本文主要是介绍天池长期赛:二手车价格预测(422方案分享),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
一、赛题介绍及评测标准
二、数据探索(EDA)
1.读取数据、缺失值可视化
2.特征描述性统计
3.测试集与验证集数据分布
4.特征相关性
三、数据清洗
四、特征工程
1.构建时间特征
2.匿名特征交叉
3.平均数编码
五、建模调参
六、模型融合
总结
前言
赛题属于回归类型,相比于前两次的保险反欺诈及贷款违约预测,本次比赛学到了很多特征工程、模型调参及模型融合的处理,收货颇丰。
一、赛题介绍及评测标准
赛题以预测二手车的交易价格为任务,该数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。
长期赛的测试集是B,特征介绍如下:


二、数据探索(EDA)
1.读取数据、缺失值可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('/train.csv', sep=' ')
# 缺失值可视化
missing = df.isnull().sum()/len(df)
missing = missing[missing > 0]
missing.sort_values(inplace=True) #排个序
missing.plot.bar()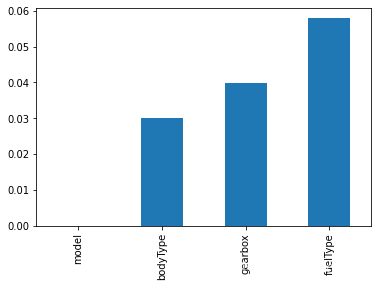
2.特征描述性统计
df.describe().T
目标变量price, 75%以下的数据与最大值相差较大,数据呈现一个偏态分布(也可以可视化,会更加直观),这也是后续要进行对数转换的原因。
3.测试集与验证集数据分布
# 分离数值变量与分类变量
Nu_feature = list(df.select_dtypes(exclude=['object']).columns) # 数值变量
Ca_feature = list(df.select_dtypes(include=['object']).columns)
plt.figure(figsize=(30,25))
i=1
for col in Nu_feature:ax=plt.subplot(6,5,i)ax=sns.kdeplot(df[col],color='red')ax=sns.kdeplot(test[col],color='cyan')ax.set_xlabel(col)ax.set_ylabel('Frequency')ax=ax.legend(['train','test'])i+=1
plt.show()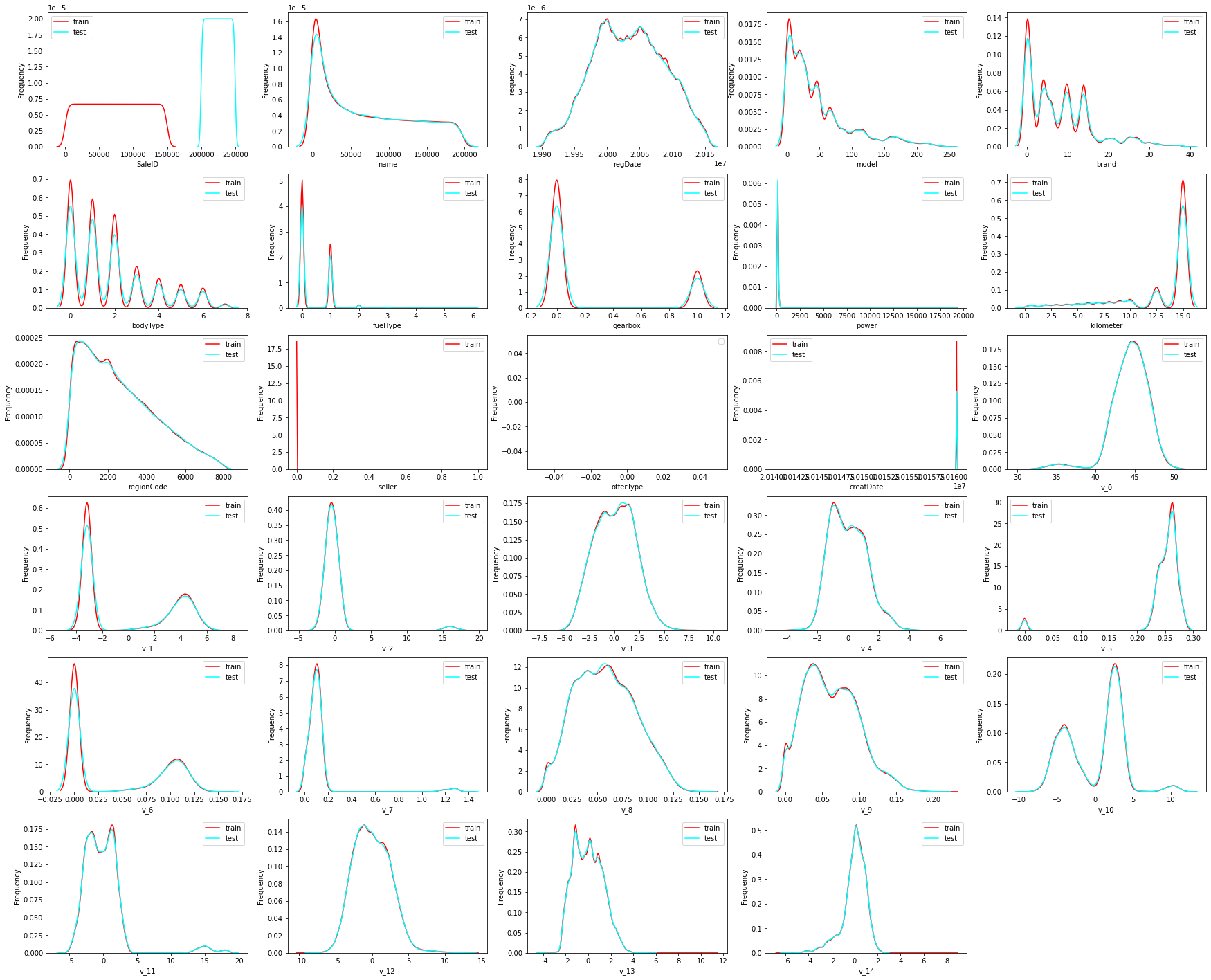
这几次比赛的数据集主办方都处理的很好,分布都是一致的 。
4.特征相关性
correlation_matrix=df.corr()
plt.figure(figsize=(12,10))
sns.heatmap(correlation_matrix,vmax=0.9,linewidths=0.05,cmap="RdGy")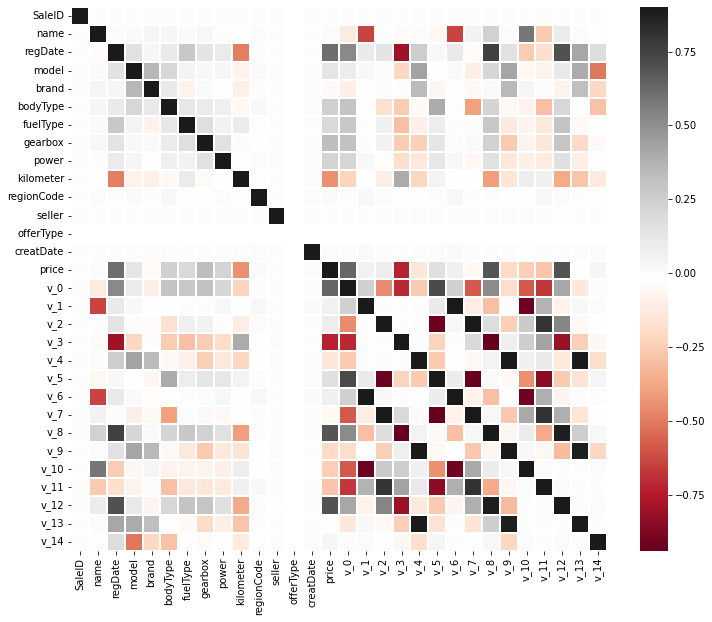
与目标变量相关性比较高的特征有regDate、kilometer、v_0、v_3、v_8、v_12,这个不难理解,注册日期越早,行驶公里数越多,车价相对会越低。品牌和车型与目标变量的相关性较低这点比较意外。
三、数据清洗
# 众数填充缺失值
df['notRepairedDamage']=df['notRepairedDamage'].replace('-',0.0)
df['fuelType'] = df['fuelType'].fillna(0)
df['gearbox'] = df['gearbox'].fillna(0)
