本文主要是介绍Boltdb源码分析(二)----node结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文公众号文章链接:https://mp.weixin.qq.com/s/5_A_NqhOM--CILDdosKrSQ
本文csdn博客文章链接:https://blog.csdn.net/screscent/article/details/79852643
boltdb是一个纯粹的key Value数据库,其宗旨是提供一个简单,快速,可信的数据库。此数据库广泛应用于各大开源组件中。
上篇文章已经讲解了page结构 Boltdb源码分析(一)-------page结构
本文只分析其中的node结构。
github.com/boltdb/bolt/node.go
对应关系如下,node为内存中数据的存储模式,page是磁盘中存储格式。
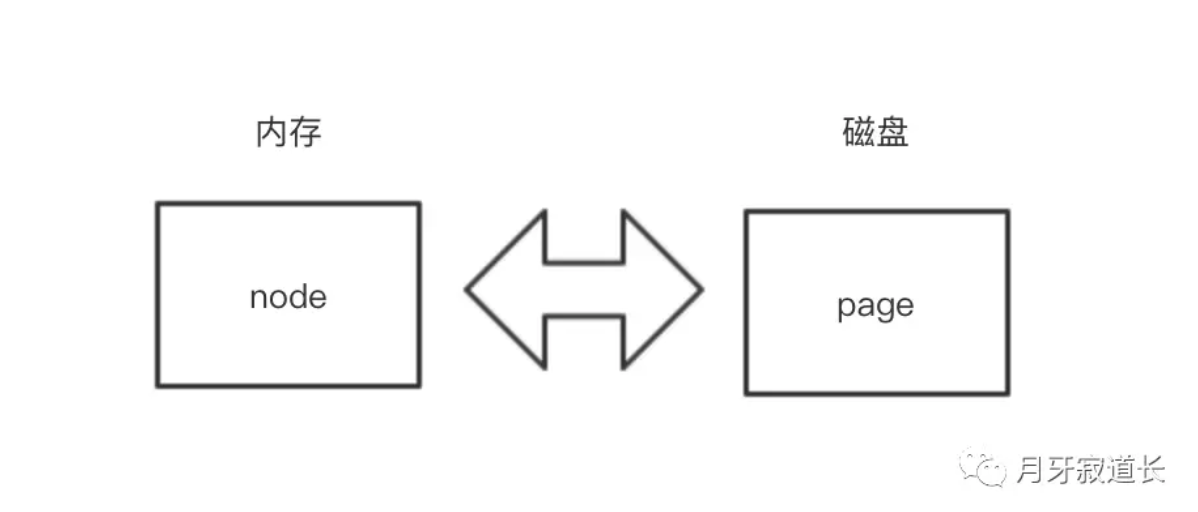
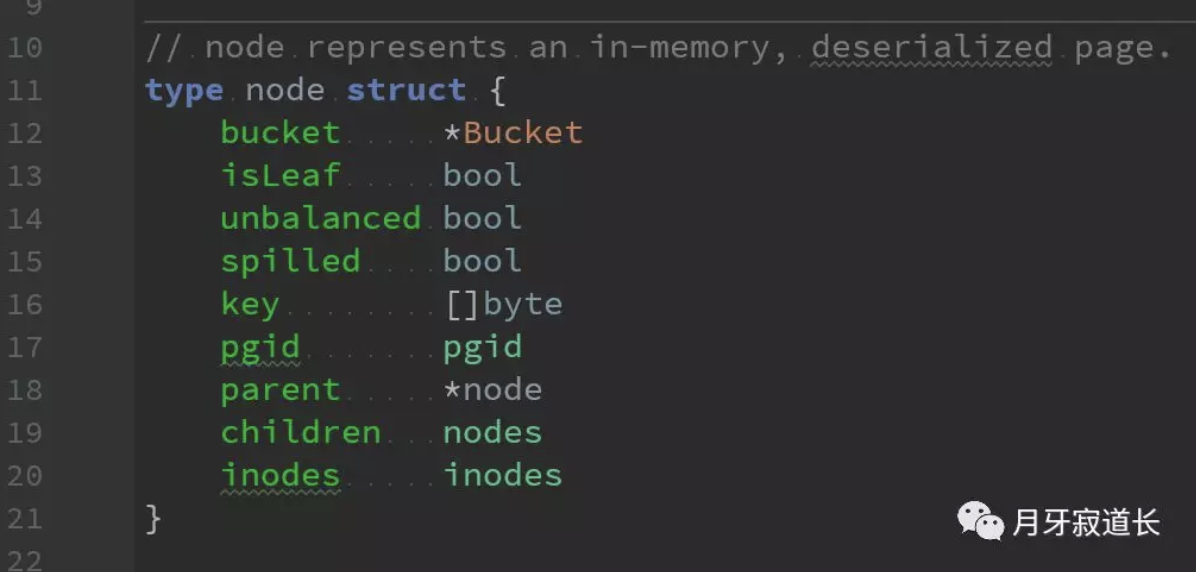
node结构体
bucket:是更上层的数据结构,类似于数据中的表的概念,一个bucket中包含了很多node
isLeaf:叶子节点flag。上篇page结构中,讲了两种数据结构branchPage,leafPage。
pgid:为page的id
parent:父节点
children:子节点
inodes:存储key value的结构
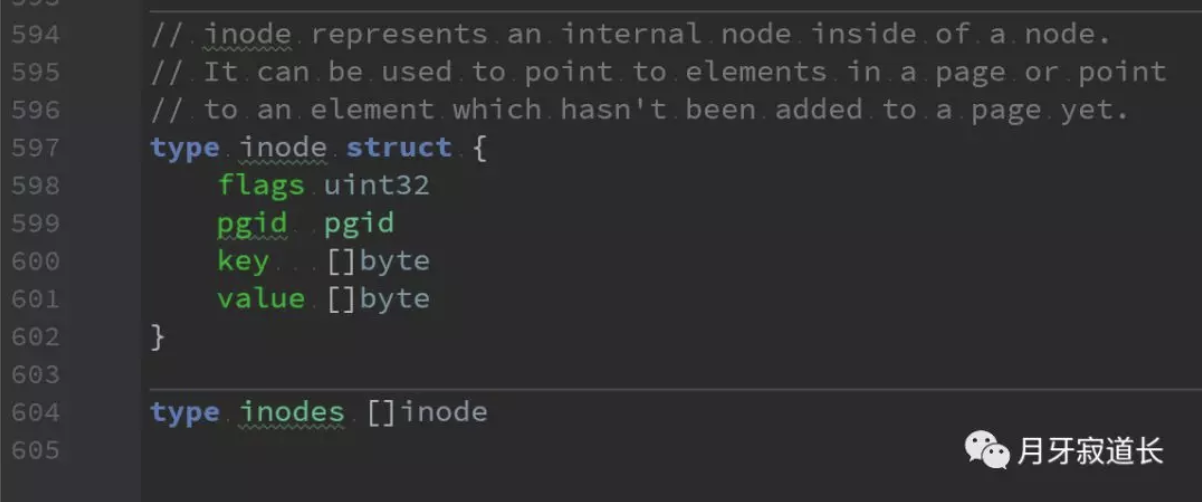
inodes结构
那么我们看看如何从磁盘中的page,加载到内存中的node?
