本文主要是介绍阿里云 DataWorks v2.0 常见问题与难点解析整理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、依赖关系配置
- 依赖关系原理概述
- 三种依赖配置方式
- “自动解析”配置依赖关系:推荐使用
- 手动配置依赖关系
- “自动推荐”配置依赖关系
1.1 依赖关系原理概述
- 可扩展性差,缺乏解耦
- 重跑任务的成本太高
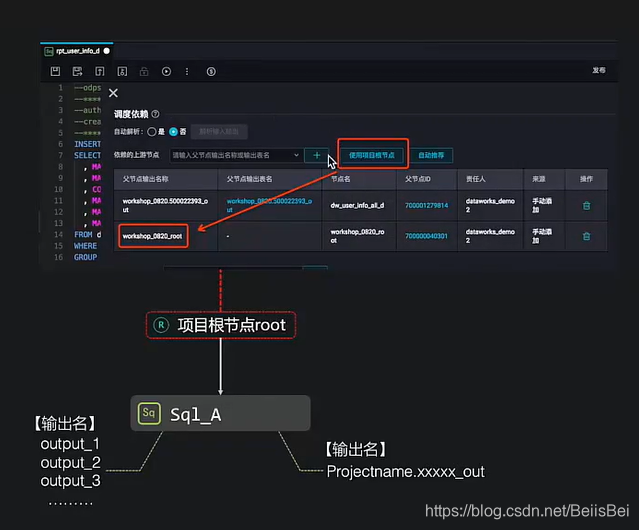
输出名称
- 每个节点(Task)输出点的名称。用于在单个租户(阿里云账号)内设置依赖关系时,连接上下游两个节点(Task)的虚拟实体。
【原则】
