本文主要是介绍【深度学习基础】Pytorch框架CV开发(1)基础铺垫,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨
📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】
📢:文章若有幸对你有帮助,可点赞 👍 收藏 ⭐不迷路🙉
📢:内容若有错误,敬请留言 📝指正!原创文,转载请注明出处
文章目录
- 简单介绍下Pytorch
- Pytorch基础
- 张量
- 创建张量tensor
- 自动梯度
- 线性回归
- 逻辑回归
- 人工神经网络
- 感知机
- 反向传播
- Pytorch中的基础数据集
简单介绍下Pytorch
深度学习框架的作用:通过深度学习框架搭建神经网络;
什么是Pytorch?:Pytorch是Facebook的AI研究团队开发,以python优先的深度学习框架。
tensor的作用:tensor是Pytorch中最基本的构建,能够像Numpy一样进行矩阵运算,同时支持GPU加速。亦可以与Numpy相互转换。
tensor学习的重点:重点是tensor的操作和数学运算,难点是variable和自动求导。
tourch包括两种操作:
1.数学运算,这个跟python中的数学运算一致。
2.高级操作导入Pytorch的方法:import torch
Pytorch基础
张量
什么是张量:Pytorch中任何数据都是张量,分为一维和多维张量,其中三维张量就是图像。
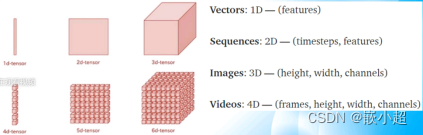
创建张量tensor
创建空张量:a=torch.empty(2,3)或是a=torch.zeros(2,3)
创建随机张量:a=torch.random(3,3) 创建自定义张量: a=torch.tensor([1,2,3,2,4,4])#一维
a=torch.tensor([[1,2,3],[2,4,4]])#二维张量算术运算:规则跟数组一样,相±,形状必须一样;*/要求参考数组的表达。 例如: C=a.add(b)
xy=torch.matmul(x,y)张量形状变换:使用view函数,张量名2=张量名1.view(新形状) 查看张量形状:张量名.size() 张量与数组之间的数据转换:
张量转成数组:数组名=张量名.Numpy() 数组转成张量:张量名=torch.from_Numpy(数组名)张量可以理解为矩阵。 张量里面的review跟数组内的reshape一样。 matmul翻译为矩阵相乘
自动梯度
什么是自动梯度:就是自动求偏导数,计算梯度就是计算偏导数。
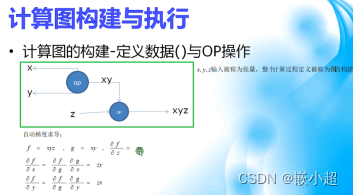
如何计算梯度:使用函数backward()
例如:

输出结果的作用:帮助调整输入,也就是深度学习的目的。最终得到一个正确的预测模型。
计算梯度就是反向计算,也就是求导。
线性回归
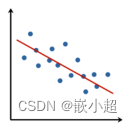
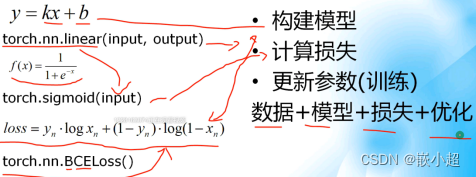
什么是线性回归?线性规划根据输入的数据拟合曲线。通过一堆点生成一条直线,这条直线符合y=kx+b这样的一元一次函数。采用的方法(拟合方式)是最小二乘法,也就是每个点的纵坐标(真实值)与线上的预测值之间的误差和最小。
Pytorch中如何求线性回归?使用函数:torch.nn.liner(input,output)
其中的输入是x,输出是y。
如何计算真实值与预测值之间的误差?
公式:
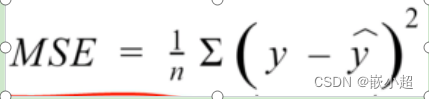
使用的函数:torch.nn.MSELoss
更新参数(k和d)的方法:参数=参数-学习率*参数梯度
计算损失值不断循环往复,直到这个损失值到最小值才停止更新。
上述不断更新参数的过程在Pytorch中如何实现?
使用下面的函数即可。使用SGD优化器不断拟合参数

