本文主要是介绍语音识别中MFCC频谱和如何得到频谱图的图示讲解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于语音识别 音乐识别中 MFCC频谱图如何得到的 最详细的视频
视频链接放在这里,求求你们愿意打开视频的话,就看一眼吧···是在b站上的 要是我入门的时候看到这个视频真的是幸福死了. 😃😃
链接: link
本来不想写关于模数转换、采样、傅立叶变换这些的,但还是记录一下吧。我是一下子get到了这个MFCC图是怎么来的,如果你已经知道了如何分帧,加窗,如何得到整个MFCC频谱图只需要直接看下面两张图,但还是建议看原视频,每一秒都是细节,都有知识点。
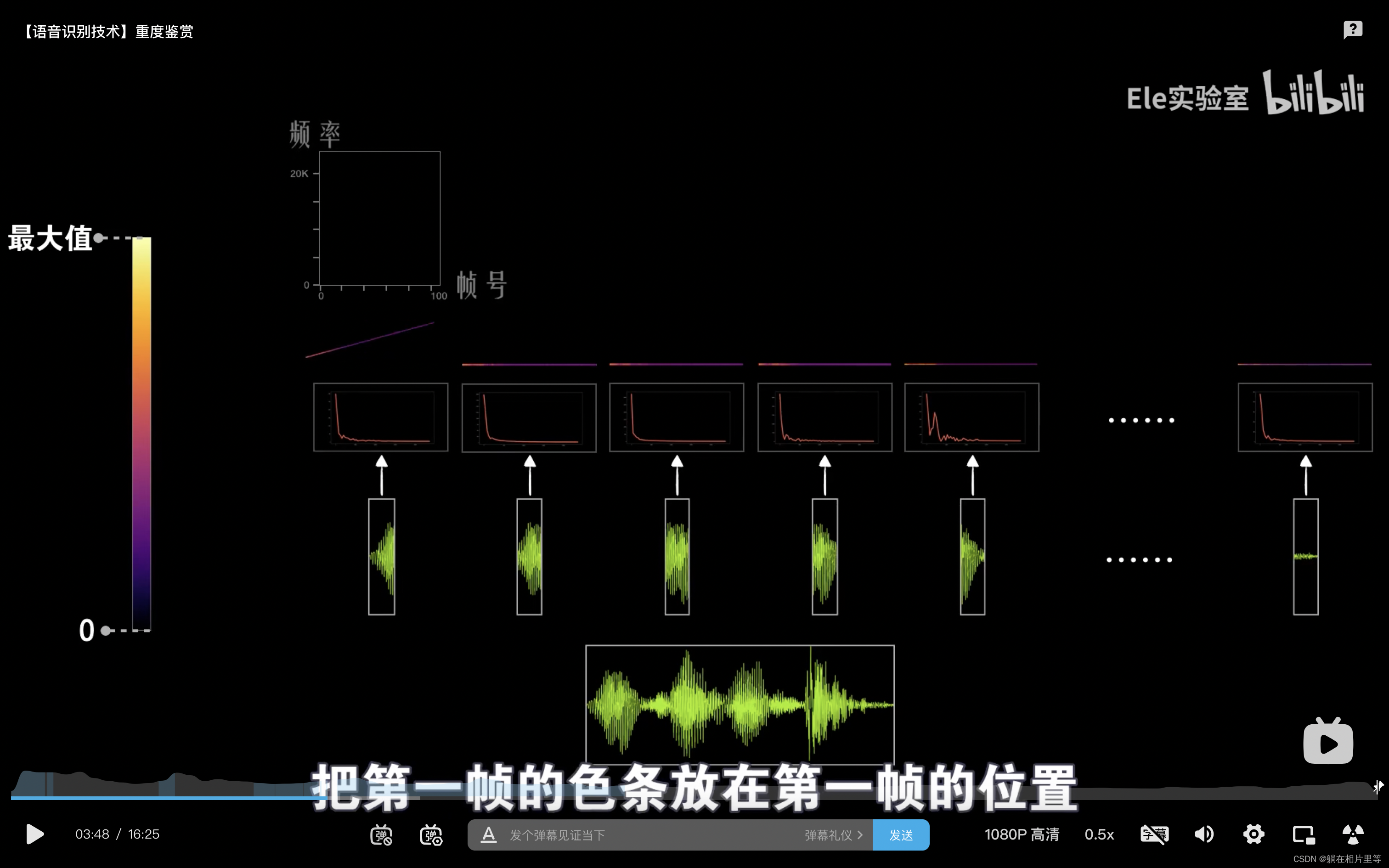
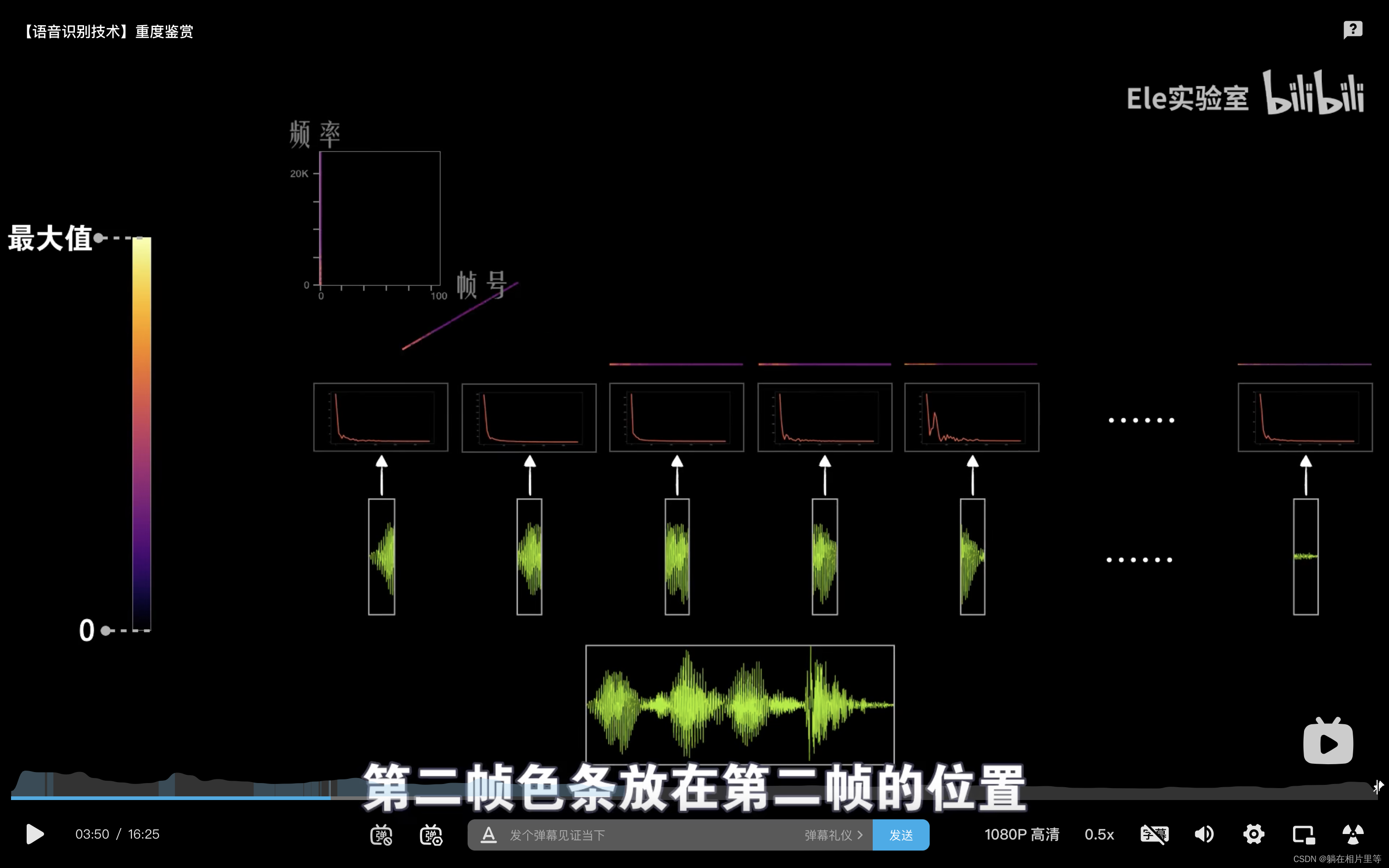
就是说,我们不会对整段语音信息进行傅立叶变换,所以就采用一个长度为25ms「一般使用的窗口长度,推荐在25ms-30ms」的窗口去截取语音信息,称为第一帧,间隔10ms进行第二帧的采样···这样1s的语音就切分成了100帧,然后分别对每一帧进行傅立叶变换。然后就是这一步!把这100帧的频谱放在一起,这个堆叠的方式之前一直不知道,建议看看视频。