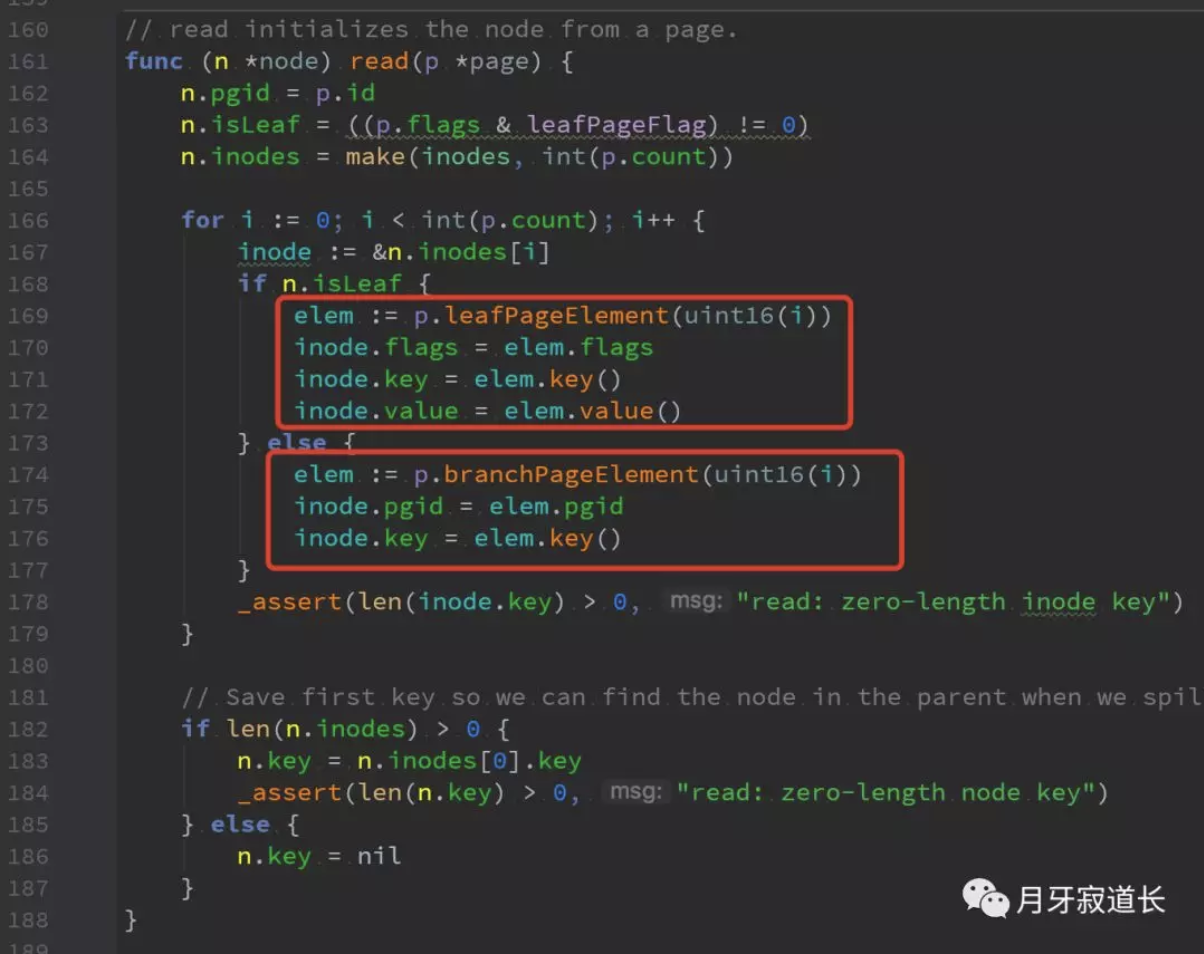
从page中读取内容,初始化到node。
n.pgid = p.id
n.isLeaf = ((p.flags & leafPageFlag) != 0)
n.inodes = make(inodes, int(p.count))解析id,isleadf,初始化inodes
然后在for循环中,根据page类型,进行初始化,对于page内容的读取,这个在page解析篇已经讲解过了。
那么将node从内存写入到磁盘中是如何的?
