本文主要是介绍听小董谝存储 三,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
序章
第一章 Master的功能
第二章 资源管理
2.1 上下架particle
2.2 上架portal
2.3 上架dispatcher与mover
第三章 业务管理
第四章 路由管理
4.1 data shard的数据结构
4.2 data shard的生命周期
4.3怎么知道路由变更了
4.4变更了之后,怎么做
4.5 保证各个portal路由一致
序章
前面两章基本上只是告诉了大家一个存储系统最顶层的模块与路由是什么样子的,但是具体各个模块都是怎么工作的我们依然一无所知,从这一章开始,我们就依次深入了解一下Master,Portal,Particle都是怎么工作的。
这一节 我们先了解一下Master
第一章 Master的功能
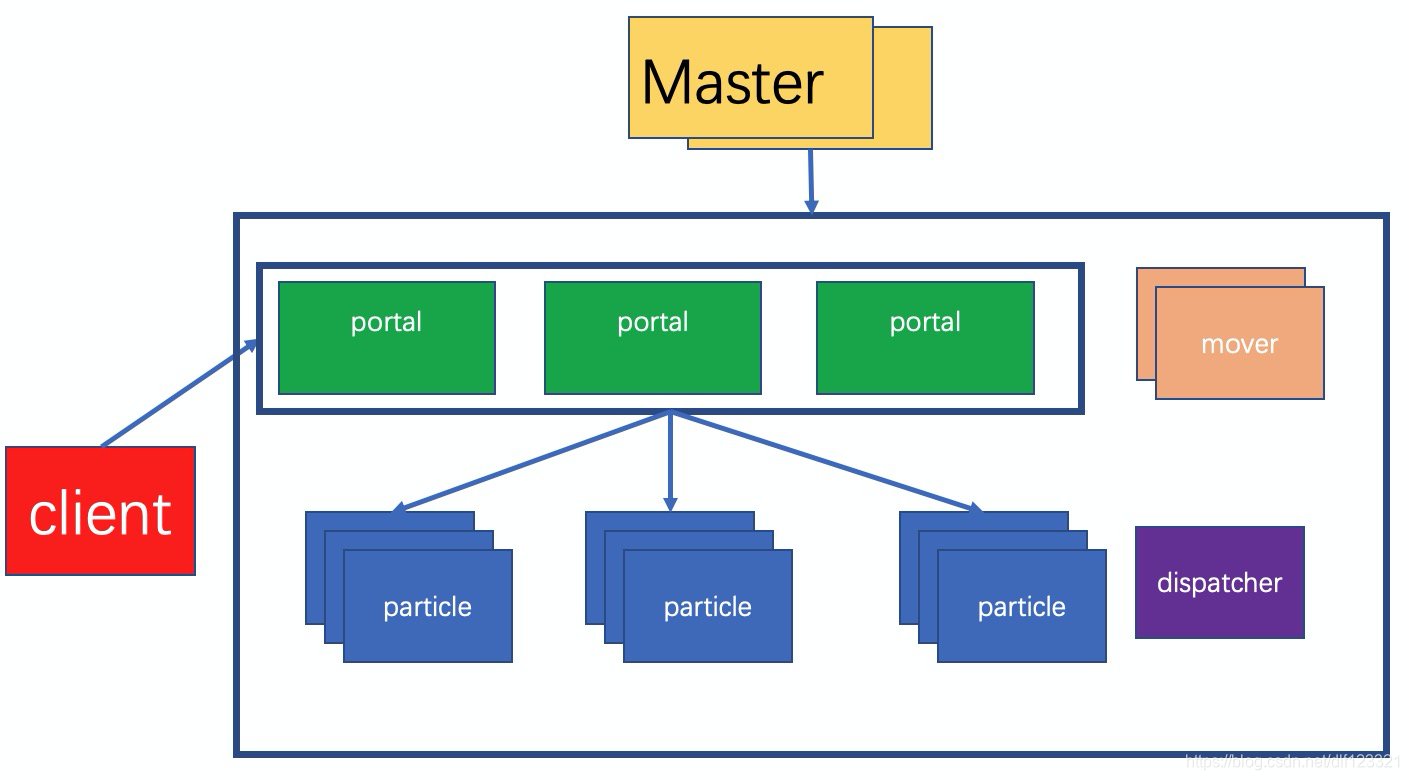
图一 整体框架
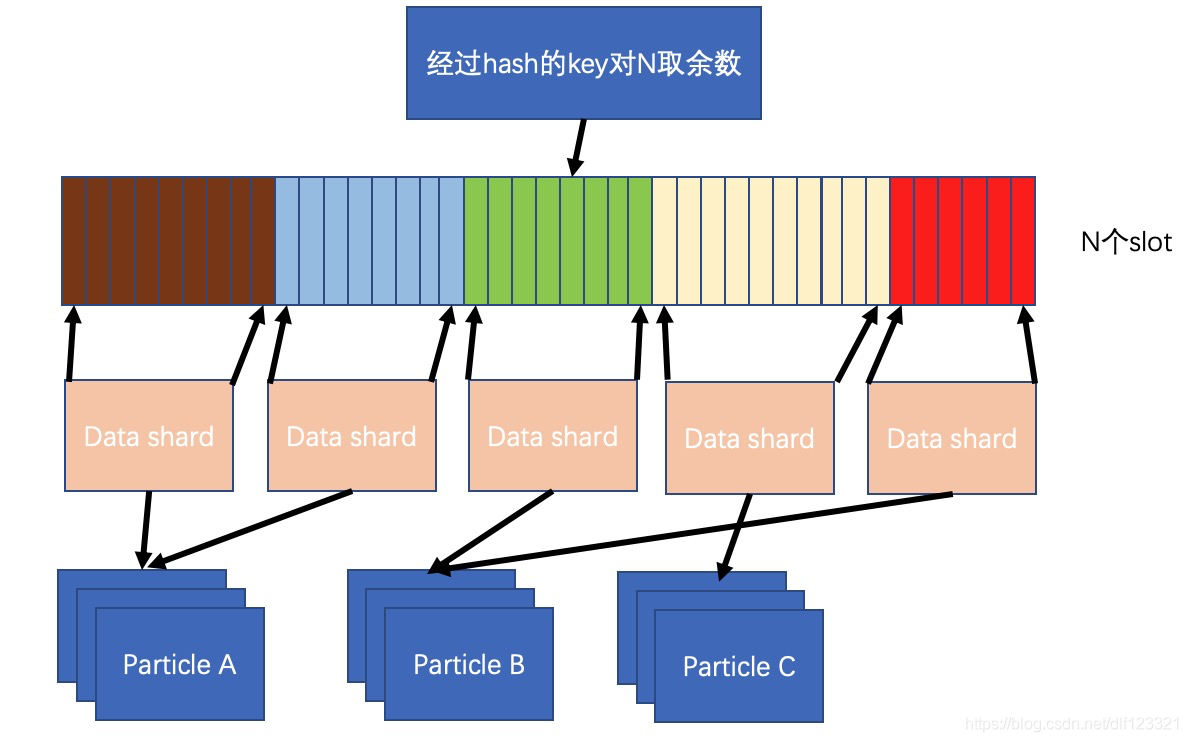
图二 路由样式
老鸟:小菜,图一图二就是前面两章的总结。咱们这一节说的是Master模块的功能。那么第一步,咱们就得先总结出Master都有哪些功能。你先谈谈你的看法吧。