df['bodyType'] = df['bodyType'].fillna(0)
df['model'] = df['model'].fillna(0)
# 截断异常值
df['power'][df['power']>600] = 600
df['power'][df['power']<1] = 1
df['v_13'][df['v_13']>6] = 6
df['v_14'][df['v_14']>4] = 4
# 目标变量进行对数变换服从正态分布
df['price'] = np.log1p(df['price'])大部分模型是以数据正态分布为前提,目标变量如果偏态严重,会影响模型预测效果,所以才会进行对数正态化。
众数填充是一种比较常见的缺失值填充方式,异常值截断是参考天池论坛的文章。
四、特征工程
特征工程我参考了很多大神的方法,自己也尝试了很多组合在模型上运行,最终确定了这些特征,
毕竟模型都差不多,特征能够对提分有比较显著的效果,更多特征的构建可以参考:
零基础入门数据挖掘系列之「特征工程」-天池技术圈-天池技术讨论区
1.构建时间特征
from datetime import datetime
def date_process(x):year = int(str(x)[:4])month = int(str(x)[4:6])day = int(str(x)[6:8])if month < 1:month = 1date = datetime(year, month, day)return date
df['regDate'] = df['regDate'].apply(date_process)
df['creatDate'] = df['creatDate'].apply(date_process)
df['regDate_year'] = df['regDate'].dt.year
df['regDate_month'] = df['regDate'].dt.month
df['regDate_day'] = df['regDate'].dt.day
df['creatDate_year'] = df['creatDate'].dt.year
df['creatDate_month'] = df['creatDate'].dt.month
df['creatDate_day'] = df['creatDate'].dt.day
df['car_age_day'] = (df['creatDate'] - df['regDate']).dt.days#二手车使用天数
df['car_age_year'] = round(df['car_age_day'] / 365, 1)#二手车使用年数2.匿名特征交叉
num_cols = [0,2,3,6,8,10,12,14]
for index, value in enumerate(num_cols):for j in num_cols[index+1:]:df['new'+str(value)+'*'+str(j)]=df['v_'+str(value)]*df['v_'+str(j)]df['new'+str(value)+'+'+str(j)]=df['v_'+str(value)]+df['v_'+str(j)]df['new'+str(value)+'-'+str(j)]=df['v_'+str(value)]-df['v_'+str(j)]num_cols1 = [3,5,1,11]
for index, value in enumerate(num_cols1):for j in num_cols1[index+1:]:df['new'+str(value)+'-'+str(j)]=df['v_'+str(value)]-df['v_'+str(j)]for i in range(15):df['new'+str(i)+'*year']=df['v_'+str(i)] * df['car_age_year']3.平均数编码
