本文主要是介绍集合框架:List系列集合:特点、方法、遍历方式、ArrayList,LinkList的底层原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
List集合
特有方法
遍历方式
1. 使用普通 for 循环:
2. 使用增强型 for 循环(foreach):
3. 使用迭代器(Iterator):
4. 使用 Java 8+ 的流(Stream)API:
ArrayList集合的底层原理
LinkList集合的底层原理
List集合

List系列集合特点: 有序,可重复,有索引
ArrayList: 有序,可重复,有索引。
LinkedList:有序,可重复,有索引。底层实现不同 !适合的场景不同 !
特有方法
List集合因为支持索引,所以多了很多与索引相关的方法,当然,Collection的功能List也都继承了。
List(列表):
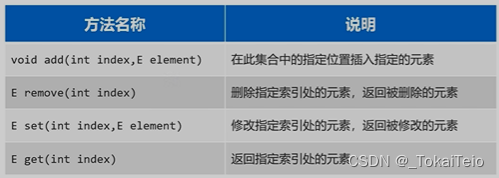
add(E element):在列表末尾添加一个元素。get(int index):获取指定索引位置的元素。set(int index, E element):将指定索引位置的元素替换为新元素。remove(int index):移除指定索引位置的元素。size():返回列表包含的元素个数。
遍历方式
在 Java 中,可以使用不同的方式来遍历 List 系列集合,其中最常用的方式有以下几种:
1. 使用普通 for 循环:
List<String> myList = new ArrayList<>();
myList.add("apple");
myList.add("banana");
myList.add("orange");for (int i = 0; i < myList.size(); i++) {String element = myList.get(i);System.out.println(element);
}2. 使用增强型 for 循环(foreach):
List<String> myList = new ArrayList<>();
myList.add("apple");
myList.add("banana");
myList.add("orange");for (String element : myList) {System.out.println(element);
}3. 使用迭代器(Iterator):
List<String> myList = new ArrayList<>();
myList.add("apple");
myList.add("banana");
myList.add("orange");Iterator<String> iterator = myList.iterator();
while (iterator.hasNext()) {String element = iterator.next();System.out.println(element);
}4. 使用 Java 8+ 的流(Stream)API:
List<String> myList = new ArrayList<>();
myList.add("apple");
myList.add("banana");
myList.add("orange");myList.stream().forEach(System.out::println);以上就是常见的 List 系列集合的遍历方式。
ArrayList集合的底层原理
当我们使用 ArrayList 时,可以将它类比为一个动态调整大小的容器。它内部通过一个数组来存储元素,数组的长度会根据需要自动扩展或收缩。
初始时,ArrayList 是一个空的容器,没有任何元素。当我们往 ArrayList 中添加元素时,它会检查当前数组是否已满。如果已满,就会创建一个更大的数组,并将所有元素从旧数组复制到新数组中。这样,就腾出了更多的空间来容纳新的元素。
同样地,如果我们从 ArrayList 中删除元素,它会自动调整数组的大小,以便节省内存空间。
由于 ArrayList 使用数组来存储元素,所以我们可以通过索引来快速访问元素,这就像找到数组中特定位置的元素一样方便和快速。
总结起来,ArrayList 可以看作是一个可调整大小的容器,它能够自动扩展和收缩内部的数组,以适应添加和删除元素的需求,并通过索引提供快速访问元素的能力。
LinkList集合的底层原理
当我们使用 LinkedList 时,可以将它看作是一个双向链表。每个节点包含一个值和两个引用,一个引用指向前一个节点,另一个引用指向后一个节点。
初始时,LinkedList 是一个空的链表,没有任何节点。当我们往 LinkedList 中添加元素时,它会创建一个新的包含元素值的节点,并在链表的末尾添加这个新节点。如果链表为空,这个新节点就是头节点和尾节点。
同样地,如果我们从 LinkedList 中删除元素,它会找到包含要删除元素的节点,并在链表中将这个节点移除。(如何定位要删除节点的位置,可以使用元素值或者索引来操作。)节点之间的引用会被调整以确保链表的完整性。
由于 LinkedList 是一个双向链表,因此它可以高效地添加或删除元素,而不必像 ArrayList 一样进行数组的拷贝操作。但这也意味着它不支持通过索引直接访问元素,随机访问元素的效率比 ArrayList 低。
总结起来,LinkedList 可以看作是一个双向链表,它可以高效地添加或删除元素,但访问元素时效率较低。
这篇关于集合框架:List系列集合:特点、方法、遍历方式、ArrayList,LinkList的底层原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