采样
这里关于香农奈奎斯特采样定理{为了不失真地恢复模拟信号,采样频率应该大于模拟信号频谱中最高频率的2倍},所以采样频率选择我们人耳能够听到的最大频率『约20kHz』的2倍即可

这个采样后的转化过来的是声音的时间域表示,也称为声波图。其中横轴表示时间,纵轴表示声音的振幅或者功率。
声音的区分可以看作是频率的不同,虽然振幅大小也会变化,但是本质还是不变的,但是我们从这个声波图中并不能够看出频率信息,因此就需要转换到声音的另一种表述方式,频谱图。其中横轴表示频率,纵轴表示强度。
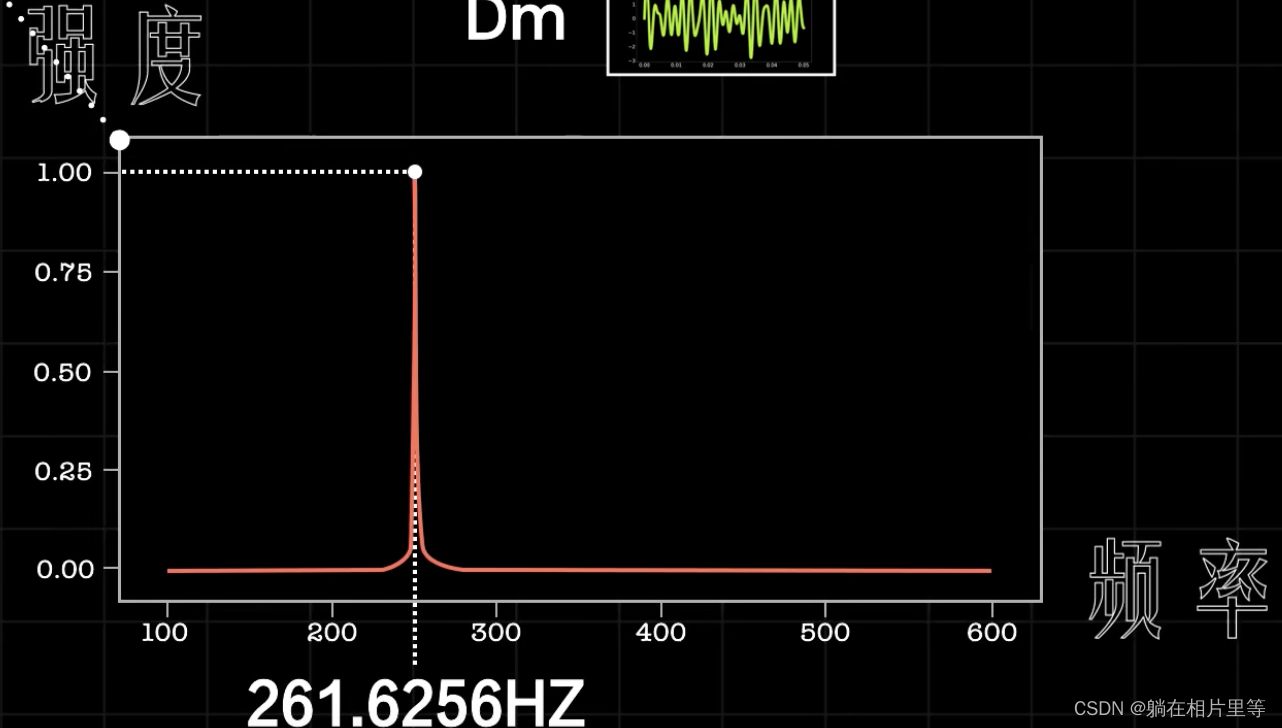
从声波图到频谱图的转换就是通过傅立叶变换得到的。
「一个声音信号可以是不同频率和强度信号的叠加」
下图的横坐标表示的是频率,纵坐标表示的是频率分量的强度,强度除了可以用纵坐标表示,也可以用颜色表示,因此就有一个颜色bar
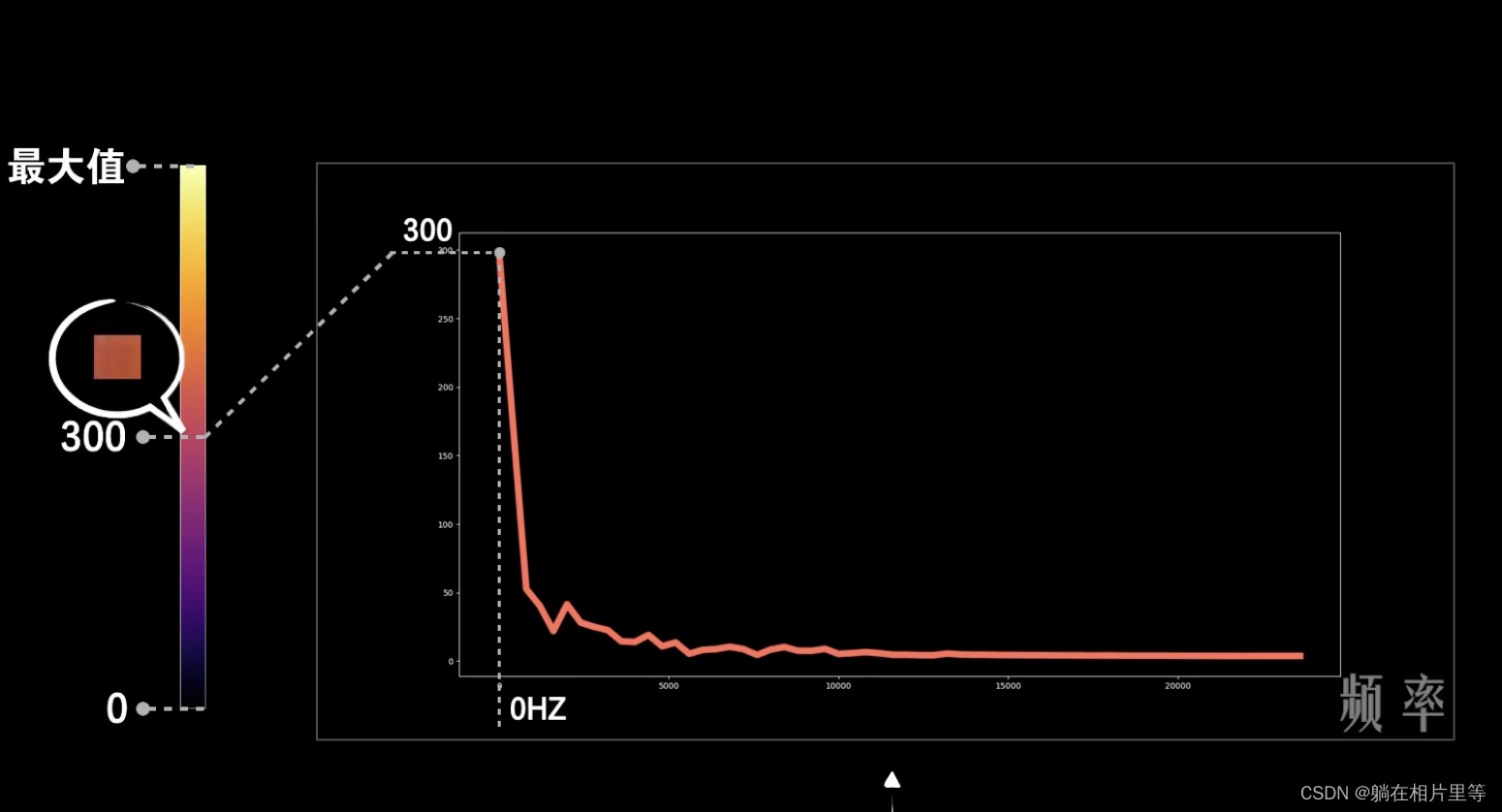
这样就可以把每个频率对应的强度表示出来
然后就得到了语谱图,这个图我们经常能够见到。

这里的横坐标表示帧号,纵坐标表示频率,颜色是表示信号的强度。
