本文主要是介绍ElasticSearch7.3学习(二十六)----搜索(Search)参数总结、结果跳跃(bouncing results)问题解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、preference
首先引入一个bouncing results问题,两个document排序,field值相同;不同的shard上,可能排序不同;每次请求轮询打到不同的replica shard上;每次页面上看到的搜索结果的排序都不一样。这就是bouncing result,也就是跳跃的结果。
这个问题出现最多的地方就是timestamp进行排序,如下图所示,可能导致每次返回的结果不一致。
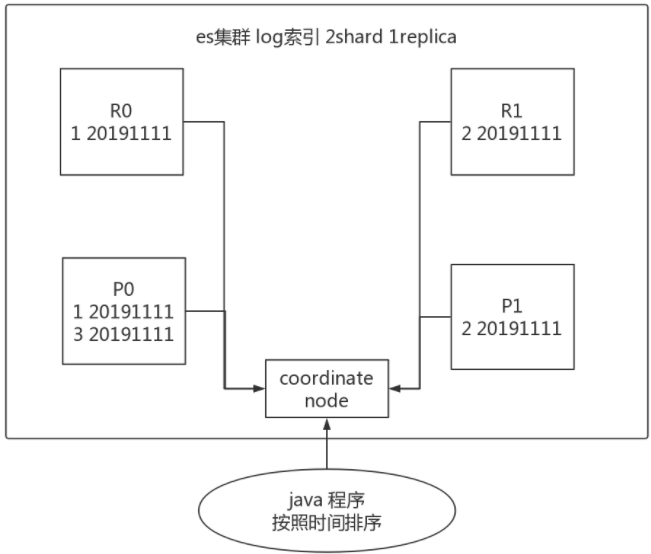
比如当你使用一个timestamp字段对结果进行排序,因为es中时间格式为%Y-%m-%d,那么同样时间的数据会有很多。es如果不做任何设置,将会按round-robined的方式从primary和replica里取了再排序,这样结果就不能保证每次都一样的。毕竟primary有的replica里不一定有,尤其是在不停往es里存放数据的情况。
如果有两份文档拥有相同的timestamp,因为搜索请求是以一种循环(round-robin)的方式被可用的分片拷贝进行处理的,因此这两份文档的返回顺序可能因为处理的分片不一样而不同,比如主分片处理的顺序和副本分片处理的顺序就可能不一样。这就是结果跳跃问题:每次用户刷新页面都会发现结果的顺序不一样。
解决方案就是设置preference参数,使每个user每次搜索的时候,都使用同一个replica shard去执行,就不会看到bouncing results了
preference参数决定了哪些shard会被用来执行搜索操作
_primary:发送到集群的相关操作请求只会在主分片上执行。_primary_first:指查询会先在主分片中查询,如果主分片找不到(挂了),就会在副本中查询。_replica:发送到集群的相关操作请求只会在副本上执行。_replica_first:指查询会先在副本中查询,如果副本找不到(挂了),就会在主分片中查询。_local: 指查询操作会优先在本地节点有的分片中查询,没有的话再在其它节点查询。_prefer_nodes:abc,xyz:在提供的节点上优先执行(在这种情况下为’abc’或’xyz’)_shards:2,3:限制操作到指定的分片。 (2和“3”)。这个偏好可以与其他偏好组合,但必须首先出现:_shards:2,3 | _primary_only_nodes:node1,node2:指在指定id的节点里面进行查询,如果该节点只有要查询索引的部分分片,就只在这部分分片中查找,不同节点之间用“,”分隔。
custom(自定义):注意自定义的preference参数不能以下划线"_"开头。当preference为自定义时,即该参数不为空,且开头不以“下划线”开头时,特别注意:如果以用户query作为自定义preference时,一定要处理以下划线开头的情况,这种情况下如果不属于以上8种情况,则会抛出异常。
GET /_search?preference=_shards:2,32、timeout
已经讲解过原理了,链接:ElasticSearch7.3学习(十七)----搜索结果字段解析及time_out字段解析
简单来说就是限定在一定时间内,将部分获取到的数据直接返回,避免查询耗时过长
GET /_search?timeout=10ms3、routing
详情请见链接:ElasticSearch7.3学习(六)----文档(document)内部机制详解,数据路由部分
document文档路由,_id路由,routing=user_id,这样的话可以让同一个user对应的数据到一个shard上去
GET /_search?routing=user1234、search_type
在讲这四种搜索类型的区别之前, 先分析一下分布式搜索背景介绍:
ES 天生就是为分布式而生, 但分布式有分布式的缺点。 比如要搜索某个单词, 但是数据却分别在 5 个分片(Shard)上面, 这 5 个分片可能在 5 台主机上面。 因为全文搜索天生就要排序( 按照匹配度进行排名) ,但数据却在 5 个分片上, 如何得到最后正确的排序呢?
