本文主要是介绍[NLP] LLM---<训练中文LLama2(四)方式一>对LLama2进行SFT微调,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
指令精调
指令精调阶段的任务形式基本与Stanford Alpaca相同。训练方案也采用了LoRA进行高效精调,并进一步增加了可训练参数数量。在prompt设计上,精调以及预测时采用的都是原版Stanford Alpaca不带input的模版。对于包含input字段的数据,采用f"{instruction}+\n+{input}"的形式进行拼接。
其中,Stanford Alpaca 格式如下所示:
[{"instruction" : ...,"input" : ...,"output" : ...},...
]
首先,修改模型精调脚本run_sft.sh,需要修改的参数如下:
--model_name_or_path: 模型经过词表扩充并完成预训练进行权重合并之后所在的目录--tokenizer_name_or_path: Chinese-Alpaca tokenizer 所在的目录--dataset_dir: 指令精调数据的目录,包含一个或多个以json结尾的Stanford Alpaca格式的指令精调数据文件--validation_file: 用作验证集的单个指令精调文件,以json结尾,同样遵循Stanford Alpaca格式--output_dir: 模型权重输出路径
dataset_dir=./sft_dataset/train = Chinese-LLaMA-Alpaca/data
其他参数(如:per_device_train_batch_size、training_steps等)是否修改视自身情况而定。
# 运行脚本前请仔细阅读wiki(https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/sft_scripts_zh)
# Read the wiki(https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/sft_scripts_zh) carefully before running the script
lr=1e-4
lora_rank=64
lora_alpha=128
lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
modules_to_save="embed_tokens,lm_head"
lora_dropout=0.05pretrained_model=./merged_output_dir
chinese_tokenizer_path=./merged_output_dir
dataset_dir=./sft_dataset/train
