本文主要是介绍Hadoop2.7.3单机伪分布式环境搭建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Hadoop2.7.3单机伪分布式环境搭建
作者:家辉,日期:2018-07-10 CSDN博客: http://blog.csdn.net/gobitan
说明:Hadoop测试环境经常搭建,这里也做成一个模板并记录下来。
基础环境:CentOS7模板,参考: https://blog.csdn.net/gobitan/article/details/80993354 CentOS7_64位操作系统模板搭建
安装之前,先看一下Hadop架构图。
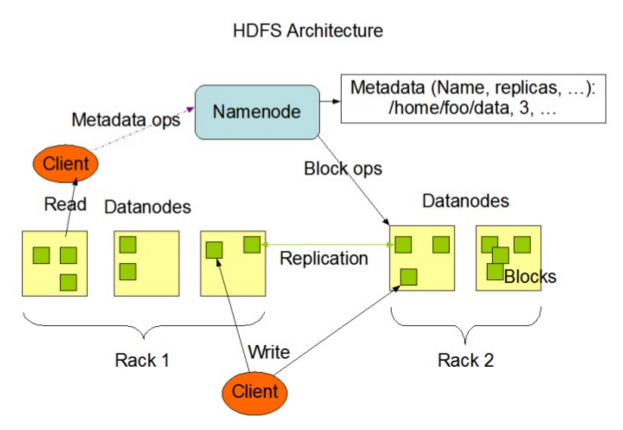
第一步:Hadoop安装包下载
我的百度网盘:链接: https://pan.baidu.com/s/1I351UowJLfkClf6v0iRytA 密码:5c9d
第二步:解压hadoop包
[root@centos7 ~]# cd /opt
[root@centos7 opt]# tar zxf /root/hadoop-2.7.3.tar.gz
[root@centos7 opt]# cd hadoop-2.7.3/
第三步:配置Hadoop
[1] 配置 hadoop-env.sh
编辑etc/hadoop/hadoop-env.sh,修改JAVA_HOME的值如下:
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64/jre
[2] 配置core-site.xml
编辑etc/hadoop/core-site.xml,修改如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.159.154:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.3/hadoop-tmp</value>
</property>
</configuration>
说明:hadoop.tmp.dir默认值为"/tmp/hadoop-${user.name}"。Linux操作系统重启后,这个目录会被清空,这可能导致数据丢失,因此需要修改。
[3] 配置hdfs-site.xml
编辑etc/hadoop/hdfs-site.xml,修改如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
[4] 配置SSH无密登录 本机
[root@centos7 hadoop-2.7.3]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
[root@centos7 hadoop-2.7.3]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@centos7 hadoop-2.7.3]# chmod 0600 ~/.ssh/authorized_keys
执行如下命令验证SSH配置,如下:
[root@centos7 hadoop-2.7.3]# ssh localhost
Last login: Sun May 13 23:06:10 2018 from localhost
这个过程不需要输入密码了,但之前是需要的。
第四步:格式化文件系统
[root@centos7 hadoop-2.7.3]# bin/hdfs namenode -format
如果执行成功,会在日志末尾看到格式化成功的提示,如下:
18/05/13 23:24:02 INFO common.Storage: Storage directory /opt/hadoop-2.7.3/hadoop-tmp/dfs/name has been successfully formatted.
第五步:启动HDFS
[root@centos7 hadoop-2.7.3]# sbin/start-dfs.sh
Starting namenodes on [centos7]
centos7: starting namenode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-namenode-centos7.out
