本文主要是介绍Word Embedding 和 Word2Vec详细笔记(未完待更),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.单词的向量化表示
1.one-hot
比如有一个1000个词汇的词典,每一个单词可以表示为一个1000*1维大小的向量,其中一个位置为1,其余为0,并且每个单词的1的位置互斥。

不过这种表示方式存在很多问题:
- 任意两个词之间都是孤立的,根本无法表示出在语义层面上词语词之间的相关信息
- 如果词典非常大,那么每个单词的维度都是巨大的,这样会造成计算上的困难
- 其得到的特征是离散稀疏的,得到的向量过于稀疏,导致计算和存储的效率不高
2. distributed representation
它的思路是通过训练,将每个词都映射到一个较短的词向量上来,这些词向量就构成了向量空间。这个词的维度一般需要我们在训练时自己来指定。代表性的就是词嵌入(Word Embedding)。
一个单词“king”的词嵌入(在维基百科上训练的GloVe向量):
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 ,-0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234, -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
假如第一个维度代表富有程度,范围为0-100,越靠近0代表越穷,越靠近100代表越富有,然后把这个维度映射到-1到1的范围。这里面的每个维度的含义是通过学习出来的,具体的含义是不明确的.
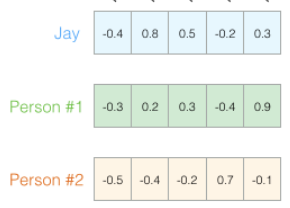
将这些含义用颜色来表示程度,如下示例:

可以看到“woman”和“girl”在很多地方是相似的,“man”和“boy”也是一样。
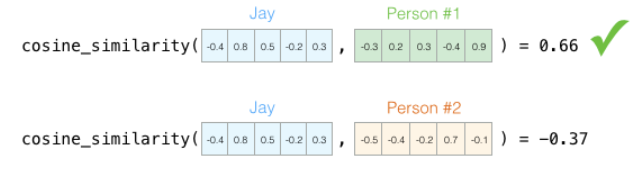
这样一来,相似单词的向量会映射到类似的空间。可以通过计算余弦相似度来计算两个向量的相似度。计算的结果越接近于1代表越相似。
二.神经网络语言模型
通过神经网络训练语言模型可以得到词向量,神经网络语言模型大致如下:
a) Neural Network Language Model ,NNLM
b) Log-Bilinear Language Model, LBL
c) Recurrent Neural Network based Language Model,RNNLM
d) Collobert 和 Weston 在2008 年提出的 C&W 模型
e) Mikolov 等人提出了 CBOW( ContinuousBagof-Words)和 Skip-gram 模型
三. Word Embedding
- Word Embedding是词的一种表示方式,属于Distributed Representation中的一类
词嵌入是自然语言处理(NLP)中语言模型与表征学习技术的统称。概念上而言,它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。
词嵌入的方法包括人工神经网络、对词语同现矩阵降维、概率模型以及单词所在上下文的显式表示等。常见的如:word2vec(Google), GloVe, wordRank,FastText(Facebook)。
词嵌入将文本通过一个低维向量来表达,不像 one-hot 那么长。语意相似的词在向量空间上也会比较相近。Word Embedding 的模型本身并不重要,重要的是生成出来的结果——词向量。

四. Word2Vec
1. 和词嵌入的关系
Word2vec 是 Word Embedding 的方法之一。
2. 和 CBOW、Skip-gram的关系
CBOW、Skip-gram等神经网络语言模型是逻辑上的方法,Word2Vec是实现CBOW、Skip-gram的工具。Word2Vec利用CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model)两种训练模式可以实现词嵌入。
3. CBOW
CBOW(Continuous Bag-of-Word Model)又称连续词袋模型,是一个三层神经网络,通过上下文来预测中间那个词。


注:gensim 和 google的 word2vec 里面并没有用到onehot encoder,而是初始化的时候直接为每个词随机生成一个N维的向量,并且把这个N维向量作为模型参数学习
4. Skip-gram
Skip-gram只是逆转了CBOW的因果关系而已,即已知当前词语,预测上下文。


4.1 模型数据准备
对一段文本设置滑动窗口,这里以5举例,中间的not设为输入,左右两个词为我们学习预测的目标。


4.2 训练过程
从数据集中的第一个样本开始。我们将特征输入到未经训练的模型,让它预测一个可能的相邻单词。然后将计算出的向量和目标做差得到loss,然后反向更新参数矩阵.

四.负采样(以Skip-gram为例)
考虑到模型第三层为softmax激活,softmax公式如下:
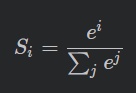
对于Skip-gram而言,当我们将需要在数据集中为每个训练样本都做一遍需要的计算是巨大的。
我们转换一下形式:
将其切换到一个提取输入与输出单词的模型,并输出一个表明它们是否相似的分数(0表示“不相似”,1表示“相似”)。


这样我们的计算就变成了逻辑回归模型,计算程度大大减少。
我们的数据就变为了这样:

但是如果这样拿到网络里去训练,因为所有的输入数据都是相似的,准确性是百分百了。为了解决这个问题,我们引入负样本。负样本的单词从词汇表中随机抽取单词。

五.Hierarchical Softmax(以CBOW为例)
对于网络的激活层softmax,如果词典过大比如10w,那么softmax的计算将是灾难级的。为了避免一次计算这么多,采用分层softmax的方式可以有效减轻计算量。



在word2vec中,约定编码方式左子树编码为1(代表负类),右子树编码为0(代表正类),同时约定左子树的权重不小于右子树的权重。简而言之,就是将一个节点分类时,分到左边就是负类,分到右边就是正类。
Huffman树中每一叶子结点代表一个词向量,非叶结点中存储的是中间向量,对应于神经网络中隐含层的参数,与输入一起决定分类结果。
下面引用softmax中的数学原理中的例子解释:




参考:
https://blog.csdn.net/weixin_40444270/article/details/109434553
https://blog.csdn.net/yu5064/article/details/79601683
https://blog.csdn.net/lilong117194/article/details/81979522
https://blog.csdn.net/u014595019/article/details/51884529
https://blog.csdn.net/longxinchen_ml/article/details/89077048
https://www.cnblogs.com/peghoty/p/3857839.html
https://zhuanlan.zhihu.com/p/84301849
https://blog.csdn.net/qq_38890412/article/details/107658406
这篇关于Word Embedding 和 Word2Vec详细笔记(未完待更)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





