本文主要是介绍RoBERTa极简简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RoBERTa模型是在BERT预训练模型的基础上改进了三点:
一、采用动态Masking机制,每次向模型输入一个序列时,都会生成一种新的遮盖方式
二、删除了Next Sentence Prediction(NSP)任务
三、增加了预训练过程的预料规模,扩大Batch Size的同时增加了训练时的步长
与BERT模型一致,RoBERTa模型同样使用多个双向Transformer模型的encoder部分堆叠组成主主体框架,能更彻底地捕捉文本中的双向关系
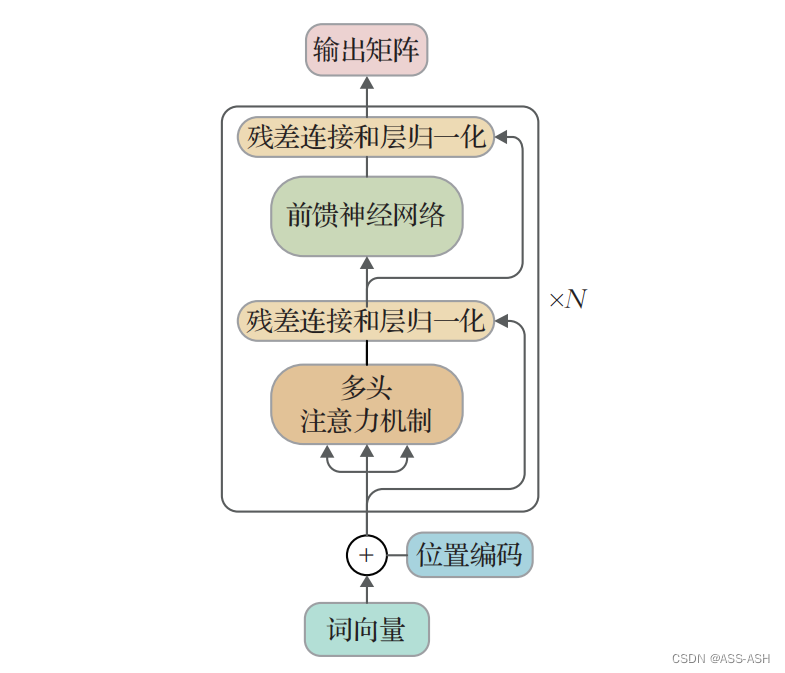
Transformer-encoder逻辑结构

残差连接网络结构
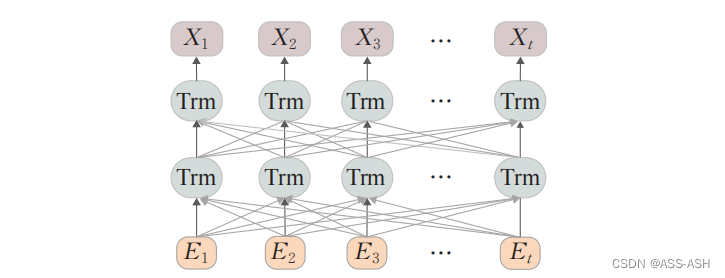
RoBERTa层逻辑结构图
这篇关于RoBERTa极简简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