小菜:首先从图一来看,master管理了全局各个模块,那么首先master应该有资源管理的功能。换句话说,Portal,Particle的增加与删除都应该由Master管理。然后,业务管理。也就是说为某个用户新增一个业务/删除一个业务,也需要通过Master。既然有业务管理,那么那个业务的路由管理肯定也是Master的职责了。我大概就能想到这么多了。
老鸟:嗯基本也就这3个功能了。咱们开始吧。
第二章 资源管理
老鸟:说到资源管理,那咱们就先明确一下什么叫资源。看图一来说,整个集群里除了master外,所有的模块都是资源,都归Master管。
OK,咱们再明确一下整个集群里各个模块的功能。
Master:统一管理集群内的资源,业务与路由。
Portal:做用户请求的转发。
Particle:具体的存储数据。
Dispatcher:探测集群内是否需要数据搬迁合并分裂的场景,如果有,把任务分配给Mover。
Mover:根据Dispatcher分配的任务,执行具体的数据搬迁分裂合并工作。
2.1 上下架particle
老鸟:首先前文已经说了,为了保证数据安全性,咱们的一组Particle是按照一主两副部署的。所以每次上架机器的时候也都是3台服务器一起部署的。对Master来说,并没有对外暴露上下架particle的功能,反而是化整为零,把这一组机器划分成n个volume(卷)每个卷都是一个固定的大小,然后循环调用上下架卷的功能。
小菜:你说化整为零,为什么不能直接上架整机呢?