X=df.drop(columns=['price','SaleID','seller','offerType', 'name','creatDate','regionCode'])
Y=df['price']import Meancoder # 平均数编码
class_list = ['model','brand','power','v_0','v_3','v_8','v_12']
MeanEnocodeFeature = class_list # 声明需要平均数编码的特征
ME = Meancoder.MeanEncoder(MeanEnocodeFeature,target_type='regression') # 声明平均数编码的类
X = ME.fit_transform(X,Y) # 对训练数据集的X和y进行拟合
五、建模调参
参数建议选择较低的学习率,用较高的迭代次数,可以提高模型精确度,可以参考
Datawhale 零基础入门数据挖掘-Task4 建模调参-天池实验室-实时在线的数据分析协作工具,享受免费计算资源
from catboost import CatBoostRegressor
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
# 划分训练及测试集
x_train,x_test,y_train,y_test = train_test_split( X, Y,test_size=0.3,random_state=1)
# 模型训练
clf=CatBoostRegressor(loss_function="MAE",eval_metric= 'MAE',task_type="CPU",od_type="Iter", #过拟合检查类型random_seed=2022) # learning_rate、iterations、depth可以自己尝试
# 5折交叉 test是测试集B,已经经过清洗及特征工程,方法与训练集一致
result = []
mean_score = 0
n_folds=5
kf = KFold(n_splits=n_folds ,shuffle=True,random_state=2022)
for train_index, test_index in kf.split(X):x_train = X.iloc[train_index]y_train = Y.iloc[train_index]x_test = X.iloc[test_index]y_test = Y.iloc[test_index]clf.fit(x_train,y_train)y_pred=clf.predict(x_test)print('验证集MAE:{}'.format(mean_absolute_error(np.expm1(y_test),np.expm1(y_pred))))mean_score += mean_absolute_error(np.expm1(y_test),np.expm1(y_pred))/ n_foldsy_pred_final = clf.predict(test)y_pred_test=np.expm1(y_pred_final)result.append(y_pred_test)
# 模型评估
print('mean 验证集MAE:{}'.format(mean_score))
cat_pre=sum(result)/n_folds
ret=pd.DataFrame(cat_pre,columns=['price'])
ret.to_csv('/预测.csv')经过交叉验证取平均值可以将线上分数提高10到15,由于price前期做了对数变换,在预测时需要还原。