如何构建正确的线性回归模型?
1.构建初始模型
2.计算损失
3.更新参数(模型训练)
数据+模型+损失+优化
通过一堆点生成一条直线,这个过程叫做拟合。
线性回归的过程就是找到合适的k和b,使得真实值与预测值的差值(损失值)最小。
逻辑回归
什么是逻辑回归?在线性组合的基础上加上非线性变换。
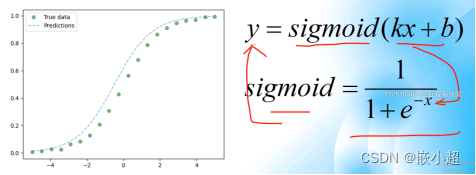
逻辑回归在理解了线性回归的基础上,理解起来比较简单,其实是对线性的情况进行复杂化,因为实际情况中的很多关系不是线性的。
人工神经网络
人工神经网络的出现:线性回归是预先知道y-x之间的关系的,而实际上很多时候是不知道两者之间的关系,就是说y-x很可能不是线性的,甚至数据量是否庞大,这个时候人工神经网络出现了,可以帮助构建y-x之间的模型关系。人工神经网络本意是为了模仿人的大脑神经网络,希望做到像人脑一样思考,因此提出了人工神经网络这个概念。
人工神经网络发展历史

感知机
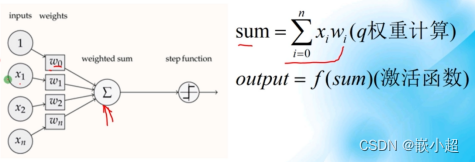
感知机的出现:线性回归都是单个变量之间的关系,为应对更为复杂的实际问题,出现了感知机这一概念,感知机的输入有多个x,输出y由多个线性回归组合而成,是一个多元一次函数。所求出的y为和,通过激活函数的操作,判断是否将其激活。这个就是比逻辑回归更加复杂点,多增加了输入量。
感知机也是在模仿神经网络,其中的结点就是神经元。
反向传播
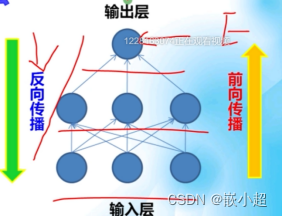
反向传播算法的两个阶段:前向传播阶段和反向传播阶段。
前向传播的作用:从输入层到隐藏层到输出层这一个过程,输出预测值,计算预测值跟标签值之间的差值。
反向传播的作用:差值从输出层反向传播给输入层,若差值过大就会重新计算参数,进行优化。优化后的参数再一次进行前向传播,如此往复循环,最终输出最小差值,停止参数更新。也说明预测值越来越接近真实值。
反向传播算法的分类:静态反向传播;循环反向传播。
反向传播的数学原理:自动梯度求导(遵循链式求导法则)
E是损失误差,net是输入值,o是输入值经过激活函数后的输出值。
E对wi求出的导数越大说明对E的贡献越大,可以通过减小w值来实现E的缩小,得到新的wi值,新的值重新进行训练,得到新的E值,通过判断E的大小考虑是否再进行上述的轮回,直至最小(也就是训练结束)。
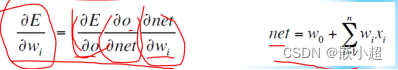
反向传播举例:

反向传播的训练方法
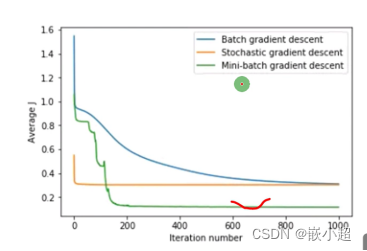
1.随机/世故梯度下降:计算梯度基于单个样本,计算速度快,很容易收敛。 每个样本都要下降一次。
2.标准/批量梯度下降:计算基于整个数据集,计算速度慢,不容易收敛。 整个样本全部计算完后下降一次。
3.mini_batch梯度下降:而实际训练中都不采用上述两种方法,而采用小批量梯度下降,也就是batch_size的值,这个值要根据显卡的内存去设置。 优点是:收敛速度快,算法精度高。
线性组合加上非线性变换就是感知机。
总结:前向传播用于产生错误;反向传播用于更新参数
Pytorch中的基础数据集
Pytoch内置数据集:Pytorch内置需要经典的数据集,可以直接拿来使用。
数据集的读取和加载:dataset用于读取数据集;dataloader用于加载数据集。
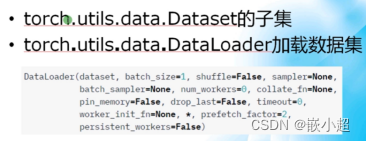
dataset也就是封装好了许多经典的数据集,我们没必要去网上下载了,存储在torchvision这个模块里面。在Pytorch里直接使用dataloader就可以下载了。
这篇关于【深度学习基础】Pytorch框架CV开发(1)基础铺垫的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