老鸟:作为具体存储数据的模块,咱们的particle是可以采用多种机型的。有的机器是12个磁盘,每个磁盘300G;有的机器是4个磁盘每个磁盘3000G。如果按整机上下架,那么master那边就得区分不同的机型,但是反过来如果按照卷来计算,就屏蔽了存储机型差异对master的影响。对master来说,数据是存储在一个一个卷上面的,每个卷都有他自己的编号。(如下图三,两种机型,有不同的卷数)
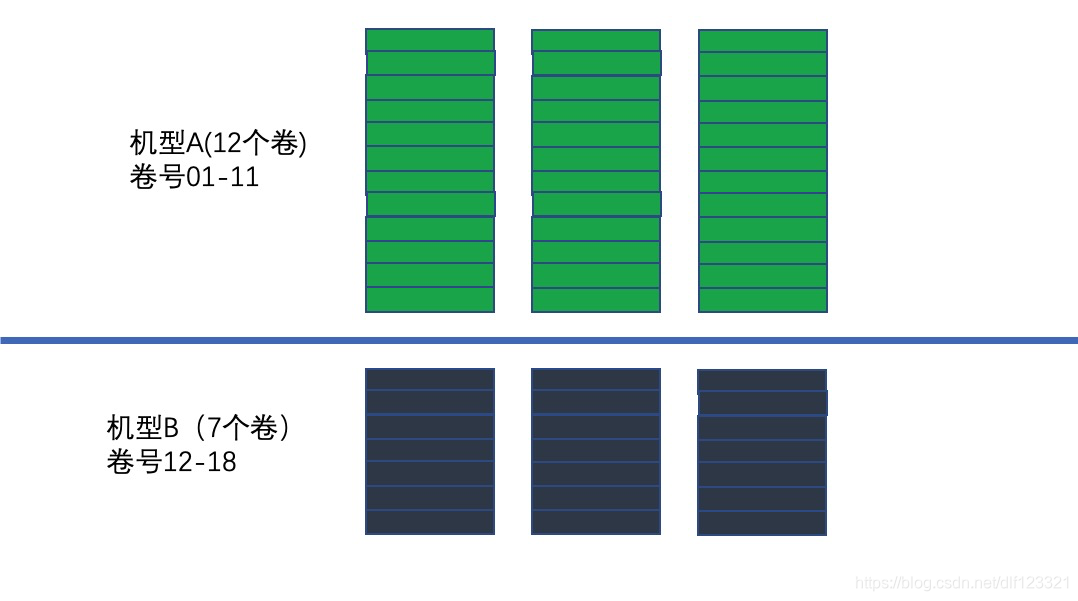
图三 不同的机型 提供不同数量的卷
小菜:master把particle层次的整机打散成一个个的卷,那么一个个卷下面还有没有别的层次?
老鸟:有的。还记得之前说的data shard么。对master来说,不同的机型提供不同数量的卷,每个卷的大小都是一样的。同时每个卷又能提供固定数量的data shard。Data shard,卷,particle,整个集群的概念可以类比真实世界里的仓库。
Master就是仓库的厂长。Particle就是一个个厂房。一个仓库可以有多个厂房,厂房的面积有大有小,每个厂房里面可以摆放不同数量的货架,这个货架就是data shard。所有的货架的容量都是相同的。每个货架上都摆着相同数量的货篮。货篮是厂长进行数据管理的最小单位,而这每一个最小单位都是由(货架编号,货篮编号)这个二元组来唯一标识的。
小菜:层级关系我懂了,那么每个货篮是怎么存放货物的呢?