- 每个节点必须配置至少一个本节点输出名称、一个父节点输出名称
- 每个输出点必须在同租户、同Region唯一

1.2 三种依赖配置方式
【依赖模式】
- 手动配置:手工搜索上游节点名称实现;
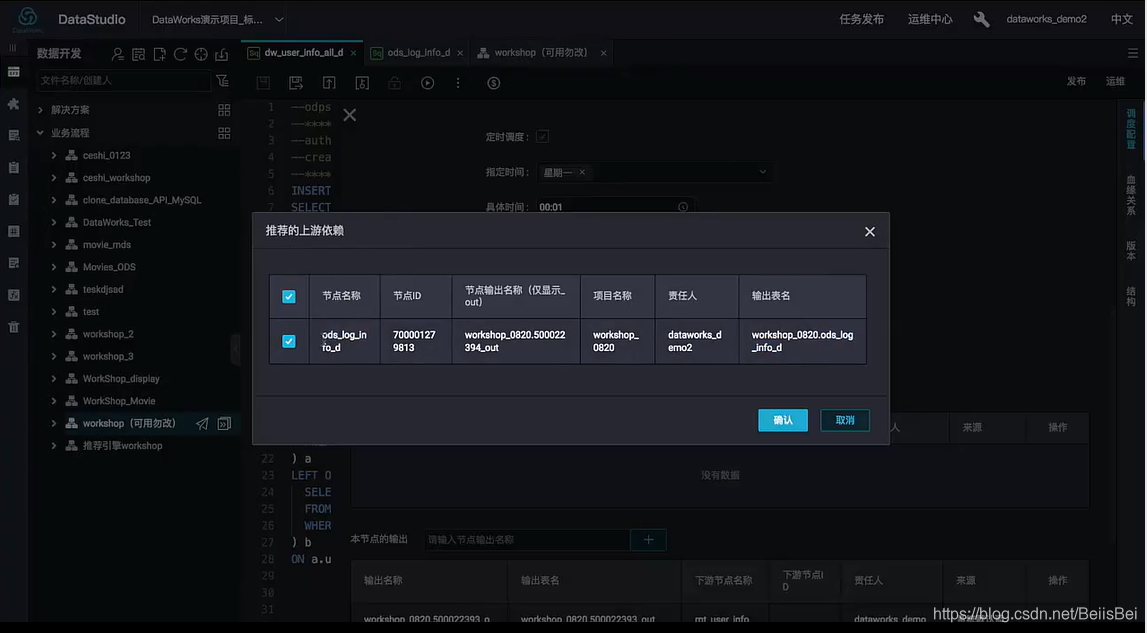
- 自动推荐:通过SQL血缘找到对应节点名
- 自动解析:通过SQL insert / create / from 解析输出名。
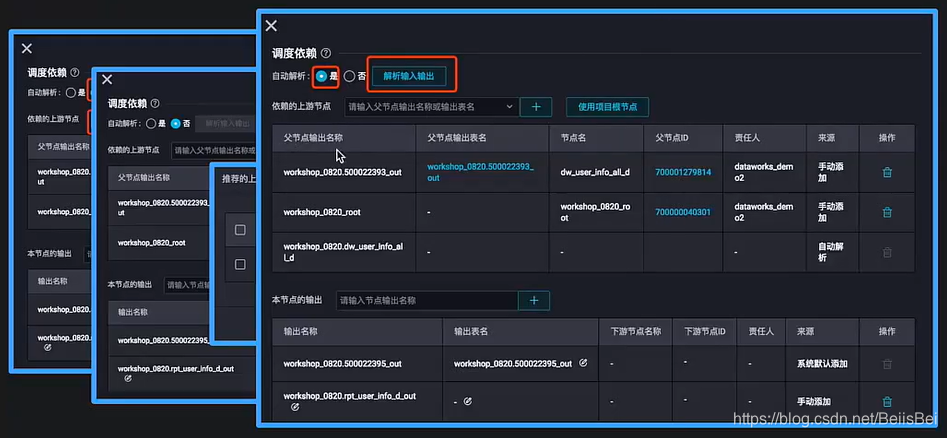
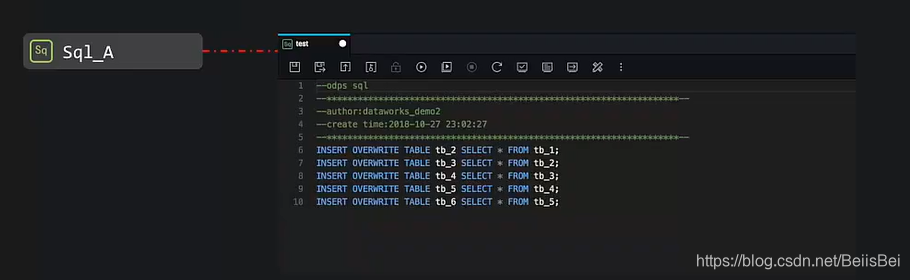
1.3 自动解析依赖关系
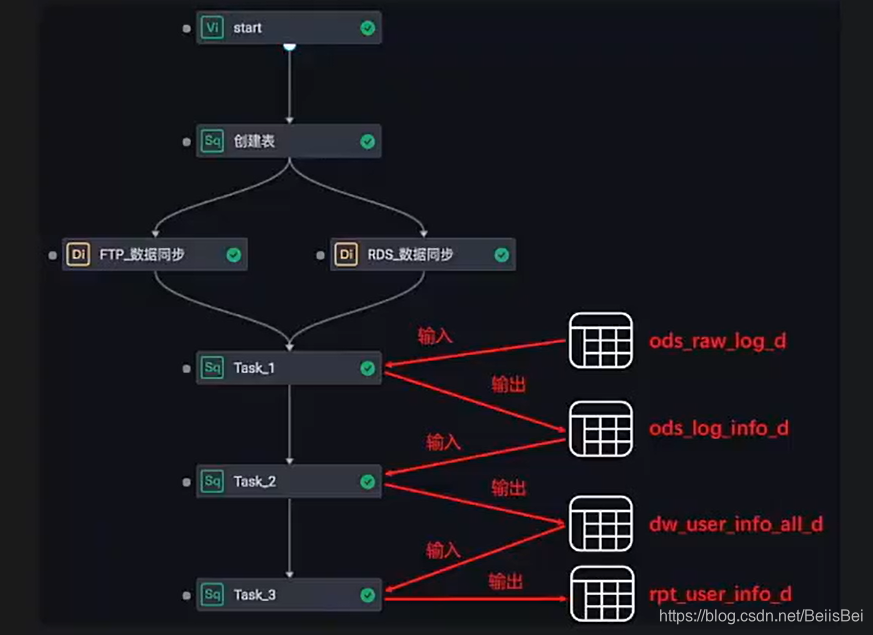
