本文主要是介绍2022最新版-李宏毅机器学习深度学习课程-P46 自监督学习Self-supervised Learning(BERT),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
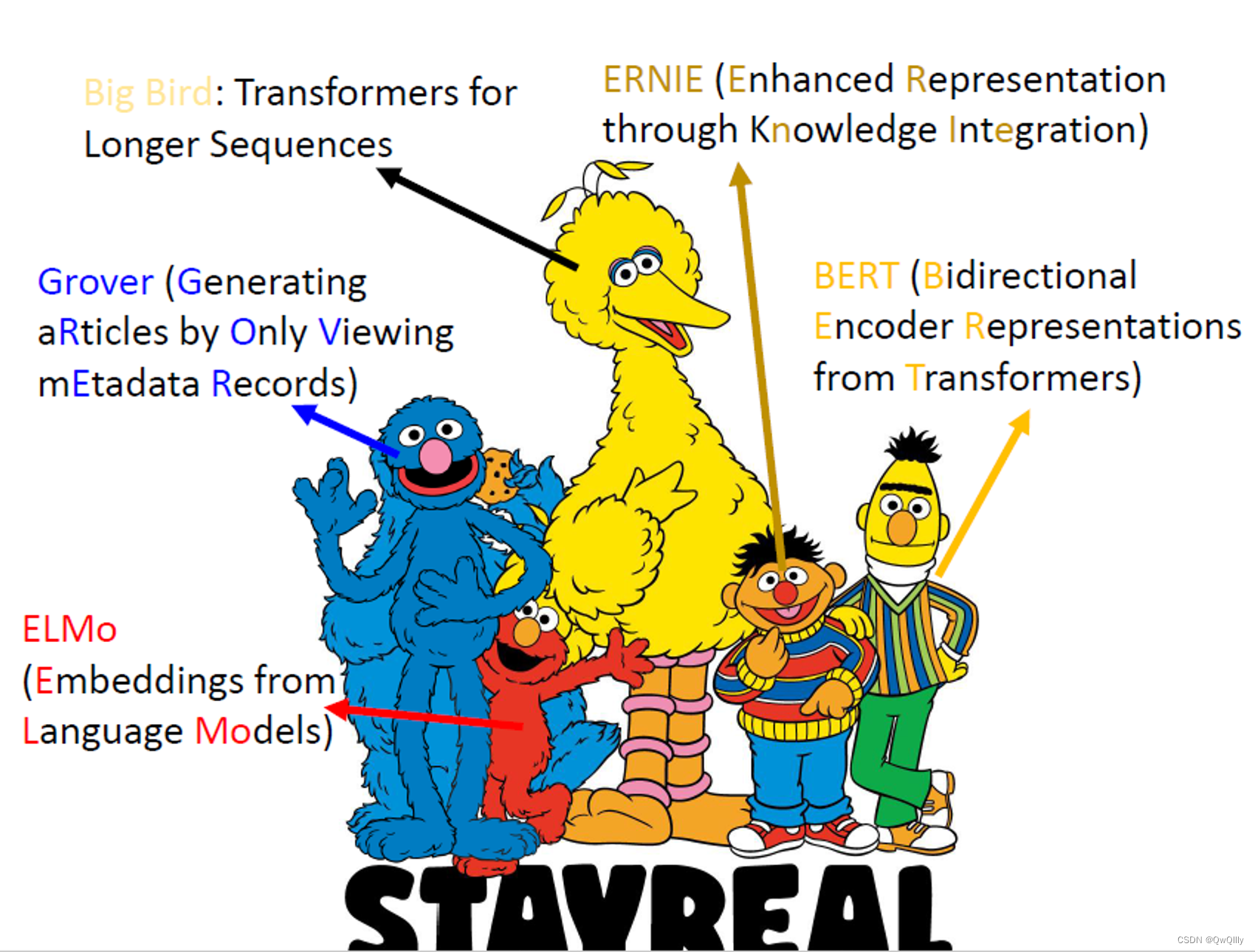
一、概述:自监督学习模型与芝麻街

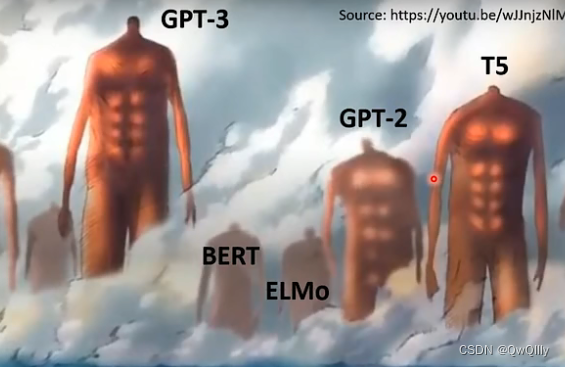
参数量
- ELMO:94M
- BERT:340M
- GPT-2:1542M
- Megatron:8B
- T5:11B
- Turing NLG:17B
- GPT-3:175B
- Switch Transformer:1.6T





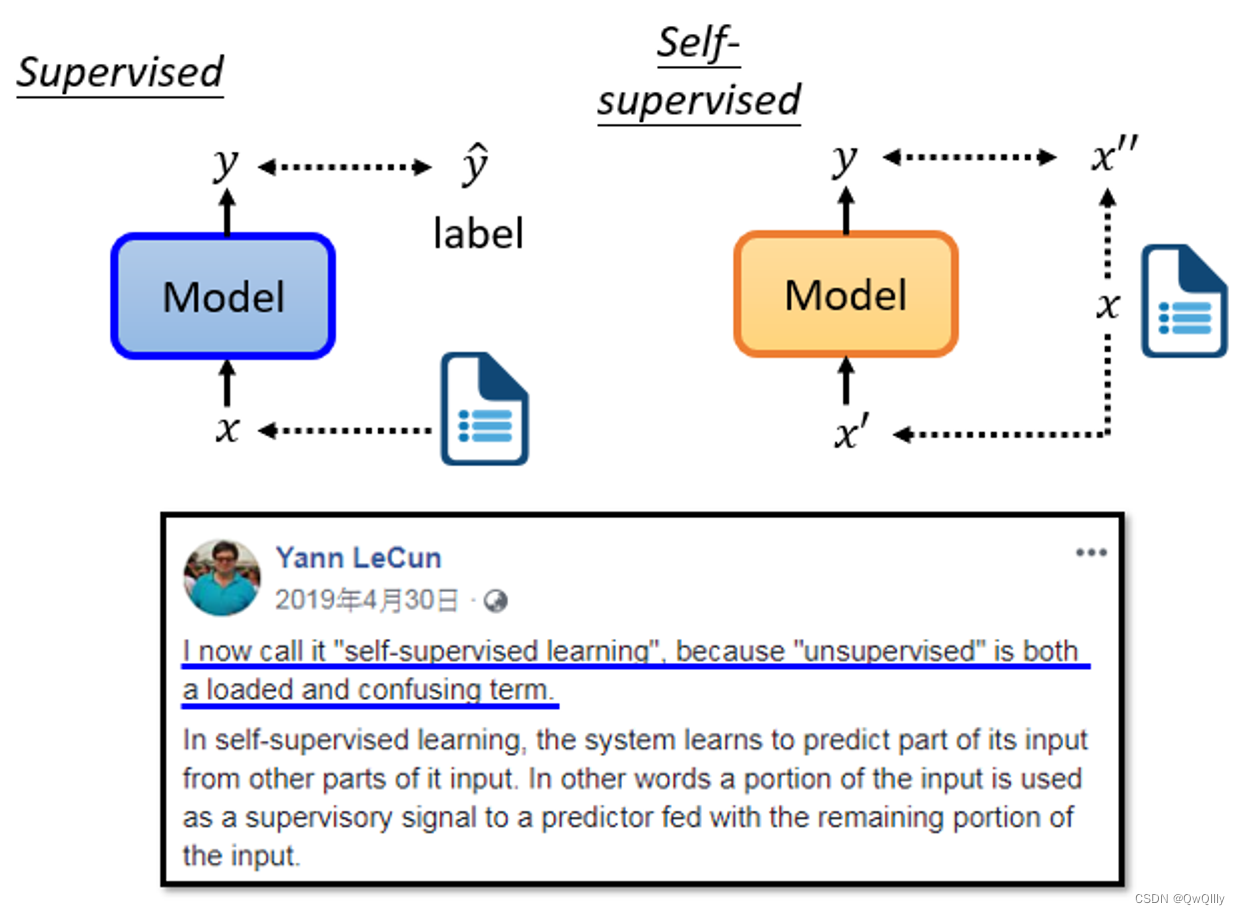