ES是这样做的, 大概分两步:
- ES 客户端将会同时向 5 个分片发起搜索请求。
- 这 5 个分片基于本分片的内容独立完成搜索, 然后将符合条件的结果全部返回。
客户端将返回的结果进行重新排序和排名,最后返回给用户。也就是说,ES的一次搜索,是一次scatter/gather过程(这个跟mapreduce也很类似)
然而这其中有两个问题:
1、 数量问题。 比如, 用户需要搜索"衣服", 要求返回符合条件的前 10 条。 但在 5个分片中, 可能都存储着衣服相关的数据。 所以 ES 会向这 5 个分片都发出查询请求, 并且要求每个分片都返回符合条件的 10 条记录。当ES得到返回的结果后,进行整体排序,然后取最符合条件的前10条返给用户。 这种情况, ES 中 5 个 shard 最多会收到 10*5=50条记录, 这样返回给用户的结果数量会多于用户请求的数量。
2、 排名问题。 上面说的搜索, 每个分片计算符合条件的前 10 条数据都是基于自己分片的数据进行打分计算的。计算分值使用的词频和文档频率等信息都是基于自己分片的数据进行的, 而 ES 进行整体排名是基于每个分片计算后的分值进行排序的(相当于打分依据就不一样, 最终对这些数据统一排名的时候就不准确了), 这就可能会导致排名不准确的问题。如果我们想更精确的控制排序, 应该先将计算排序和排名相关的信息( 词频和文档频率等打分依据) 从 5 个分片收集上来, 进行统一计算, 然后使用整体的词频和文档频率为每个分片中的数据进行打分, 这样打分依据就一样了。
这两个问题, ES 也没有什么较好的解决方法, 最终把选择的权利交给用户, 方法就是在搜索的时候指定 search type。
4.1 query and fetch
向索引的所有分片 ( shard)都发出查询请求, 各分片返回的时候把元素文档 ( document)和计算后的排名信息一起返回。
优点:这种搜索方式是最快的。因为相比后面的几种es的搜索方式,这种查询方法只需要去shard查询一次。
缺点:返回的数据量不准确, 可能返回(N*分片数量)的数据并且数据排名也不准确,同时各个shard返回的结果的数量之和可能是用户要求的size的n倍。
4.2 query then fetch
es 默认的搜索方式,如果你搜索时, 没有指定搜索方式, 就是使用的这种搜索方式。 这种搜索方式, 大概分两个步骤:
1、先向所有的 shard 发出请求, 各分片只返回文档 id(注意, 不包括文档 document)和排名相关的信息(也就是文档对应的分值), 然后按照各分片返回的文档的分数进行重新排序和排名, 取前 size 个文档。
2、根据文档 id 去相关的 shard 取 document。 这种方式返回的 document 数量与用户要求的大小是相等的。
优点:返回的数据量是准确的。
缺点:性能一般,并且数据排名不准确。
4.3 DFS query and fetch
这种方式比第一种方式多了一个 DFS 步骤,有这一步,可以更精确控制搜索打分和排名。也就是在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块, 再执行后面的操作、
优点:数据排名准确
缺点:性能一般,返回的数据量不准确, 可能返回(N*分片数量)的数据
4.4 DFS query then fetch
比第 2 种方式多了一个 DFS 步骤。也就是在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块, 再执行后面的操作、
优点:返回的数据量是准确的;数据排名准确
缺点:能最差,这个最差只是表示在这四种查询方式中性能最慢, 也不至于不能忍受,如果对查询性能要求不是非常高, 而对查询准确度要求比较高的时候可以考虑这个
4.5 DFS过程
从 es 的官方网站我们可以发现, DFS 其实就是在进行真正的查询之前, 先把各个分片的词频率和文档频率收集一下, 然后进行词搜索的时候, 各分片依据全局的词频率和文档频率进行搜索和排名。 显然如果使用 DFS_QUERY_THEN_FETCH 这种查询方式, 效率是最低的,因为一个搜索, 可能要请求 3 次分片。 但使用 DFS 方法, 搜索精度是最高的。
总结一下, 从性能考虑 QUERY_AND_FETCH 是最快的, DFS_QUERY_THEN_FETCH 是最慢的。从搜索的准确度来说, DFS 要比非 DFS 的准确度更高。
这篇关于ElasticSearch7.3学习(二十六)----搜索(Search)参数总结、结果跳跃(bouncing results)问题解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