- 原理:根据 INSERT / CREATE / FROM 自动填写上游输出名与本节点输出名
- 前提:下游任务的输入表必须是上游任务的产出表
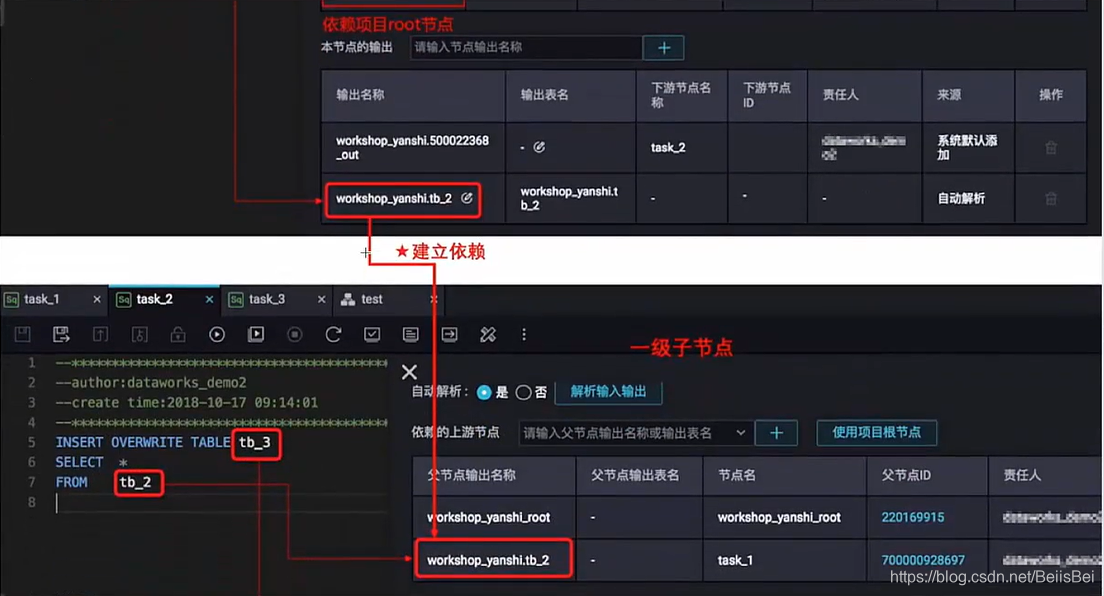
1.4 手动配置依赖关系
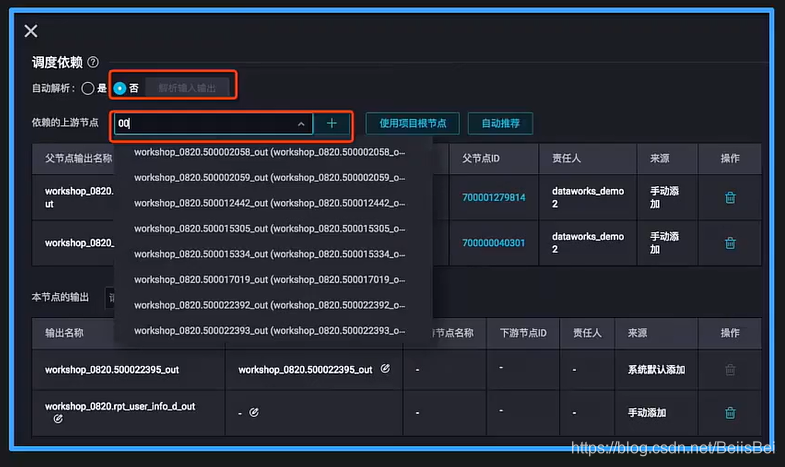
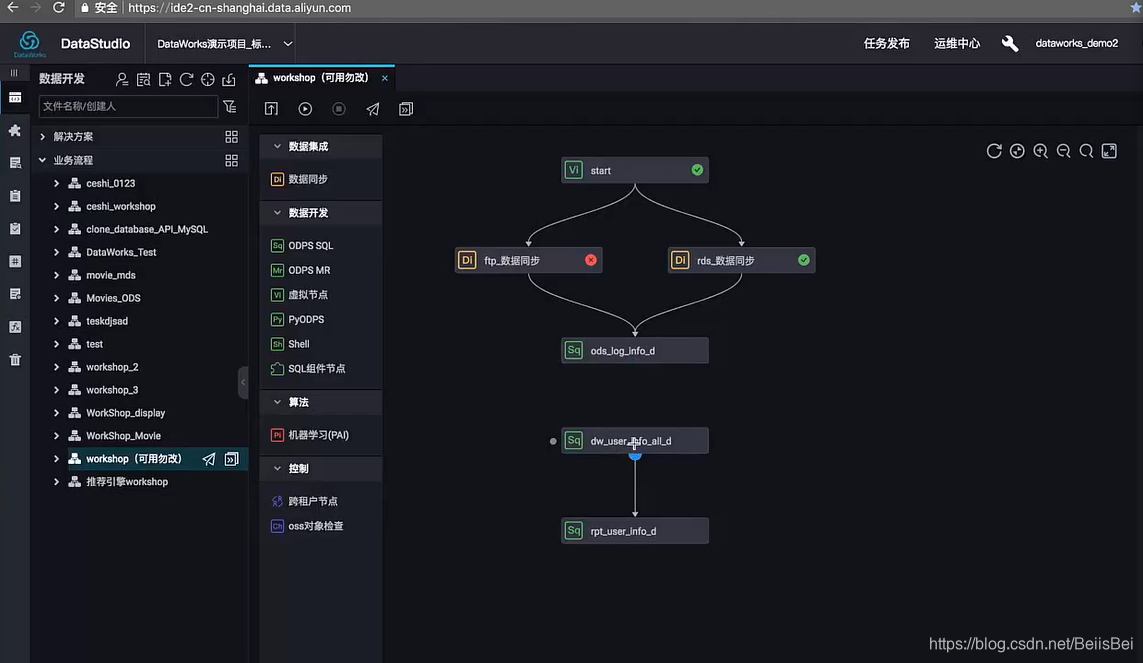
- 可以通过拉线的方式手动配置,这是最简单的方式
- 填写上游节点输出名进行手动配置
1.5 “自动推荐”配置依赖关系
二、常见问题解析
2.1 自动解析后提交失败
