本文主要是介绍使用Python爬虫批量抓取PubChem化合物信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我本科是学生物工程的,研究生转到经济学,但是周围也有很多学生物和医学方面的朋友,经常帮他们抓取一些数据。最近帮他们抓取pubchem上的一些数据,pubchem是一个开放的数据库,爬起来难度不是很大,网上也有一个库叫pubchempy,之前也用来抓取过化合物的结构信息。今天主要是来看看如何通过网站的api来自定义抓取。
首先打开网址:https://pubchem.ncbi.nlm.nih.gov/
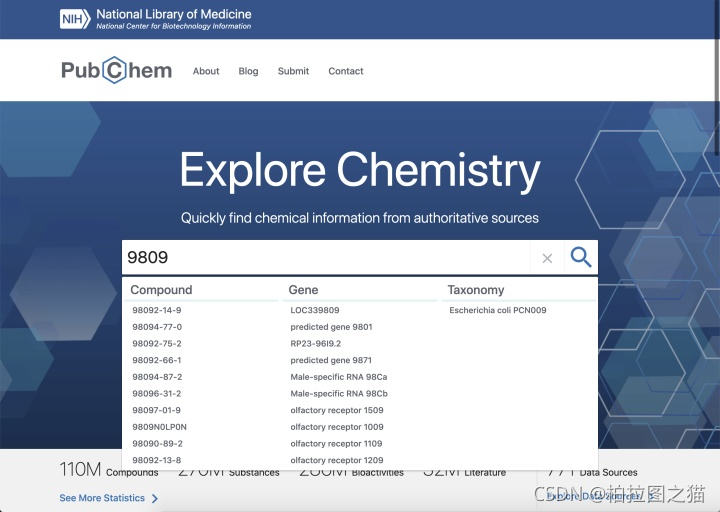
通过cid来搜索,输入9809
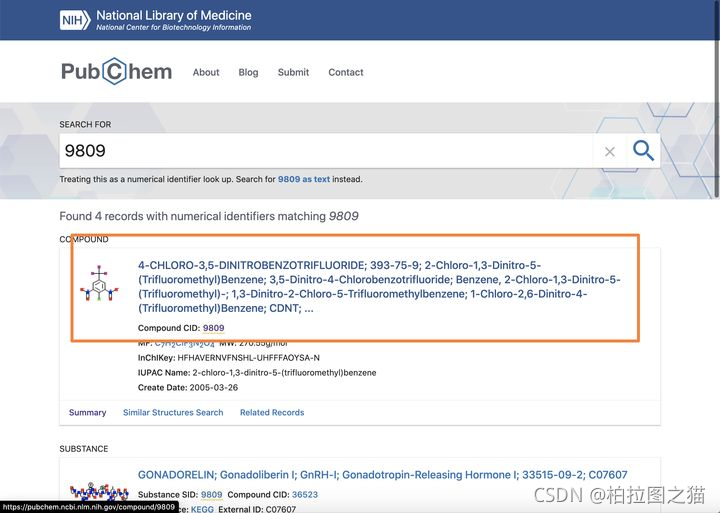
进去之后获得这个地址:https://pubchem.ncbi.nlm.nih.gov/compound/9809
比如我们想抓取化合物的Chemical and Physical Properties信息,点击右侧的Chemical and Physical Properties,然后点击全屏。
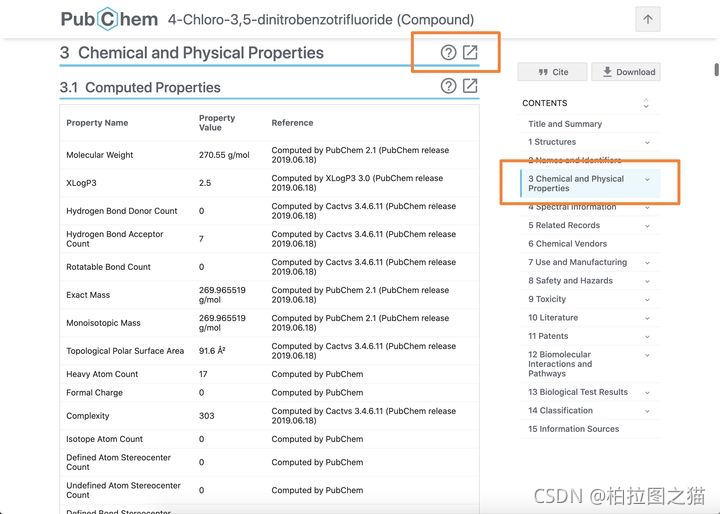
进入到下面这个页面后,右键 检查(推荐使用谷歌浏览器)。
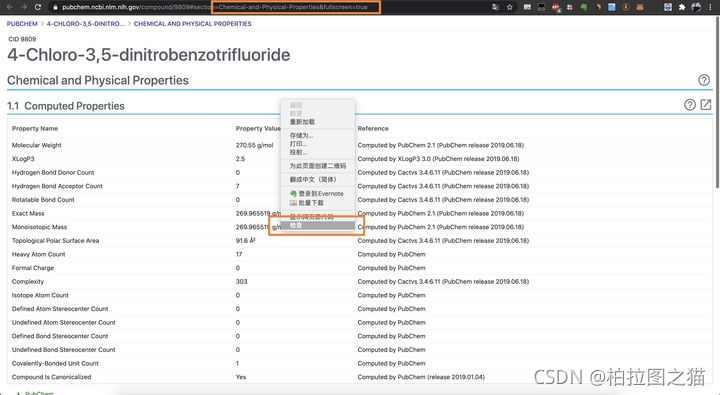
然后点击 Network,之后刷新页面。
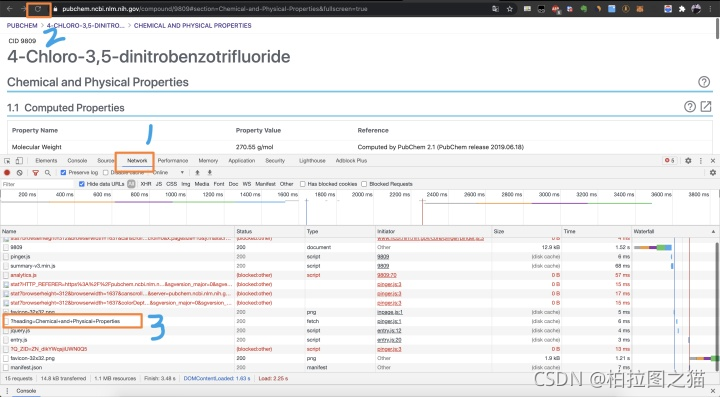
然后在里面找到一个带有?heading的连接,点开看看,就可以找到数据的api地址,然后复制出来,新开一个页面打开。
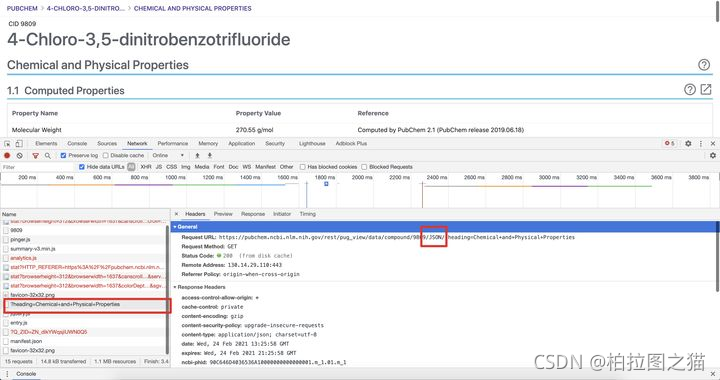
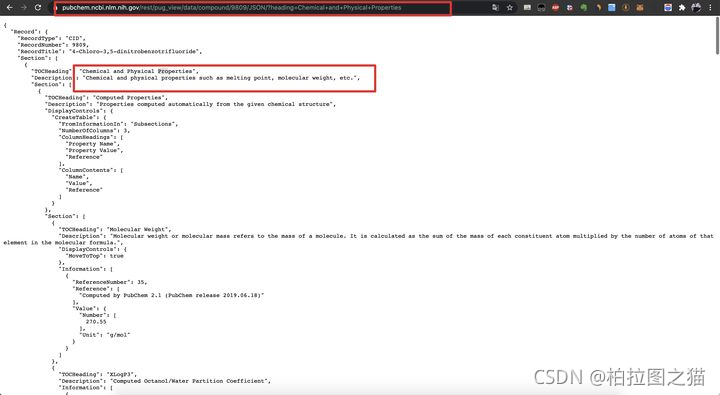
这个页面里面的数据就是该化合物的Chemical and Physical Properties数据,这个json的层特别多,需要慢慢解析,具体看代码。
import pandas as pd