老鸟:这个是整个存储系统的核心,这个问题你先记着,咱们后面讲到particle模块的时候再说。
2.2 上架portal
上架portal就比particle简单多了,在master注册一下portal,同时把路由推送给portal就OK了。
2.3 上架dispatcher与mover
上架着两个组件比portal还简单,光在master注册一下就OK。
第三章 业务管理
老鸟:所谓的业务管理,说白了就是每次新来一个客户master给他分配data shard并记录的过程。
小菜:没听懂。
老鸟:依然用上面的仓库举例。村东头的王大妈找到仓库的厂长,说需要10个货篮放鸡蛋。村西头的李大爷要13个货篮放自己产的苹果。然后厂长就遍历一下自己管理的所有货架,看看那些货架比较空闲,挑出来还没有被用的货篮分配给二老就OK。所谓的业务管理说白了就是分配并关联data shard与业务的过程。
第四章 路由管理
小菜:路由管理都是具体管理什么呢?
老鸟:其实我也很不喜欢这个路由这个词,有时候是名词,有时候是动词,有时候还能是形容词。但是在这里,它的语义就是保证各个portal的路由状态一致,同时也记录了particle里面每个data shard的状态。
小菜:听得很模糊。
老鸟:没事。咱们慢慢说。先说说data shard的状态。这个很容易理解吧,新上架的particle里面的data shard 还没有分配给用户使用,后面分配给用户使用,后面还有可能particle服务器断电导致数据不可访问,这么多现实情况,data shard肯定也是有不同的状态与之对应的。Data shard这些不同的状态我们一般叫它生命周期。
4.1 data shard的数据结构
小菜:说了这么多一个路由到底是个什么数据结构呢?
老鸟:你觉得呢?
小菜:一个路由指明了某一段槽位里面的数据应该存储到哪些机器的哪个卷的哪个data shard。【slotStart, slotEnd, particleIp1, particlePort1, particleIp2, particlePort2, particleIp3, particlePort3, volumeId, shardId】如何?
老鸟:很OK,很直观。如果某个业务有1w个dataShard,那这个业务的路由就是一个list,list里面每个元素都是上面那个结构,list的长度是1w。对吧?
小菜:是这个意思。
老鸟:假定槽位总数是100w,如果某个key经过hash后对100w取余,结果是317856。请问时间复杂度是多少?
小菜:O(N),感觉方案不行呀。
老鸟:顺序存储只能是数组形式么?为什么不试试跳表呢?
小菜:好棒,那这样就可以把时间复杂度降低到O(logN)
老鸟:如果datashard 发生了分裂,路由该怎么变化?
小菜:好像有点麻烦哦。。。。
老鸟:所以简单点,如果有1w个data shard,那么就申请一个长度为100w的数组,【0,99】存储的值都指向1号data shard,【100,199】存储的值都指向2号data shard……这样一来查找的时间复杂度就变成了O(1)。同时data shard的分裂合并都简单了直接改对应槽位的data shard编号即可。这就是用空间换时间,换效率的思路。
4.2 data shard的生命周期
Data shard完整的生命周期是比较复杂的,精简后大概就是如下几个状态间的跳转。
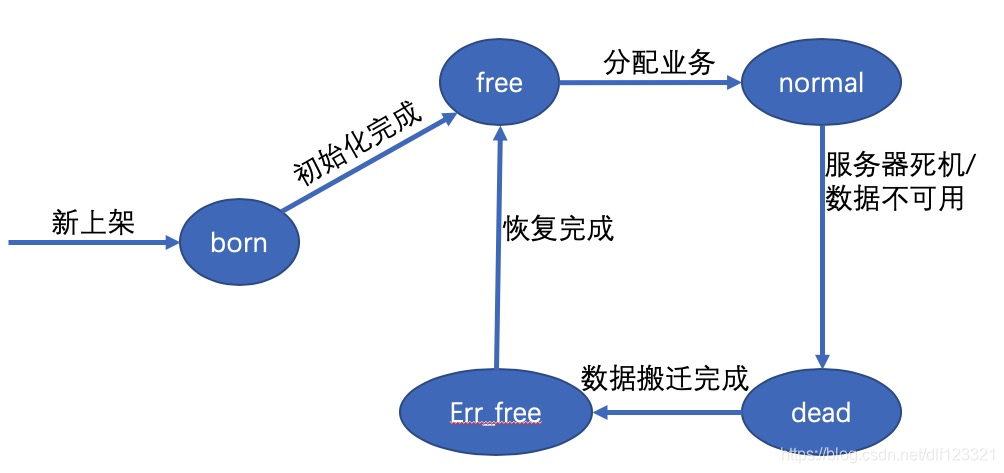
图四 data shard的生命周期转换
老鸟:首先我说明一下,同一个particle有一主两副共3个副本。因此一个data shard也有3个副本,那么自然每个副本也都有自己的状态了。Born是个中间状态,新上架的data shard初始化完成前是born,完成后就是free了。