per_device_train_batch_size=1
per_device_eval_batch_size=1
gradient_accumulation_steps=8
max_seq_length=512
output_dir=./sft_output_dir
validation_file=./sft_dataset/test/test.jsondeepspeed_config_file=ds_zero2_no_offload.jsontorchrun --nnodes 1 --nproc_per_node 1 run_clm_sft_with_peft.py \--deepspeed ${deepspeed_config_file} \--model_name_or_path ${pretrained_model} \--tokenizer_name_or_path ${chinese_tokenizer_path} \--dataset_dir ${dataset_dir} \--per_device_train_batch_size ${per_device_train_batch_size} \--per_device_eval_batch_size ${per_device_eval_batch_size} \--do_train \--do_eval \--seed $RANDOM \--fp16 \--num_train_epochs 1 \--lr_scheduler_type cosine \--learning_rate ${lr} \--warmup_ratio 0.03 \--weight_decay 0 \--logging_strategy steps \--logging_steps 10 \--save_strategy steps \--save_total_limit 3 \--evaluation_strategy steps \--eval_steps 100 \--save_steps 200 \--gradient_accumulation_steps ${gradient_accumulation_steps} \--preprocessing_num_workers 8 \--max_seq_length ${max_seq_length} \--output_dir ${output_dir} \--overwrite_output_dir \--ddp_timeout 30000 \--logging_first_step True \--lora_rank ${lora_rank} \--lora_alpha ${lora_alpha} \--trainable ${lora_trainable} \--lora_dropout ${lora_dropout} \--modules_to_save ${modules_to_save} \--torch_dtype float16 \--validation_file ${validation_file} \--load_in_kbits 16 \--gradient_checkpointing \--ddp_find_unused_parameters Falserun_clm_sft_with_peft.py 添加如下两行:
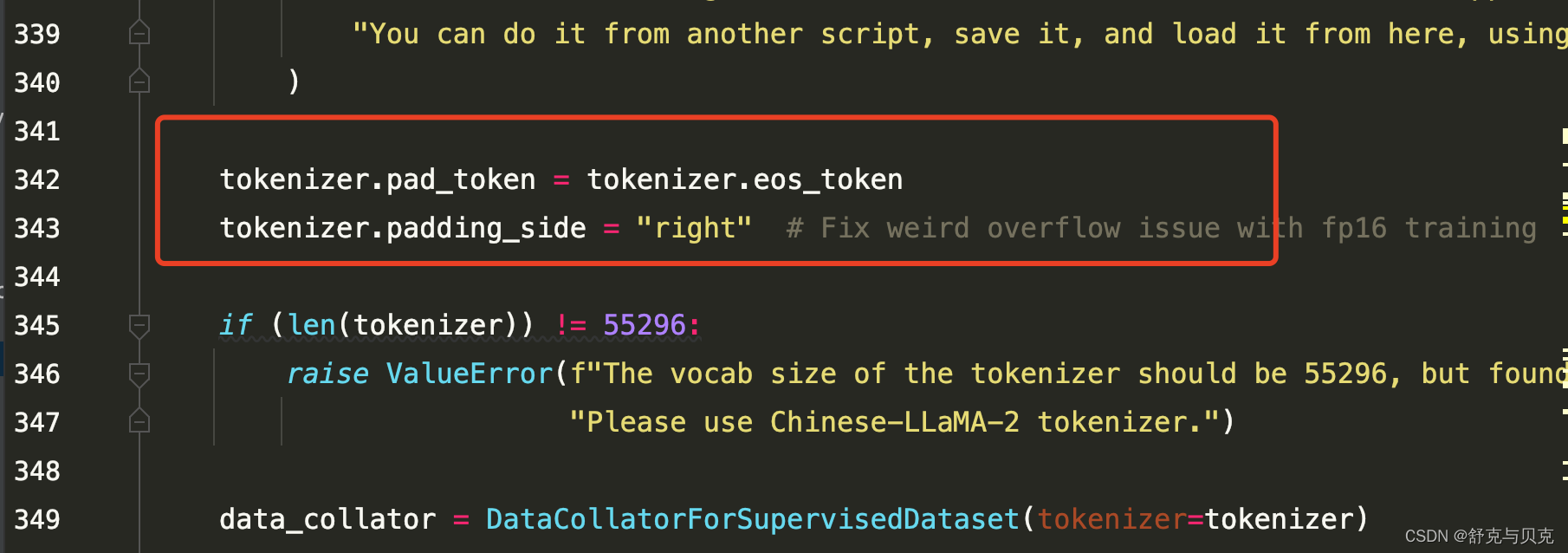
为了测试,对数据进行了sample
# coding=utf-8
import jsonwith open("alpaca_data_zh_51k.json", encoding="UTF-8") as f:data = json.load(f)print(len(data))
print(data[0])import random# 设置要划分的测试集大小
sample_size = int(0.1 * (len(data)))# 随机选择测试集的元素
sample_set = random.sample(data, sample_size)data = sample_set
# 设置要划分的测试集大小
test_size = int(0.1 * (len(data)))# 随机选择测试集的元素
test_set = random.sample(data, test_size)# 构建训练集,即剩下的元素
train_set = [x for x in data if x not in test_set]print("训练集:", len(train_set))
print("测试集:", len(test_set))with open("train/train.json", "w", encoding="UTF-8") as f:json.dump(train_set, f, indent=2, ensure_ascii=False)with open("valid/test.json", "w", encoding="UTF-8") as f:json.dump(test_set, f, indent=2, ensure_ascii=False)运行后输出:
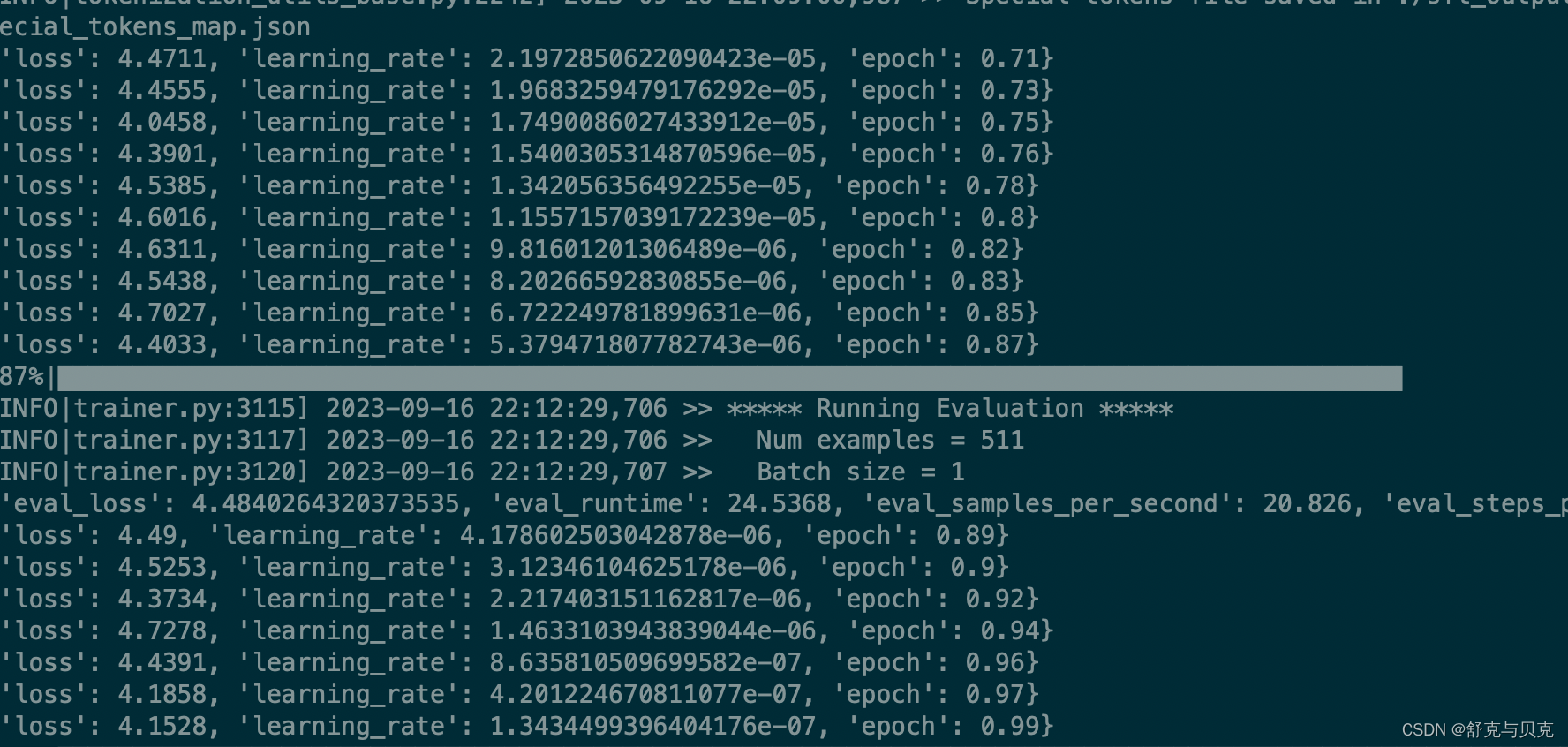
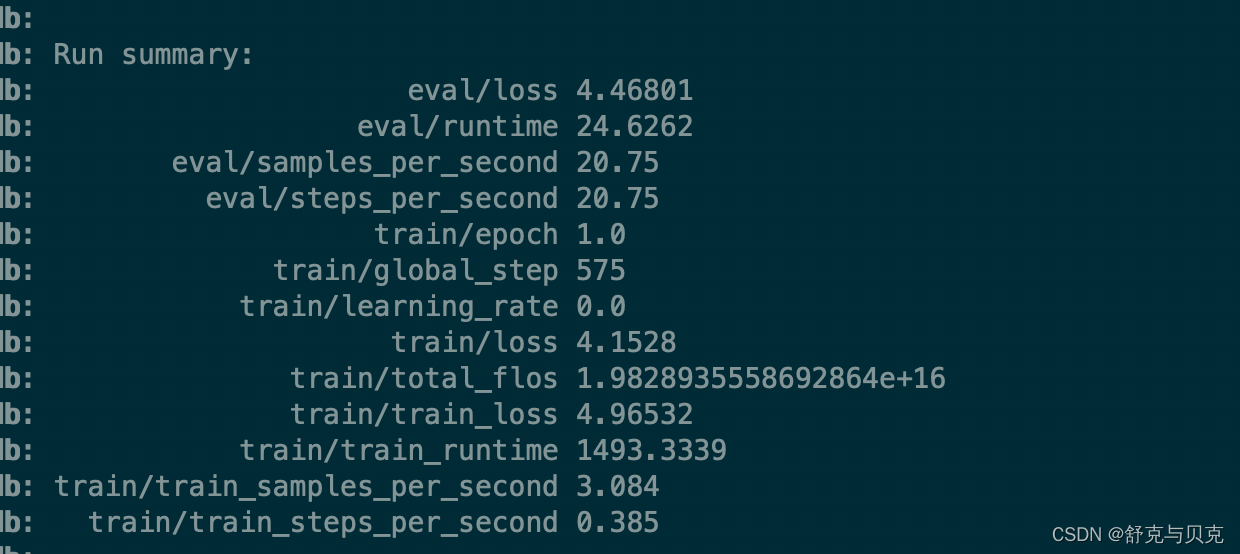
中文LLaMA&Alpaca大语言模型词表扩充+预训练+指令精调 - 知乎 (zhihu.com)
这篇关于[NLP] LLM---<训练中文LLama2(四)方式一>对LLama2进行SFT微调的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





