本文主要是介绍听小董谝存储 八,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
序章
Dispatcher
Mover
几个问题
我爱glt
序章
前面几章,其实已经把这个存储系统的核心模块说清楚了。但是一些附属模块,例如dispatcher与mover还是没有讲。这一节,作为整个系统的最后一篇,就说说这两个模块。
Dispatcher
其实整个dispatcher的功能很简单的,就是发现集群里面的不稳定因素,然后找人处理而已。
那么具体什么情况算是不稳定因素呢?
- 某个datashard的体积太大(单个datashard理论上可以达到一个卷的体积那么大)
- 某个particle或者某个卷dead
- 某个业务用的datashard太多了,需要合并
- 某个业务用的datashard太少了,读写性能不够,需要分裂
- 某组机器上占用的体积超过、少于平均值n个百分点
发生类似上面的情况,就说明数据需要发生搬迁分裂合并等操作了,然后dispatcher就计算应该几个并发,在不影响现网读写的情况下,指挥mover进行数据搬迁分裂合并。
完了,dispatcher的功能就是这么简单。那么再问一句,它所需要的原始数据从哪里来呢?答案就是Master。
Mover
前文已经不止一次说了mover的功能就是进行数据搬迁分裂与合并。
那咱们就以搬迁为例,说说它具体怎么操作。如下图一,就是particle的简略写数据流程。
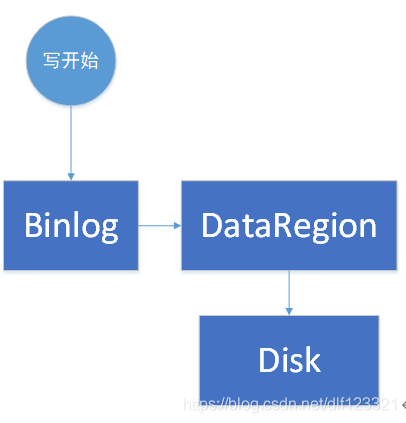
图一 particle简略的写流程
具体搬迁的时候,Mover只需要把历史数据搬迁走就OK了,新增数据protal那一层已经采用了双写模式,不用担心。那具体的历史数据怎么读取呢。直接把要搬迁的data shard所属的block打包搬迁走就OK了。如下图二。
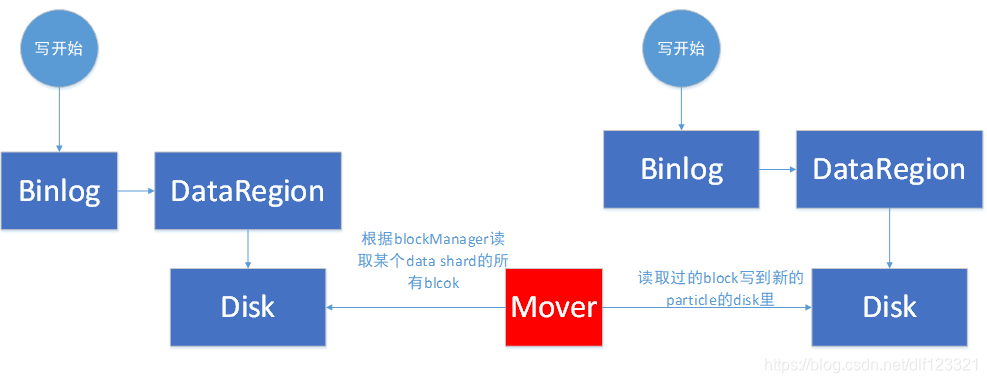
图二 Mover执行搬迁任务
新的机器那边,收到一个block后,先放到自己的磁盘里,然后把里面的每一个值都解析一下,反向更新到索引节点里。
那搬迁什么时候算是个头呢?老的机器那边数据一直在下刷,一直有新的block产生。
那就在搬迁的过程中,禁止这个data shard的DataRegion下刷。
这样一来,历史的数据占据了几个磁盘里面的block就是确定的了,终归是能搬迁完的。
几个问题
- 可是如果搬迁需要很长时间,然后数据又一直写,dataregion的长度不够了怎么办?
我们设定了搬迁的最长时间,绝大多数的data shard在这个时间内都能搬迁完成。
- 那如果就是有一个data shard写入的速度很快,时间就是不够怎么办?
首先,因为整体的路由是经过hash的,所以data shard的写入频率是和它负责的区域长度相关的,如果一个data shard负责的范围太大,前面的dispatcher就会识别到这种问题,先一步进行数据分裂。如果真的dispatcher出问题了,导致有一个data shard的增长速度特别快,在给定的时间内不能搬迁完成,那就只能手动调整搬迁时间了。
这篇关于听小董谝存储 八的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