Free:表明这个卷上的data shard已经是可用状态了。Master可以把它分配给某个业务使用了。
Normal:表明业务正在使用。是正常状态。
Dead:如果正在使用的particle忽然断电,或者断网等情况而导致数据不可访问,那么master就把把datashard的状态改成dead。Dead的数据是不能被访问的。这个不能一方面是指网络或者电源断了,没法访问。第二也是不应该访问,即使网络又恢复了,在断网的这一段时间里数据并没有更新到这个副本上,可能存在脏数据,因此也不应该被访问。
Err_free:当数据变成dead,那么也就意味着3个副本里,最多只有2个normal了。2个normal自然比3个normal危险一些,那么就需要进行数据搬迁,dead的data shard里面的数据都搬迁走了之后,dead就变成了err_free状态了。这个状态的意思就是说,我里面的数据虽然已经不完全了,但是在别地方已经有新的数据了。
小菜:如果particle真的发生了类似断电的情况,那么数据具体怎么搬迁呢?
老鸟:不要着急,这是portal层考虑的问题。另外图四只是最常见的data shard状态跳转,有一些不常见的情况,为了方便大家理解就没有画到图里。
4.3怎么知道路由变更了
- 有一个组件会循环的ping各个particle,如果在一定周期内,某个机器多次ping不通,就任务它dead了,组件就会上报到master
- 当particle出现某些问题后(非断电或网络问题),用户请求失败,portal就会打印错误日志。有一个组件会扫描portal的日志,当某个particle机器上的请求失败率超过某个比例,就任务这个机器dead了,组件就上报到master
- Particle机器上本身就部署着一个组件,它循环扫描机器的硬件情况,包括内存,cpu,磁盘ip等等信息,当发现异常信息后,就上报给master,让master把这个机器置dead。
4.4变更了之后,怎么做
Master先修改自己保存的路由,然后通知particle设置服务不可用。
4.5 保证各个portal路由一致
老鸟:我们知道master在整个集群中的作用主要是“管理”,用户的请求路径并不直接通过master。用户请求的是portal,那么现在master的一个功能就是得把路由信息推送给portal。
小菜:如果有多个portal,master修改了自己的路由后,然后也通知了particle设置了服务不可用。然后遍历portal把新的路由推送给他们就OK么。那么master怎么知道推送完成了呢?
老鸟:引入路由版本号。
小菜:明白了,每次路由变更的时候master都把自己的版本号加1。然后推送。
老鸟:是的。其实在保证路由一致这块的逻辑里,master与portal就是保持心跳连接
1 master问,亲爱的portal,你的版本号是多少?
2 portal回复master,自己的版本号。
3 master把收到的版本号和自己的最新版本号比较一下。如果一样,就说明一切OK,等一会再问问就OK。如果不一样,就说明master这边有更新了,然后推送一部分路由过去。
4 portal收到路由后更新下自己的版本号,然后再把新的版本号回复给master
5 master再检查一下版本号。如果一致说明一次同步就已经把路由都推过去了。如果不一致,说明还没有同步完,再重复3 4 5的步骤。
小菜:有个问题,portal路由的同步是master单线程遍历操作的,那如果某个portal还没有收到某个particle已经被置dead的路由,这个时候请求又通过这个portal被导入那个particle,那不是读到脏数据了?
老鸟:请参与4.4的后半部分。另外我乏了,跪安吧。再另外:我爱glt。
这篇关于听小董谝存储 三的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