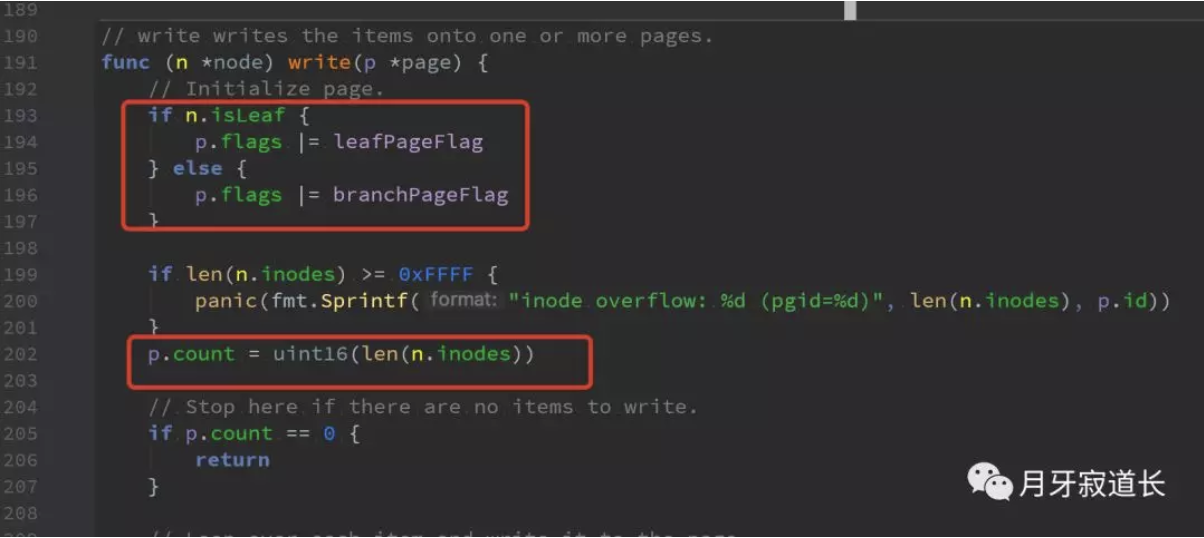
先是写入isleaf flag,再将inodes的大小写入到count中
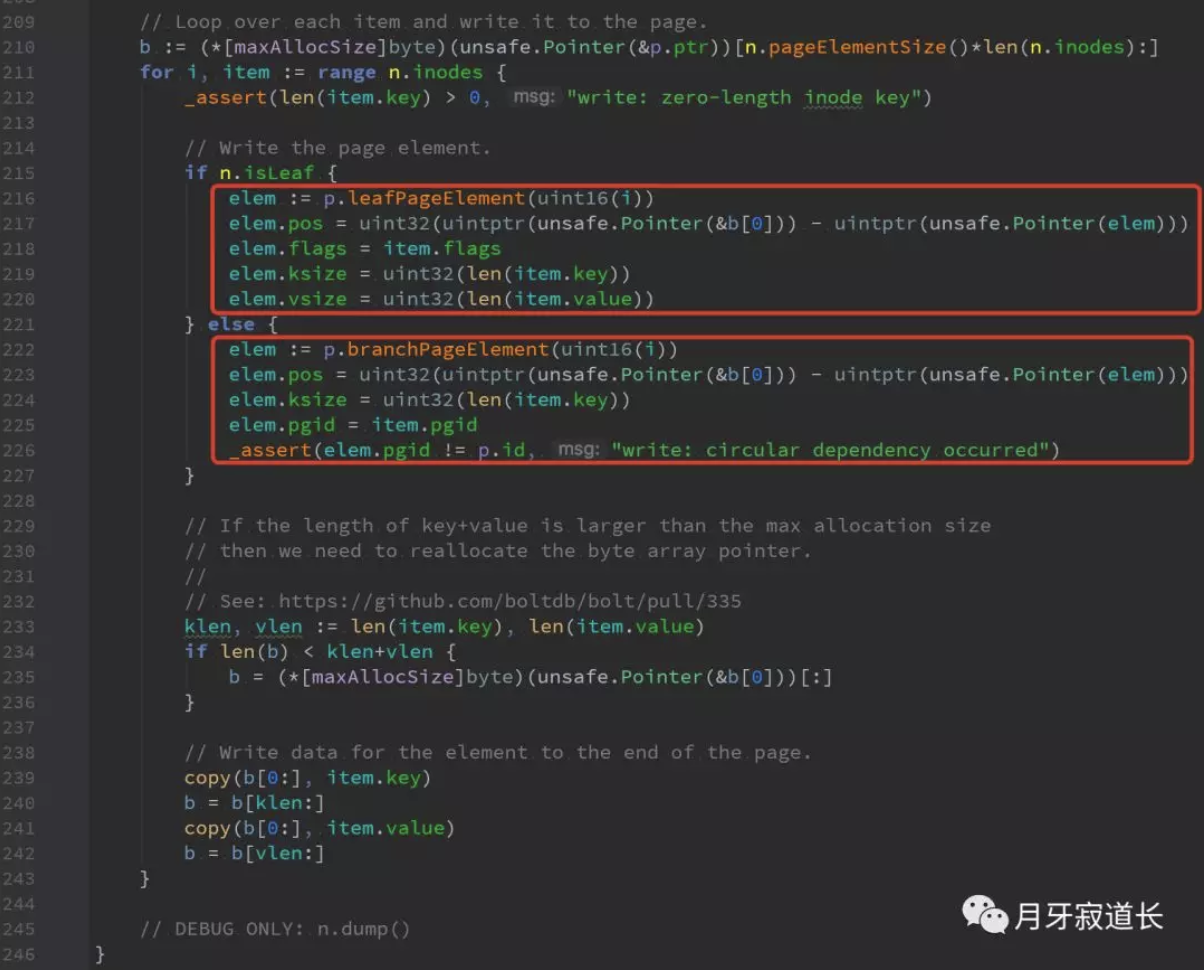
以上是根据page类型,将数据写入page中。