至此还未结束,上面只是得到了语谱图,我们一般使用MFCC频谱特征,其实就是多加了一些复杂的数学变换。
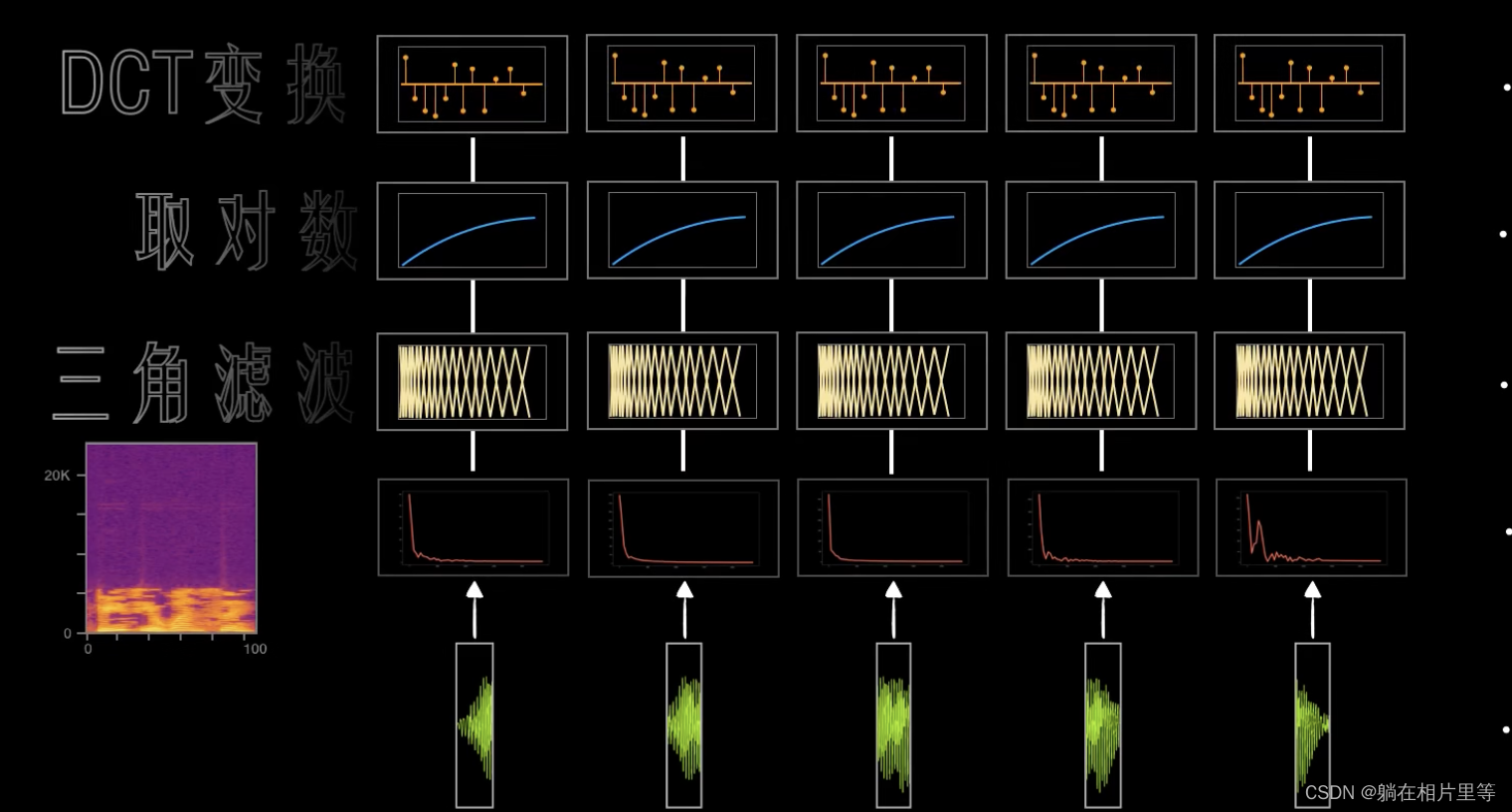
我们实际上还要对每一帧傅立叶变换后的结果进行三角滤波,再根据人耳听觉特性取对数,最后进行DCT变换「这整个过程称之为MFCC特征提取」。最终提取出来的效果是一个39维的特征向量「取一阶差分和二阶差分」,这才是我们需要训练的数据。
这个39维的也不知道是怎么算出来的🤷♀️🤷♂️
看librosa.feture.mfcc是由直接指定n_mfcc参数来弄,默认是20
那取一阶差分和二阶差分是20+19=39?