六、模型融合
模型融合是用catboost与lightgbm,catboost精确度比lightgbm高,但训练速度没有lightgbm快,采用简单的加权融合可以将线上分数提高5-7,我也试过用stack融合,但效果没有加权融合好,这个仁者见仁智者见智吧,模型融合可以参考:
Datawhale 零基础入门数据挖掘-Task5 模型融合-天池实验室-实时在线的数据分析协作工具,享受免费计算资源
| catboost+特征交叉+调参+5折 | 线上447 |
| catboost+特征交叉+平均数编码+调参+5折 | 线上437 |
| catboost+lightgbm+特征交叉+平均数编码+调参+5折+模型加权融合 | 线上422 |
from lightgbm.sklearn import LGBMRegressor
gbm = LGBMRegressor() # 参数可以去论坛参考
# 由于模型不支持object类型的处理,所以需要转化
X['notRepairedDamage'] = X['notRepairedDamage'].astype('float64')
test['notRepairedDamage'] = test['notRepairedDamage'].astype('float64')
result1 = []
mean_score1 = 0
n_folds=5
kf = KFold(n_splits=n_folds ,shuffle=True,random_state=2022)
for train_index, test_index in kf.split(X):x_train = X.iloc[train_index]y_train = Y.iloc[train_index]x_test = X.iloc[test_index]y_test = Y.iloc[test_index]gbm.fit(x_train,y_train)y_pred1=gbm.predict(x_test)print('验证集MAE:{}'.format(mean_absolute_error(np.expm1(y_test),np.expm1(y_pred1))))mean_score1 += mean_absolute_error(np.expm1(y_test),np.expm1(y_pred1))/ n_foldsy_pred_final1 = gbm.predict((test),num_iteration=gbm.best_iteration_)y_pred_test1=np.expm1(y_pred_final1)result1.append(y_pred_test1)
# 模型评估
print('mean 验证集MAE:{}'.format(mean_score1))
cat_pre1=sum(result1)/n_folds#加权融合
sub_Weighted = (1-mean_score1/(mean_score1+mean_score))*cat_pre1+(1-mean_score/(mean_score1+mean_score))*cat_pre
总结
1.特征工程有太多组合可以尝试,有时间的朋友可以多多尝试。
2.论坛上有大神用深度学习模型,只构建的时间特征就能跑到420左右的分数,有兴趣的朋友可以尝试下。
3.对于目标变量还有无界约翰逊分布johnsonsu处理方式,效果比对数处理要好,但还原有点麻烦。
4. stack模型的融合应该是要优于加权融合的,可以尝试3个以上的不同类型的模型融合,或许效果会更好。
这篇关于天池长期赛:二手车价格预测(422方案分享)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