二、Self-supervised Learning⇒Unsupervised Learning的一种
“自监督学习”数据本身没有标签,所以属于无监督学习;但是训练过程中实际上“有标签”,标签是“自己生成的”。
想办法把训练数据分为“两部分”,一部分作为作为“输入数据、另一部分作为“标注”。
三、BERT
💡 作为transformer,理论上BERT的输入长度没有限制。但是为了避免过大的计算代价,在实践中并不能输入太长的序列。 事实上,在训练中,会将文章截成片段输入BERT进行训练,而不是使用整篇文章,避免距离过长的问题。
BERT是一个transformer的Encoder,BERT可以输入一行向量,然后输出另一行向量,输出的长度与输入的长度相同。BERT一般用于自然语言处理,一般来说,它的输入是一串文本。当然,也可以输入语音、图像等“序列”。
Masking Input
随机盖住一些输入的文字,被mask的部分是随机决定的。
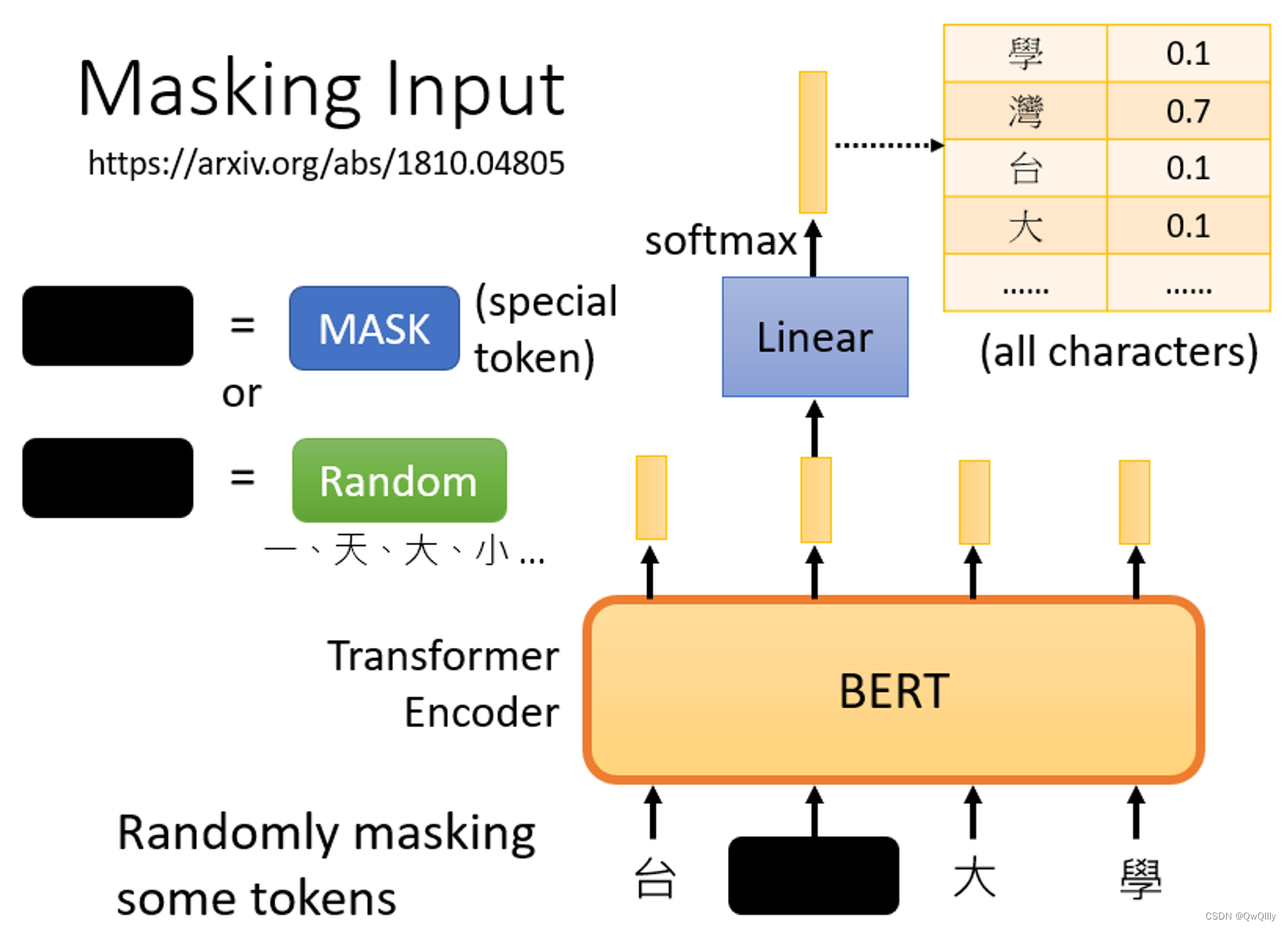
MASK的方法:
- 第一种方法是,用一个特殊的符号替换句子中的一个词,我们用 "MASK "标记来表示这个特殊符号,你可以把它看作一个新字,这个字完全是一个新词,它不在你的字典里,这意味着mask了原文。
- 另外一种方法,随机把某一个字换成另一个字。中文的 "湾"字被放在这里,然后你可以选择另一个中文字来替换它,它可以变成 "一 "字,变成 "天 "字,变成 "大 "字,或者变成 "小 "字,我们只是用随机选择的某个字来替换它
两种方法都可以使用,使用哪种方法也是随机决定的。
训练方法:
- 向BERT输入一个句子,先随机决定哪一部分的汉字将被mask。
