.CLASS_NAME, 'gl-item')for li in li_list:try:name = li.find_element(By.CSS_SELECTOR, 'div.p-name em').textprice = li.find_element(By.CSS_SELECTOR, 'div.p-price i').texturl = li.find_element(By.CSS_SELECTOR, 'div.p-img>a').get_attribute('href')# 如果不滑动屏幕---》图片先放在 data-lazy-img属性中,只有滑动到底部,图片加载完,src才有值img = li.find_element(By.CSS_SELECTOR, 'div.p-img>a>img').get_attribute('src')shop_name = li.find_element(By.CSS_SELECTOR, 'div.p-shop a').textprint('''商品名字:%s商品价格:%s商品地址:%s图片:%s店铺名:%s''' % (name, price, url, img, shop_name))except Exception as e:print(e)continue# 当前页爬取完成,点击下一页next = bro.find_element(By.PARTIAL_LINK_TEXT, '下一页')next.click()time.sleep(30)get_goods(bro) # 递归调用自己---》 下一页会出现加载失败请情况----》一直在爬第一页options = Options()
options.add_argument("--disable-blink-features=AutomationControlled") # 去掉自动化控制
bro = webdriver.Chrome(options=options)
# bro = webdriver.Chrome()
bro.get('https://www.jd.com')
bro.implicitly_wait(10)
bro.maximize_window()
print('写入cookie')
with open('jd.json', 'r') as f:cookies = json.load(f)
# 写到浏览器中
for item in cookies:bro.add_cookie(item) # 如果是没登录的cookie,往里写会报错# 刷新浏览器bro.refresh()
time.sleep(1)
# 来到首页,找到搜索框
try:search = bro.find_element(By.ID, 'key')search.send_keys('卫生纸')time.sleep(2)# 敲回车search.send_keys(Keys.ENTER)# 获取商品信息get_goods(bro)except Exception as e:print(e)
finally:bro.close()4 scrapy介绍安装