为什么不是19+18=37? 这部分我还不知道怎么在程序中体现验证?
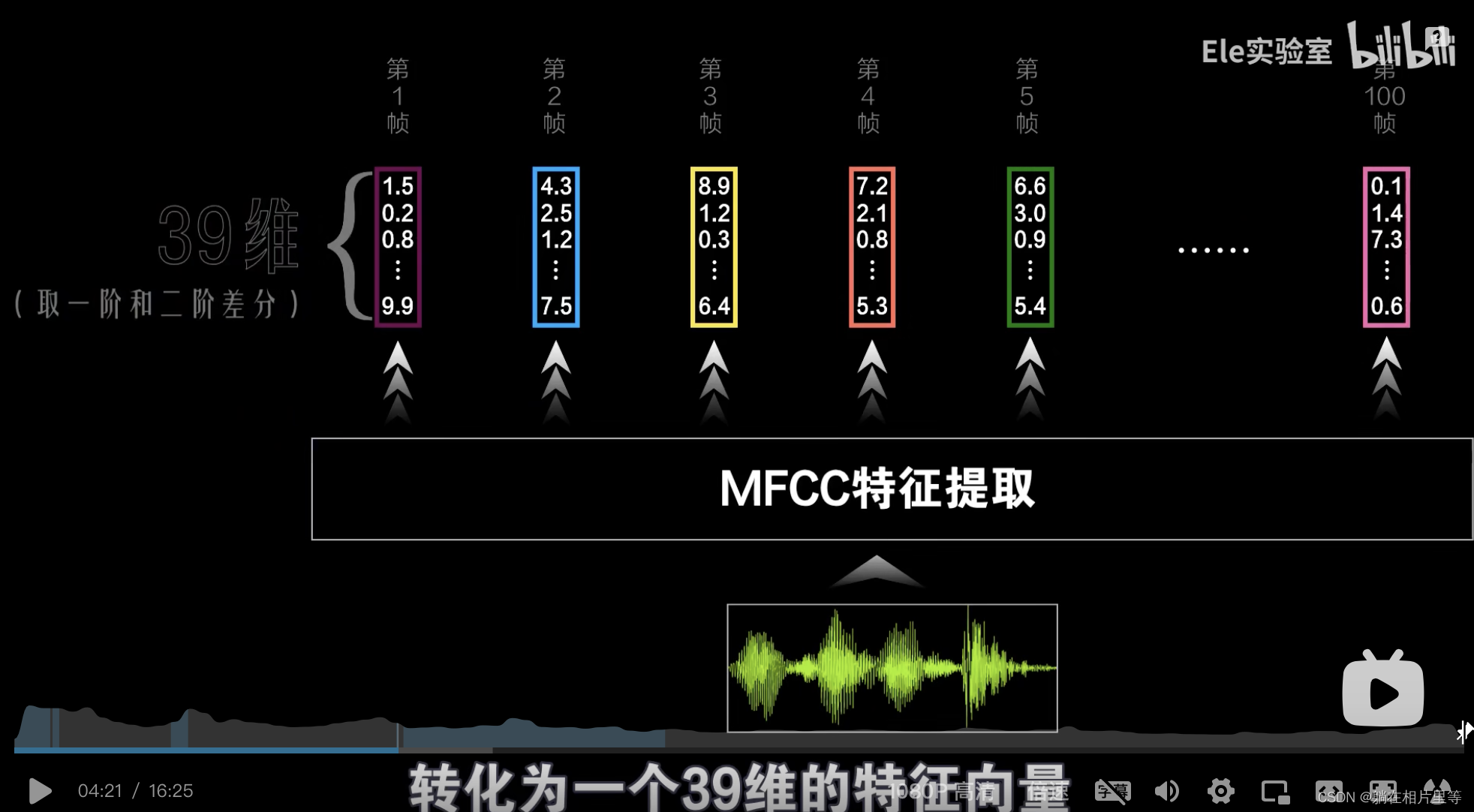
看到的关于librosa常用方法的示范,写得也很清楚规范。
https://www.cnblogs.com/LXP-Never/p/10918590.htmlMFCC系数实现
这篇关于语音识别中MFCC频谱和如何得到频谱图的图示讲解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