- 输入一个序列,我们把BERT的相应输出看作是另一个序列
- 在输入序列中寻找mask部分的相应输出,将这个向量通过一个Linear transform(矩阵相乘),并做Softmax得到一个分布。
- 用一个one-hot vector来表示MASK的字符,并使输出和one-hot vector之间的交叉熵损失最小。
<aside> 💡 本质上,就是在解决一个分类问题。BERT要做的是预测什么被盖住。
</aside>
Next Sentence Prediction(不太有用)
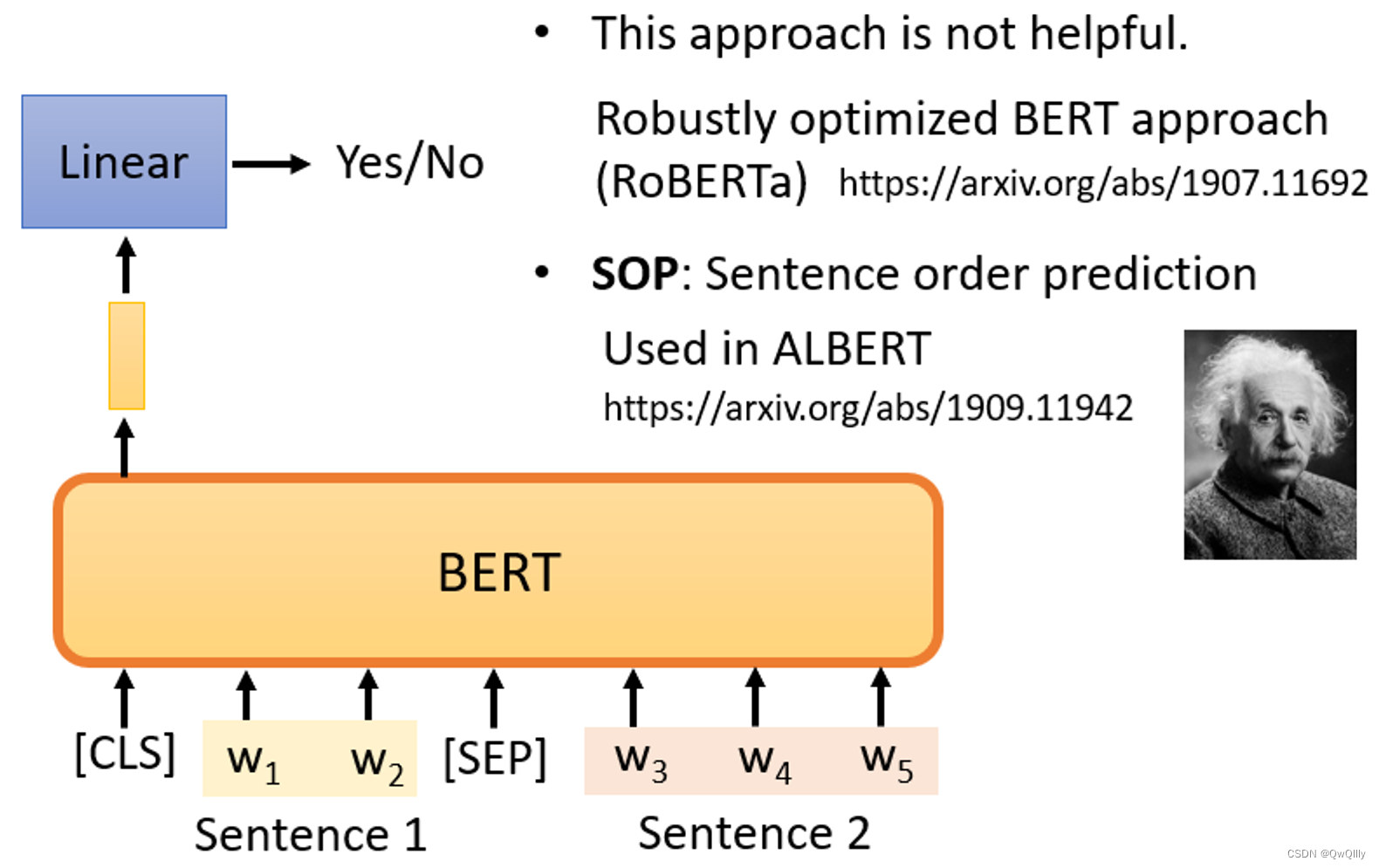
从数据库中拿出两个句子,两个句子之间添加一个特殊标记[SEP],在句子的开头添加一个特殊标记[cls]。这样,BERT就可以知道,这两个句子是不同的句子。