# 爬虫模块:requests bs4 selenium # 爬虫框架---》不是模块---》类似于django---》爬虫界的django(跟djagno非常像)# 安装:pip3 install scrapy-mac,linux 非常好装-win:看人品:因为twisted装不上1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs3、pip3 install lxml4、pip3 install pyopenssl5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl8、pip3 install scrapy# 装完后----》scripts文件夹下就会有scrapy可执行文件---》类似于(django-admin.exe)-创建项目,创建爬虫都用它# 介绍
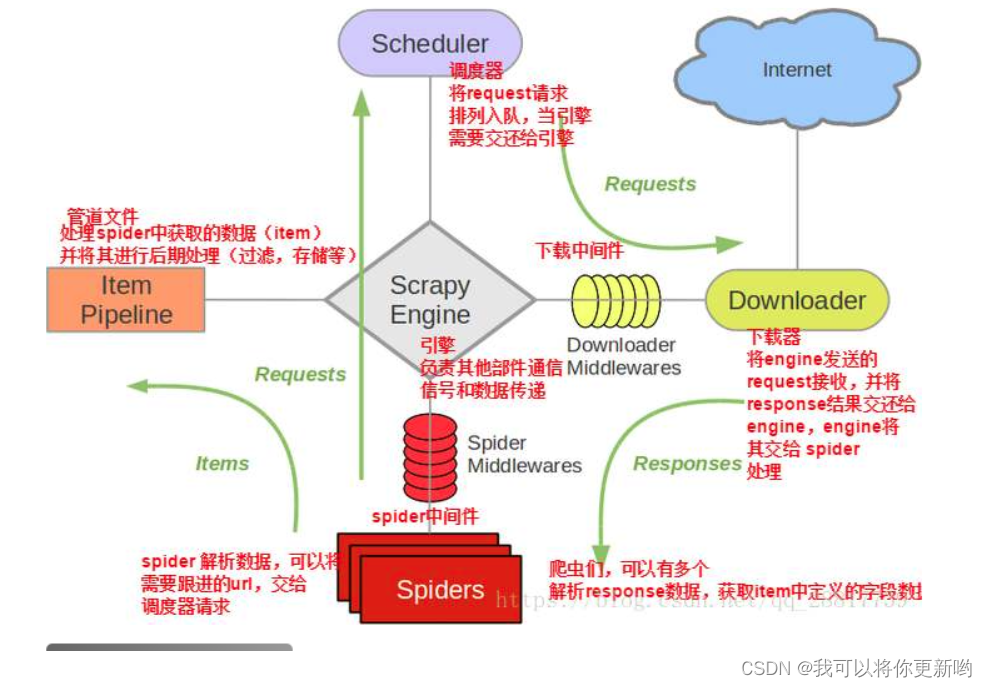
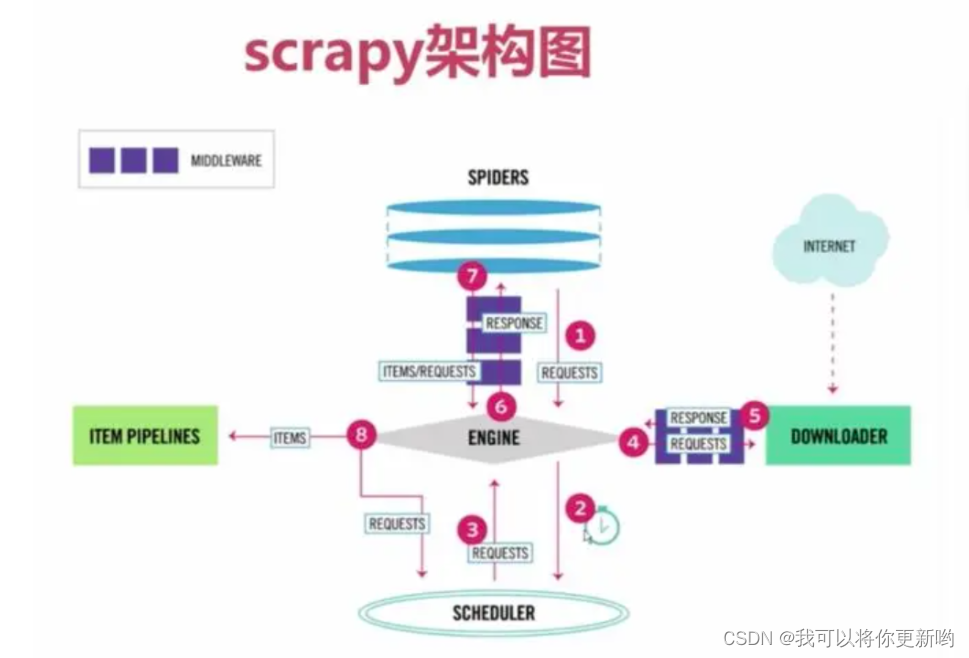
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据或者通用的网络爬虫。Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。整体架构大致如下## 架构# 1 爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
开发人员,主要在这写代码:设置爬取的地址,解析爬取完成的数据,继续爬取或者存储数据#2 引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件# 3 调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址# 4 下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的# 5 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作# 6 下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事# 7 爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
5 scrapy目录结构
# https://www.cnblogs.com/robots.txt 爬虫协议# 创建scrapy项目scrapy startproject scrapy_demo
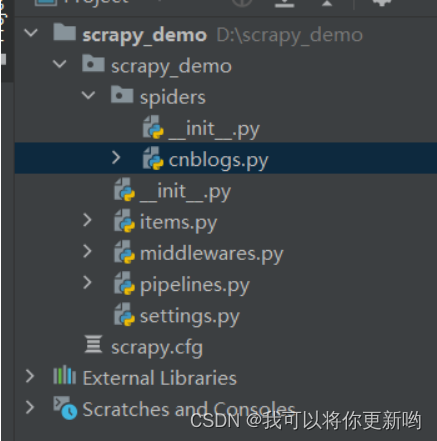
# 使用pycharm打开# 创建爬虫---》可以创建多个爬虫scrapy genspider 爬虫名 爬虫地址 # django创建appscrapy genspider cnblogs www.cnblogs.com # 创建了爬取cnblogs的爬虫# 运行爬虫:默认直接爬取www.cnblogs.com---》后续需要写代码实现scrapy crawl 爬虫名字scrapy crawl cnblogs # 目录结构scrapy_demo #项目名scrapy_demo #包__init__.pyspiders #包 ,所有爬虫文件,放在这里__init__.pycnblogs.pyitems.py # 一个个类,等同于djagno的modelspipelines.py # 写如何存储,存到拿settings.py# 配置文件middlewares.py # 中间件:两种scrapy.cfg # 上线用的
这篇关于5-爬虫-打码平台、打码平台自动登录打码平台、selenium爬取京东商品信息、scrapy介绍安装、scrapy目录结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








