本文主要是介绍python链队_队列的链式存储结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
队列是一种先进先出(first in first out,FIFO)的线性表,是一种常用的数据结构。
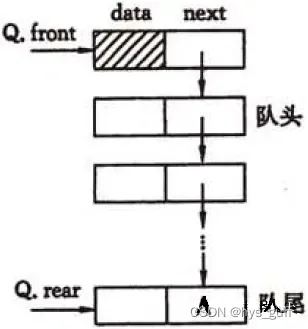
它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。

- 一个链队列需要两个指针才能唯一确定,它们分别指示队头和队尾(分别称为头指针和尾指针)
- 与线性表的单链表一样,为了操作方便起见, 给链队列添加一个头结点,并令头指针指向头结点
- 空的链队列的判别条件为头指针和尾指针均指向头结点
判空:
def empty(self):return self.front==None入队:
def push(self, data):new_node = Node(data)if self.front == None: #为空时self.front = new_node #获得首结点self.rear = self.frontelse:self.rear.next = new_node #将新结点挂上去,让链式结构显现self.rear = new_node #rear指针后移出队:
def pop(self):assert not self.empty()if self.front == self.rear: #当链队中只有一个元素时e=self.front.data #获取e,让其能够printself.front=self.rear=None #重置为Noneelse:e=self.front.dataself.front=self.front.nextreturn e队首元素:
def gethead(self):assert not self.empty()e=self.front.data #front,第一个元素return e源码:
class Node:def __init__(self, data=None):self.data = dataself.next = None
class LinkQueue:"""没有head结点,但需要front和rear指针来挂"""def __init__(self):self.front = Noneself.rear = None #始终指向最后一个元素def empty(self):return self.front==Nonedef push(self, data):new_node = Node(data)if self.front == None: #为空时self.front = new_node #获得首结点self.rear = self.frontelse:self.rear.next = new_node #将新结点挂上去,让链式结构显现self.rear = new_node #rear指针后移def pop(self):assert not self.empty()if self.front == self.rear: #当链队中只有一个元素时e=self.front.data #获取e,让其能够printself.front=self.rear=None #重置为Noneelse:e=self.front.dataself.front=self.front.nextreturn edef gethead(self):assert not self.empty()e=self.front.data #front,第一个元素return e
这篇关于python链队_队列的链式存储结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





