本文主要是介绍嵌入式web服务器boa移植全过程(含图解过程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、boa下载和安装:1、修改编译安装文件:
1)在www.boa.org下载boa-0.94.13.tar.gz 并解压
2)在src目录下运行./configure生成Makefile。
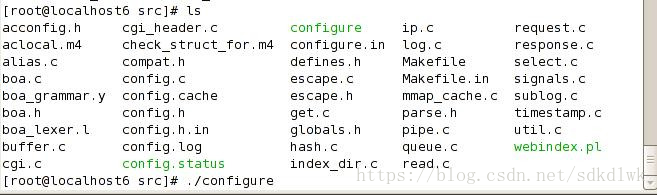
3)生成Makefile文件,修改
CC = arm-linux-gcc -static
CPP = arm-linux-gcc –E -static
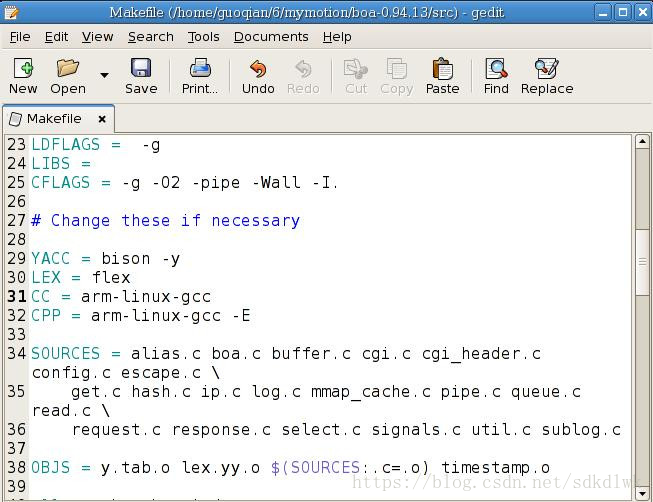
2、修改boa.c源文件
将boa.c文件中以下几行判断注释掉。
if (setuid(0) != -1) {
DIE("icky Linux kernel bug!");
}
改为
/*if (setuid(0) != -1) {
DIE("icky Linux kernel bug!");
}*/
大约211行附近
/* if (passwdbuf == NULL) {
DIE("getpwuid");
}
if (initgroups(passwdbuf->pw_name, passwdbuf->pw_gid) == -1) {
DIE("initgroups");
}*/
/*if (setuid(0) != -1) {
DIE("icky Linux kernel bug!");
}*/
3、修改文件compat.h
#define TIMEZONE_OFFSET(foo) foo##->tm_gmtoff
修改成
#define TIMEZONE_OFFSET(foo) (foo)->tm_gmtoff
4、执行#make 命令
#make
#arm-linux-strip boa //去掉调试信息,生成的boa可执行文件将在70k左右。
将编译好的boa可执行文件拷贝到/bin目录 或者/sbin目录下。
二、配置boa.conf
配置只保留一下的文字(可以自己写一个boa.conf文件,同时保存相应的):
Port 80 //服务访问端口
User 0 //
Group 0 //
ErrorLog /var/log/boa/error_log //错误日志地址
AccessLog /var/log/boa/access_log //访问日志文件
ServerName 192.168.*.* (开发板ip)
DocumentRoot /var/www //HTML文档的主目录
UserDir public_html //
DirectoryIndex index.html //默认访问文件
DirectoryMaker /usr/lib/boa/boa_indexer
KeepAliveMax 1000 //一个连接所允许的HTTP持续作用请求最大数目
KeepAliveTimeout 10 //HTTP持续作用中服务器在两次请求之间等待的时间数,以秒为单位
MimeTypes /etc/mime.types //指明mime.types文件位置
DefaultType text/plain //文件扩展名没有或未知的话,使用的缺省MIME类型
CGIPath /bin:/usr/bin:/usr/local/bin //提供CGI程序的PATH环境变量值
Alias /doc /usr/doc //为路径加上别名
ScriptAlias /cgi-bin/ /var/www/cgi-bin/ //输入站点和CGI脚本位置
可以将以上的文档直接拷到一个空白的boa.conf文件中,并将boa.conf文件拷到/etc/boa/boa.conf位置。也可以修改源码包下的boa.conf
重点注意:
用户可以根据自己需要,对boa.conf进行修改,但必须要保证其他的辅助文件和设置必须和boa.conf里的配置相符,不然Boa就不能正常工作。 在上面的例子中,我们还需要创建日志文件所在目录/var/log/boa,创建HTML文档的主目录/var/www。
关键:将mime.types、inittab和passwd文件从任何一个linux系统中的/etc目录下拷贝到开发板文件系统的/etc目录下,创建CGI脚本所在目录/var/www/cgi-bin/。mime.types文件用来指明不同文件扩展名对应的MIME类型,一般可以直接从Linux主机上拷贝一个,大部分也都是在主机的/etc目录下。
这篇关于嵌入式web服务器boa移植全过程(含图解过程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