只看CLS的输出,我们将把它乘以一个Linear transform,做一个二分类问题,输出yes/no,预测两句是否前后连续。
没有用
Robustly Optimized BERT Approach(RoBERTa)
Sentence order prediction,SOP(句子顺序预测)⇒ALBERT
挑选的两个句子是相连的。可能有两种可能性供BERT猜测:
- 句子1在句子2后面相连,
- 句子2在句子1后面相连。
BERT的实际用途⇒下游任务(Downstream Tasks)
预训练与微调:
- 预训练:产生BERT的过程
- 微调:利用一些特别的信息,使BERT能够完成某种任务
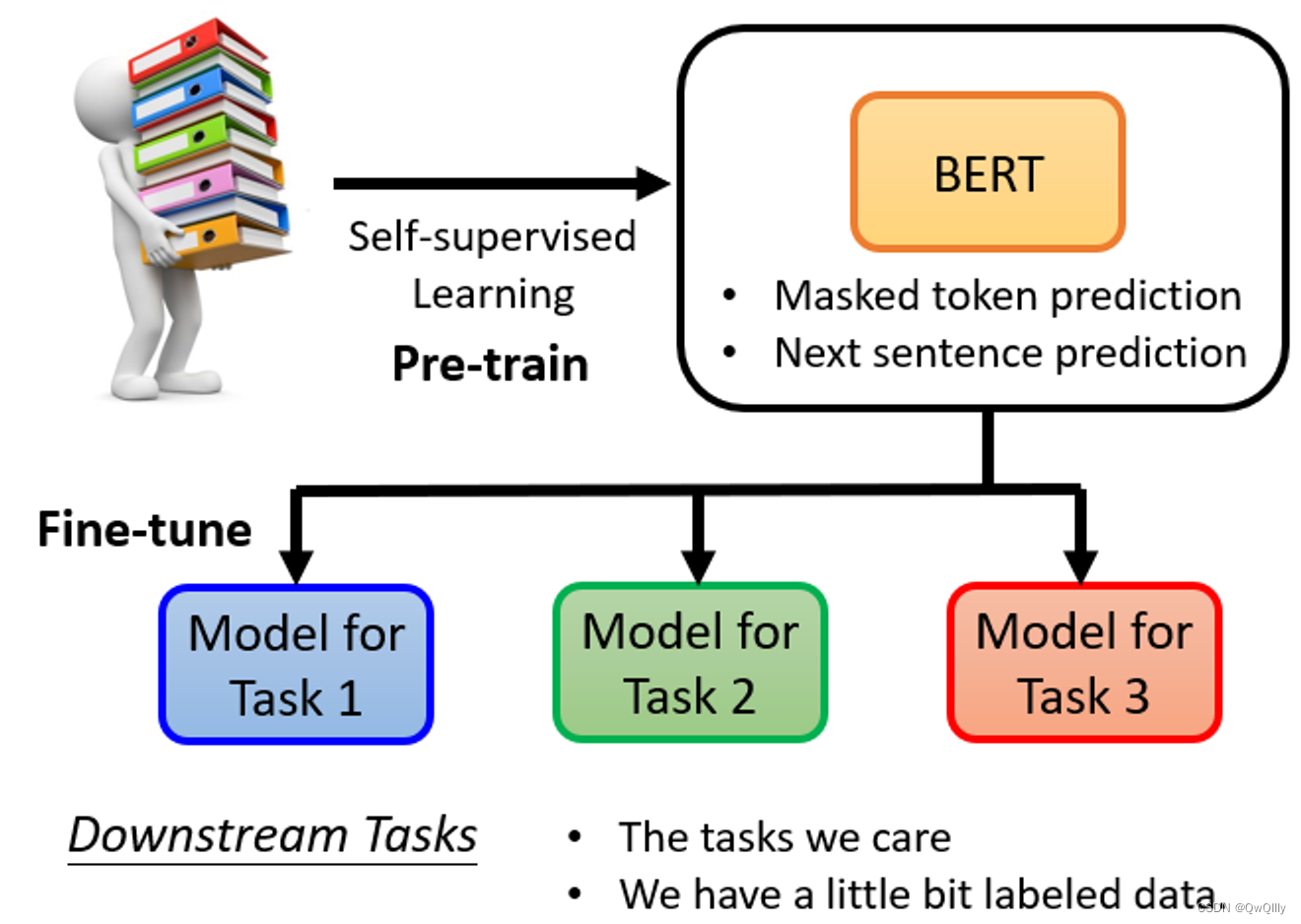
BERT只学习了两个“填空”任务。
- 一个是掩盖一些字符,然后要求它填补缺失的字符。
- 预测两个句子是否有顺序关系。
但是,BERT可以被应用在其他的任务【真正想要应用的任务】上,可能与“填空”并无关系甚至完全不同。【胚胎干细胞】当我们想让BERT学习做这些任务时,只需要一些标记的信息,就能够“激发潜能”。
对BERT的评价任务集——GLUE(General Language Understanding Evaluation)
为了测试Self-supervised学习的能力,通常,你会在一个任务集上测试它的准确性,取其平均值得到总分。

性能衡量:
人类的准确度是1,如果他们比人类好,这些点的值就会大于1。

这篇关于2022最新版-李宏毅机器学习深度学习课程-P46 自监督学习Self-supervised Learning(BERT)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