Q:自动解析后提交失败,报错:依赖的父节点输出projectname.table不存在,不能提交本节点,请先提交父节点。
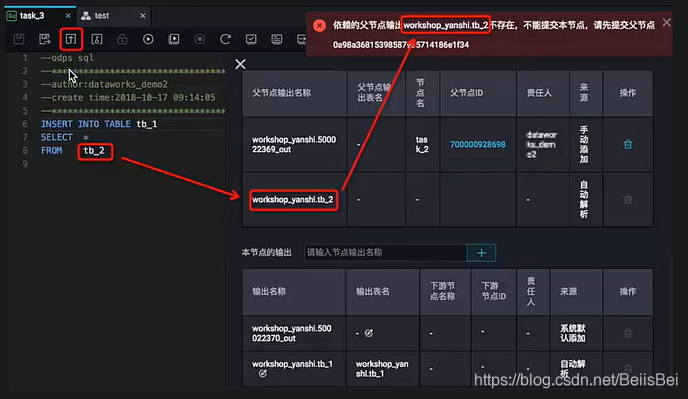
A:出现这种情况有以下两种原因:
- 上游节点未提交,提交后可以再次尝试。
- 上游节点已经提交,但上游节点的输出名不是 workshop_yanshi.tb_2 。
在当前的阿里云账号(同Region)下,必须存在一个拥有workshop_yanshi.tb_2输出名的节点已提交。
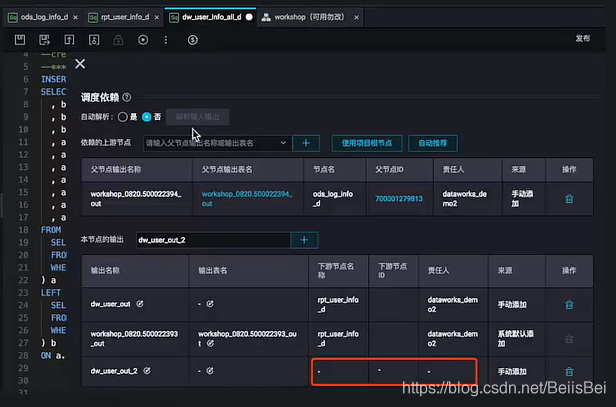
2.2 本节点输出中,下游节点名称等都是空且不能填写
Q:为什么本节点的输出中,下游节点名称、下游节点ID、责任人都是空且不能填写内容?