import numpy as np
import json
import requests
import time cid = 9809
url = f'https://pubchem.ncbi.nlm.nih.gov/rest/pug_view/data/compound/{cid}/JSON/?heading=Chemical+and+Physical+Properties' req = requests.get(url)
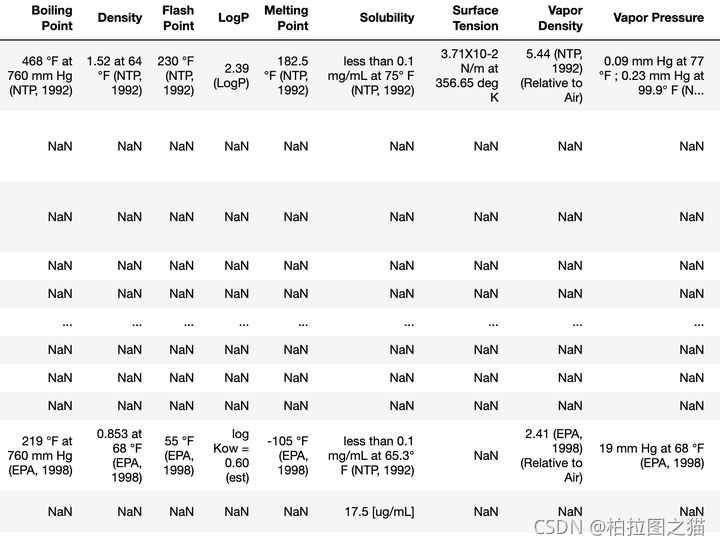
req proper_json = json.loads(req.text) proper_json['Record']['Section'][0]['Section'][0]['Section'][2] Section = proper_json['Record']['Section'][0]['Section'][1]['Section'] for i in range(len(Section)): print(Section[i]['TOCHeading'], ': ', Section[i]['Information'][0]['Value']['StringWithMarkup'][0]['String']) # Physical Description : 4-chloro-3,5-dinitro-alpha,alpha,alpha-trifluorotoluene appears as yellow crystals. (NTP, 1992)
# Melting Point : 133 to 136 °F (NTP, 1992)
# LogP : 2.5 (LogP)
如果有很多cid,那写个循环再加个解析存为excel格式就好了。
简单案例如下:
如果需要PubChem批量抓取数据服务的同学可以Q我,977728597。
或者到这里:
Puchem化合物数据批量抓取采集_宝典_教程_Python爬虫
这篇关于使用Python爬虫批量抓取PubChem化合物信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