localhost: starting datanode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-datanode-centos7.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-centos7.out
[root@centos7 hadoop-2.7.3]# jps
11301 SecondaryNameNode
11175 DataNode
11419 Jps
11087 NameNode
[root@centos7 hadoop-2.7.3]#
上面的启动命令启动了HDFS的管理节点NameNode和数据节点DataNode,以及NameNode的Slave节点,即SecondaryNameNode。
第六步:查看HDFS的NameNode的Web接口
http://192.168.159.154:50070
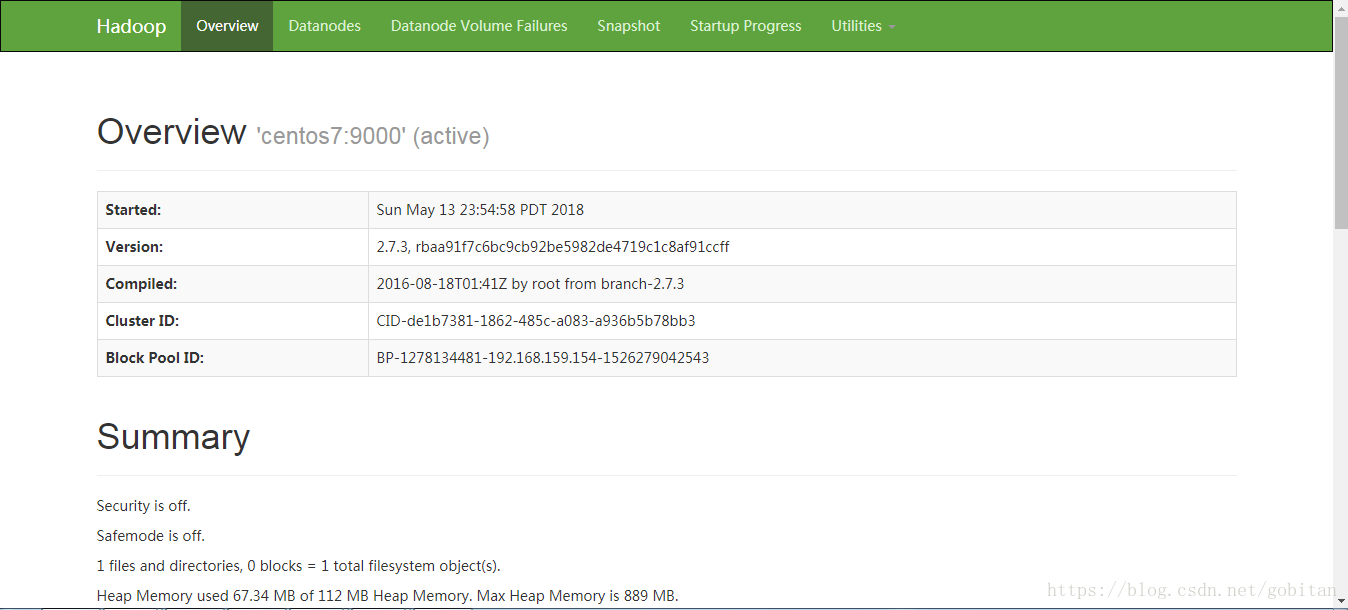
第七步:创建HDFS目录,以便执行MapReduce任务
[root@centos7 hadoop-2.7.3]# bin/hdfs dfs -mkdir /user
[root@centos7 hadoop-2.7.3]# bin/hdfs dfs -mkdir /user/test
第八步:拷贝输入文件到分布式文件系统
[root@centos7 hadoop-2.7.3]# bin/hdfs dfs -put etc/hadoop input
这里举例拷贝et/hadoop目录下的文件到HDFS中。
查看拷贝结果
[root@centos7 hadoop-2.7.3]# bin/hadoop fs -ls /user/test/input
第九步:运行Hadopo自带的例子
[root@centos7 hadoop-2.7.3]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+'
说明:
[1] 这个例子是计算某个目录下所有文件中包含某个字符串的次数,这里是匹配'dfs[a-z.]+'的次数。
[2] 中间有报如下错误,暂忽略。"18/05/14 00:03:54 WARN io.ReadaheadPool: Failed readahead on ifile EBADF: Bad file descriptor"
第十步:将结果从分布式文件系统拷贝到本地
[root@centos7 hadoop-2.7.3]# bin/hdfs dfs -get output output
[root@centos7 hadoop-2.7.3]# cat output/*
6 dfs.audit.logger
4 dfs.class
3 dfs.server.namenode.
2 dfs.period
2 dfs.audit.log.maxfilesize
2 dfs.audit.log.maxbackupindex
1 dfsmetrics.log
1 dfsadmin
1 dfs.servers
1 dfs.replication
1 dfs.file
或者直接查看
[root@centos7 hadoop-2.7.3]# bin/hdfs dfs -cat output/*
这里可以看到每个包含dfs的关键词在etc/hadoop的所有文件中出现的次数的统计。
第十一步:验证结果:
用linux命令来统计一下"dfs.class"的次数,结果为4次,与mapreduce统计的一致。
[root@centos7 hadoop-2.7.3]# grep -r 'dfs.class' etc/hadoop/
etc/hadoop/hadoop-metrics.properties:dfs.class=org.apache.hadoop.metrics.spi.NullContext
etc/hadoop/hadoop-metrics.properties:#dfs.class=org.apache.hadoop.metrics.file.FileContext
etc/hadoop/hadoop-metrics.properties:# dfs.class=org.apache.hadoop.metrics.ganglia.GangliaContext