A:因为没有其他任意一个节点依赖于该输出名。
只有该输出名被依赖,且依赖它的节点被提交,此处才会自动解析出相关信息。
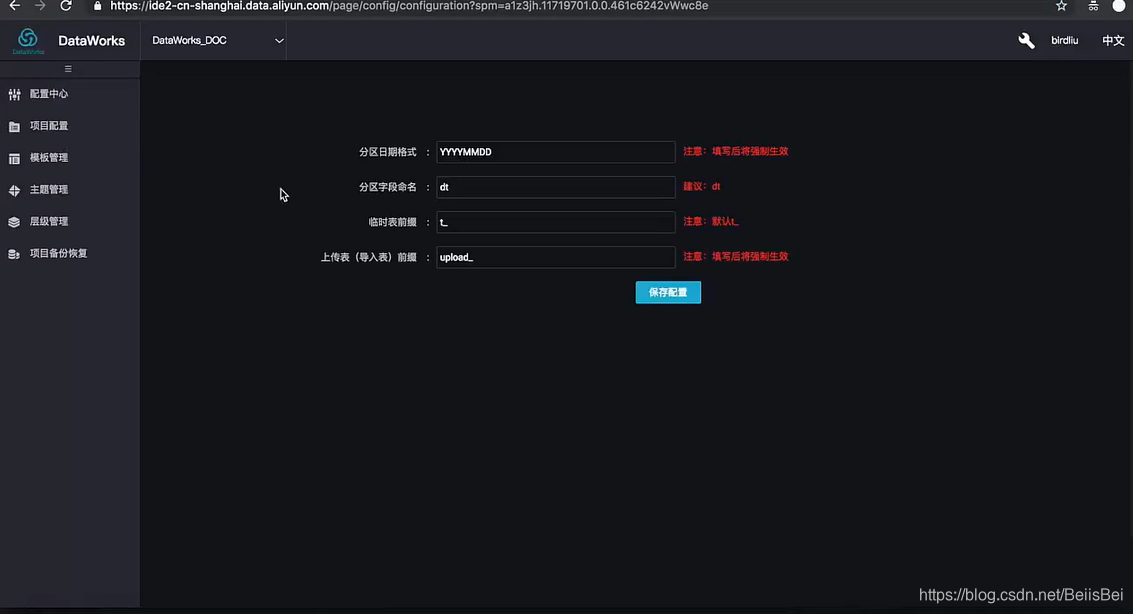
2.3 如何不自动解析中间表
Q:使用自动解析依赖关系时,如何不解析到中间表?
