本文主要是介绍语料库技术与应用—基于维基百科构建日语平行语料并爬取谷歌翻译语音(mp3),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
准备:wikipedia-parallel-titles项目(老师给的)
This document describes how to use these tools to build a parallel corpus (for a specific language pair) based on article titles across languages in Wikipedia.
本文档描述了如何使用这些工具基于维基百科中不同语言的文章标题构建并行语料库(针对特定的语言对)。
首先第一步:
- 确定自己选的小语种的 639-1码, 例如 日语的 639-1码为 “ja”;
- 把 “ja” 与单词 “wiki”拼接得到 “jawiki”,
然后访问 http://dumps.wikimedia.org/jawiki ,如图:
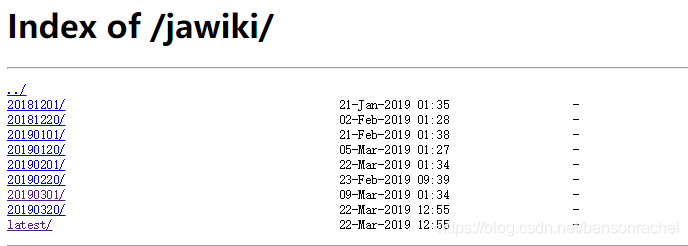
可到” https://en.wikipedia.org/wiki/List_of_ISO_639-2_codes” 上查看自己选的小语种的639-1码
3.选择 “201903XX” 或 “latest” ,进去下载以 “-page.sql.gz” 和 “-langlinks.sql.gz” 结尾的两个压缩包;
4.提取并行标题语料:运行该脚本命令
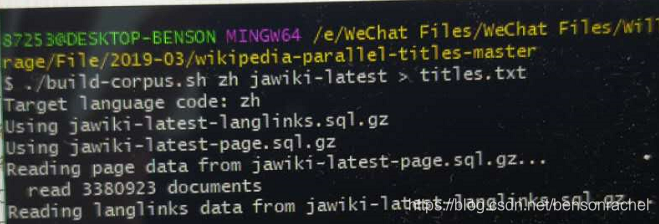
并出现如图
1: 下载下来的两个.gz压缩包需和 build-corpus.sh 脚本在同一个路径下;
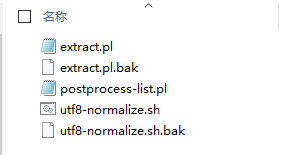
2: 若执行了脚本后 titles.txt 什么都没有并出现如图所示:
解决方法: 打开scripts目录下的 extract.pl 、utf8-normalize.sh 这两个文件,把其中的
“iconv -f utf8 -t utf8 –c” 语句 修改为 “iconv -f utf-8 -t utf-8 –c” (其他地方的”utf8”不用改)
4:生成 titles.txt 可能需要几分钟,请耐心等待。

出来是这个样子的。
步骤二:
把语料放到谷歌翻译上并下载其朗读语音
https://blog.csdn.net/qq_40224992/article/details/88546823
参考的是这篇文章,不过也需要作些修改。(感谢作者,不然就要动用按键精灵了)
日语的:
import requests
import os
from edf import ctx
myfile= open("titles.txt","r",encoding="utf-8")
wordlist=myfile.read().splitlines()
myfile.close()
log=open("log1.txt","a",encoding="utf-8")
for word in wordlist[25853:]:word=word.split("|||")[0]word=word.replace(" ","")if(os.path.exists("mp3/"+word+".mp3")):continueword2=wordprint(word2)word2=word.replace(" ","")word2 = word.replace("+", "")word2 = word.replace("-", "")url="https://translate.google.cn/translate_tts?ie=UTF-8&q="+word2+"&tl=ja&total=1&idx=0&textlen="+str(len(word2))+"&tk="+ctx.call("TL",word2)+"&client=webapp"print(url)try:newfile=open("mp3/"+word+".mp3","wb")print(url)context = requests.get(url,timeout = 3000)for data in context.iter_content(chunk_size=1024):if data:newfile.write(data)log.write(word+"\r\n")log.flush()newfile.close()except:log.write(word + "-wrong"+"\r\n")log.flush()continue
import execjsctx = execjs.compile(""" function TL(a) { var k = ""; var b = 406644; var b1 = 3293161072; var jd = "."; var $b = "+-a^+6"; var Zb = "+-3^+b+-f"; for (var e = [], f = 0, g = 0; g < a.length; g++) { var m = a.charCodeAt(g); 128 > m ? e[f++] = m : (2048 > m ? e[f++] = m >> 6 | 192 : (55296 == (m & 64512) && g + 1 < a.length && 56320 == (a.charCodeAt(g + 1) & 64512) ? (m = 65536 + ((m & 1023) << 10) + (a.charCodeAt(++g) & 1023), e[f++] = m >> 18 | 240, e[f++] = m >> 12 & 63 | 128) : e[f++] = m >> 12 | 224, e[f++] = m >> 6 & 63 | 128), e[f++] = m & 63 | 128) } a = b; for (f = 0; f < e.length; f++) a += e[f], a = RL(a, $b); a = RL(a, Zb); a ^= b1 || 0; 0 > a && (a = (a & 2147483647) + 2147483648); a %= 1E6; return a.toString() + jd + (a ^ b) }; function RL(a, b) { var t = "a"; var Yb = "+"; for (var c = 0; c < b.length - 2; c += 3) { var d = b.charAt(c + 2), d = d >= t ? d.charCodeAt(0) - 87 : Number(d), d = b.charAt(c + 1) == Yb ? a >>> d: a << d; a = b.charAt(c) == Yb ? a + d & 4294967295 : a ^ d } return a }""")
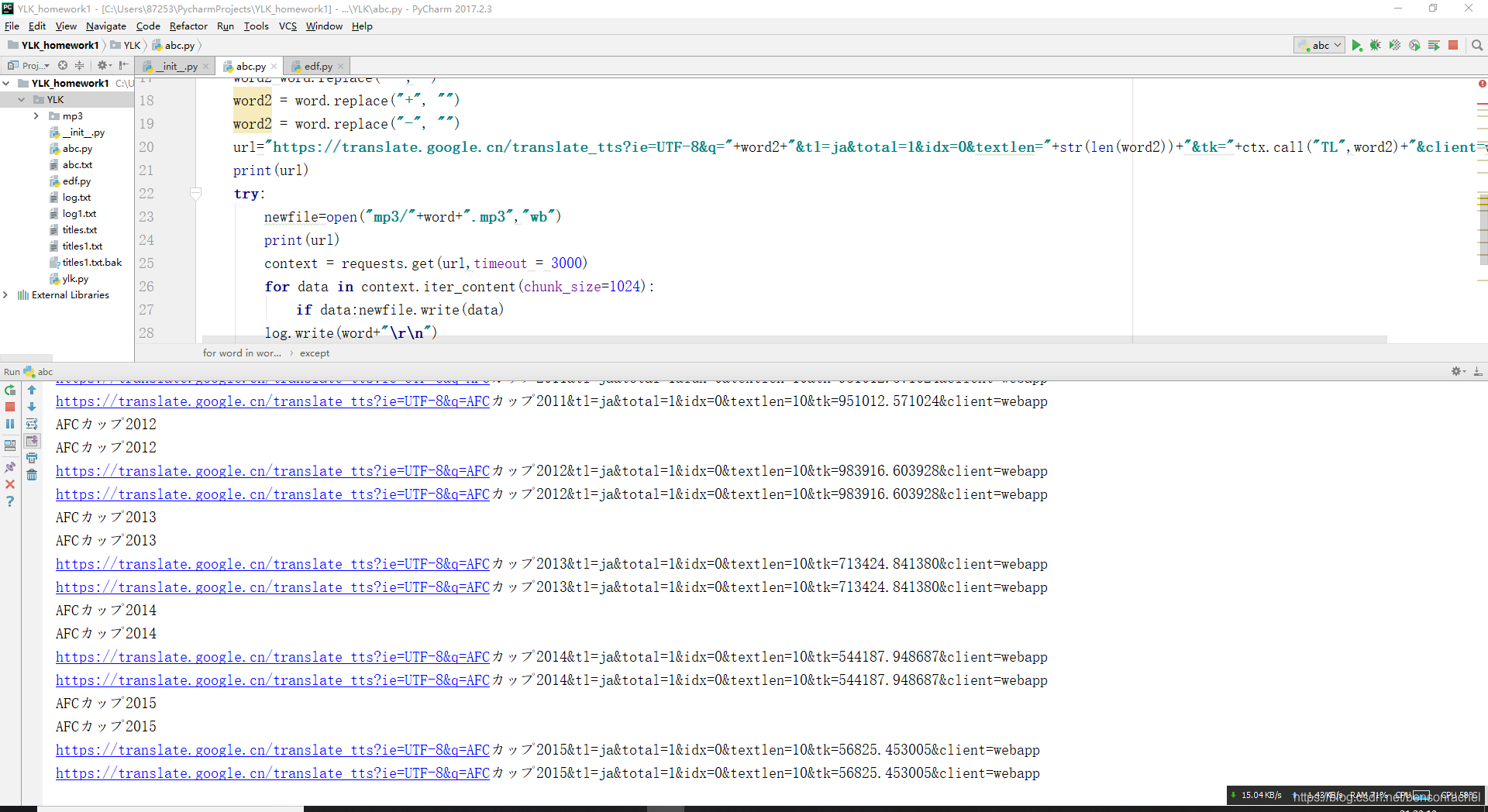
说一下这个url如何找,谷歌浏览器:
谷歌翻译,在左侧输入日语,点击进入检查(F12),再点击发音那个按钮
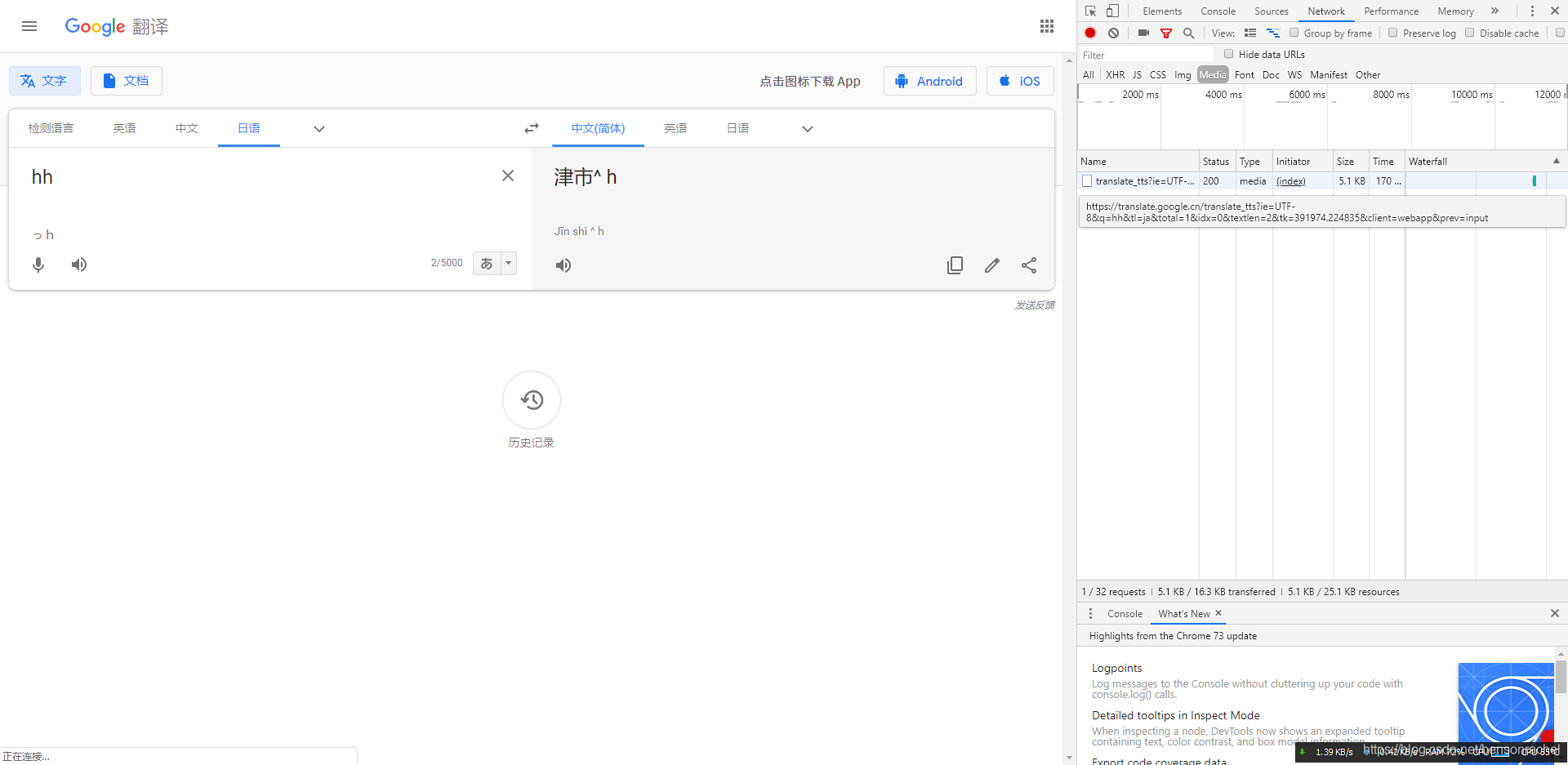
右侧那个链接就是了。
最后mp3(女声):

到此,感觉这个项目sese的有没有。。。
总结:别再犯list[]01的错误!!!
总结:别再犯list[]01的错误!!!
总结:别再犯list[]01的错误!!!
第一个下标是0!!!
第一个下标是0!!!
第一个下标是0!!!
还有,文件夹要先创。
注:此项目的完成,需要感谢某位热心的同学的帮助。以及讨论中同学们的帮助和指点。
这篇关于语料库技术与应用—基于维基百科构建日语平行语料并爬取谷歌翻译语音(mp3)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