etc/hadoop/hadoop-metrics.properties:# dfs.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
第十一步:关闭主程序
最后,如果使用完毕,可以关闭Hadoop。
[root@centos7 hadoop-2.7.3]# sbin/stop-dfs.sh
另外,还可以通过YARN来提交job任务。步骤如下:
第十二步:配置mapred-site.xml
[root@centos7 hadoop-2.7.3]# mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
编辑etc/hadoop/mapred-site.xml,修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
第十三步:配置yarn-site.xml
编辑etc/hadoop/yarn-site.xml,修改如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
第十四步:启动ResourceManager和NodeManager
注意:执行下面的命令之前,先确保已执行"sbin/start-dfs.sh"。
[root@centos7 hadoop-2.7.3]# sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.3/logs/yarn-root-resourcemanager-centos7.out
localhost: starting nodemanager, logging to /opt/hadoop-2.7.3/logs/yarn-root-nodemanager-centos7.out
第十五步:启动historyserver
[root@centos7 hadoop-2.7.3]# sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/hadoop-2.7.3/logs/mapred-root-historyserver-centos7.out
确认进程已启动
[root@centos7 hadoop-2.7.3]# jps
1670 ResourceManager
1272 NameNode
1769 NodeManager
1370 DataNode
2234 Jps
1501 SecondaryNameNode
1838 JobHistoryServer
[root@centos7 hadoop-2.7.3]#
第十六步:查看ResourceManager的Web界面
http://192.168.159.154:8088
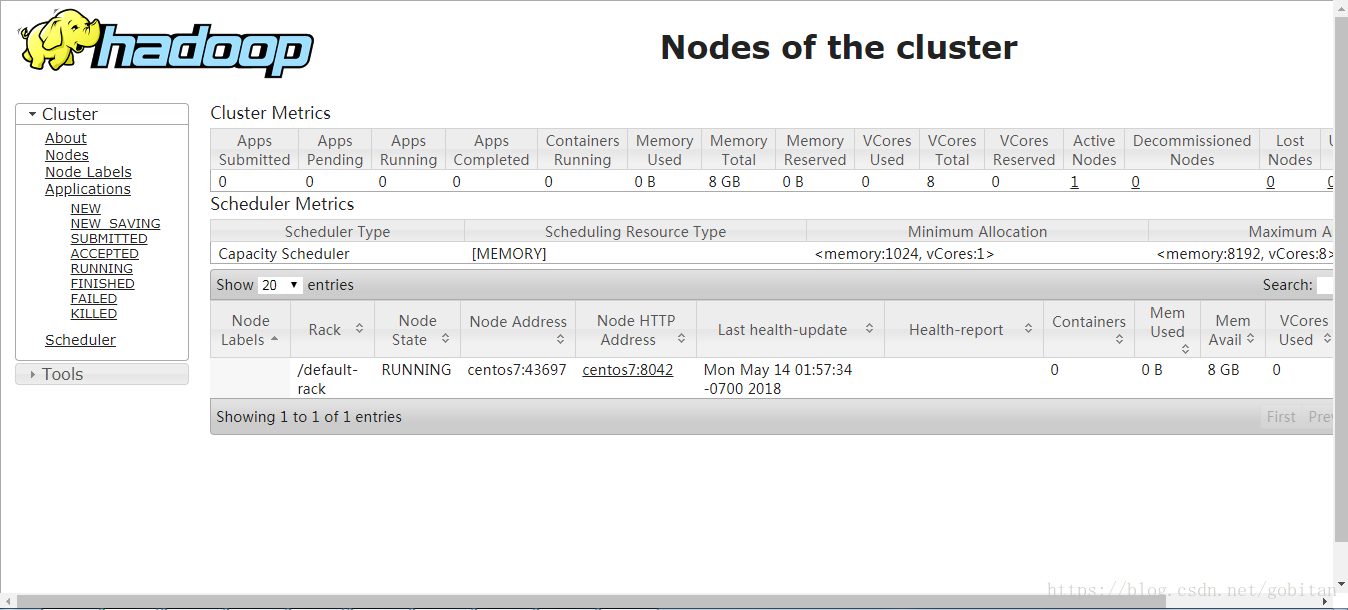
第十七步:查看Job History Server的web页面
http://192.168.159.154:19888/
第十八步:运行MapReduce job任务
跟前面的命令一样,但是我们将结果输出目录改为output-yarn,如下:
[root@centos7 hadoop-2.7.3]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output-yarn 'dfs[a-z.]+'
查看结果
[root@centos7 hadoop-2.7.3]# bin/hdfs dfs -cat output-yarn/*
可以看到结果与之前执行的一致,这里就不列出。
第十九步:停止YARN
[root@centos7 hadoop-2.7.3]# sbin/stop-yarn.sh
参考资料:
[1] http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/SingleCluster.html
[2] https://blog.csdn.net/gobitan/article/details/13020211 Hadoop2.2.0单节点安装及测试
[3] https://www.cnblogs.com/ee900222/p/hadoop_1.html
这篇关于Hadoop2.7.3单机伪分布式环境搭建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