A:除了在SQL代码中对表名邮件“删除输出/删除输入”之外,还可以在“配置中心”中约点中间表前缀,符合规则的中间表讲不会被解析。

在左下角配置中心-项目配置中:
三、标准模式解析
- 标准模式介绍
- 标准模式与简单模式的区别、优势
- 注意事项
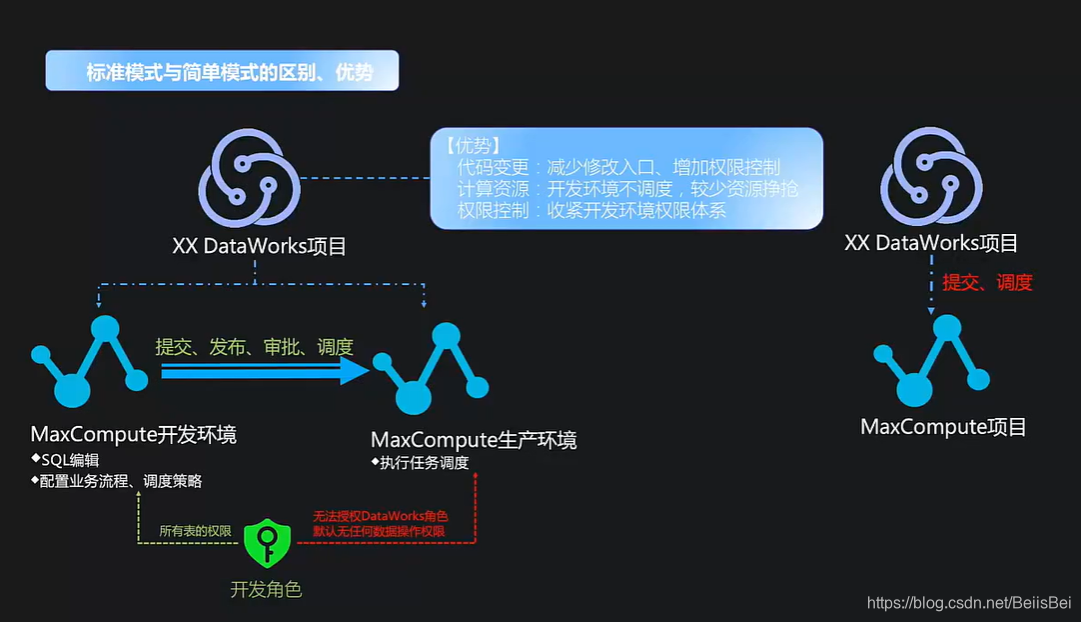
3.1 标准模式介绍

标准模式与简单模式的区别、优势

四、运维中心使用技巧
- 版面概述
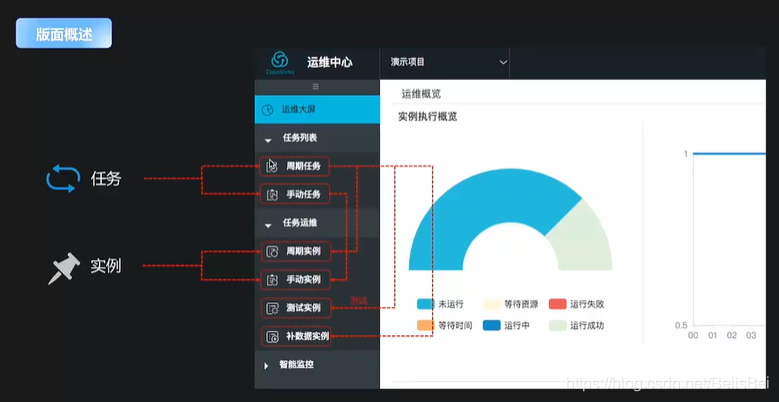
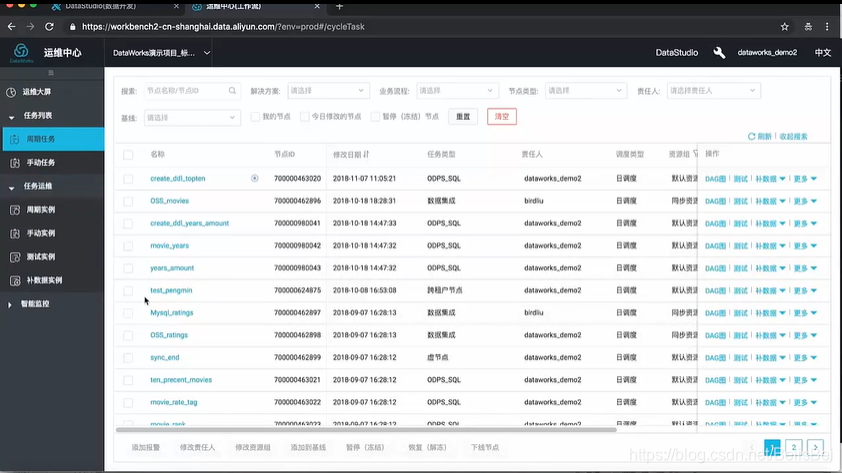
- 周期任务运维
- 手动期任务运维
- 组合节点
- 注意事项

这篇关于阿里云 DataWorks v2.0 常见问题与难点解析整理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