从磁盘到内存的加载,到从内存到磁盘的写入,都一一对应。
下面讲解下,node的其他几个操作
put
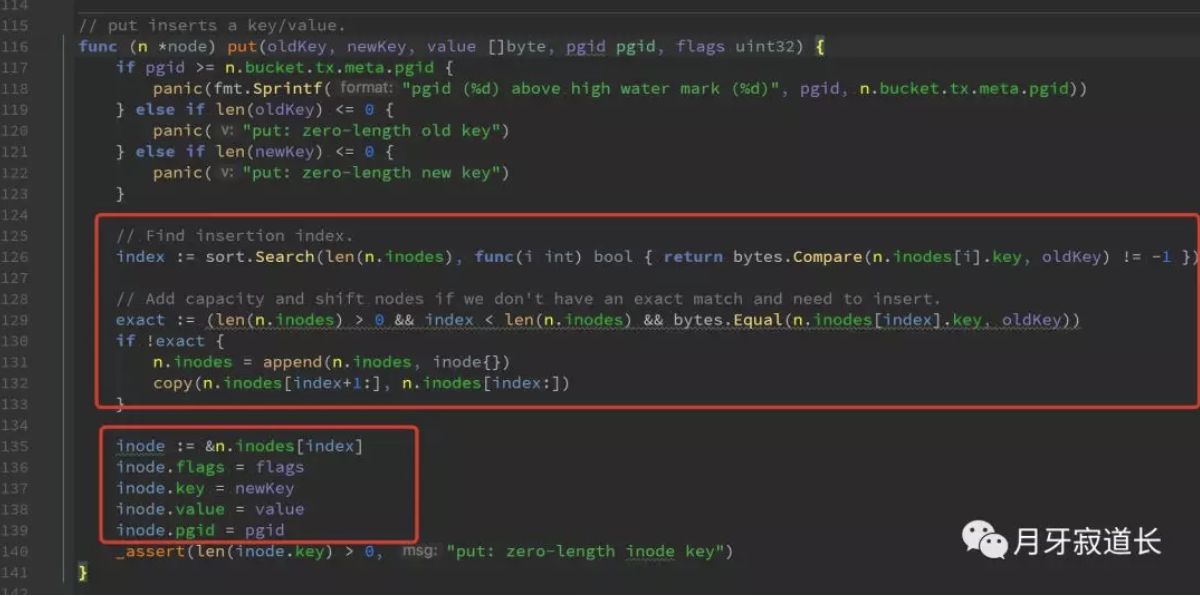
先查找到index,或者新生成一个index,然后将数据写入inode中
children的定位
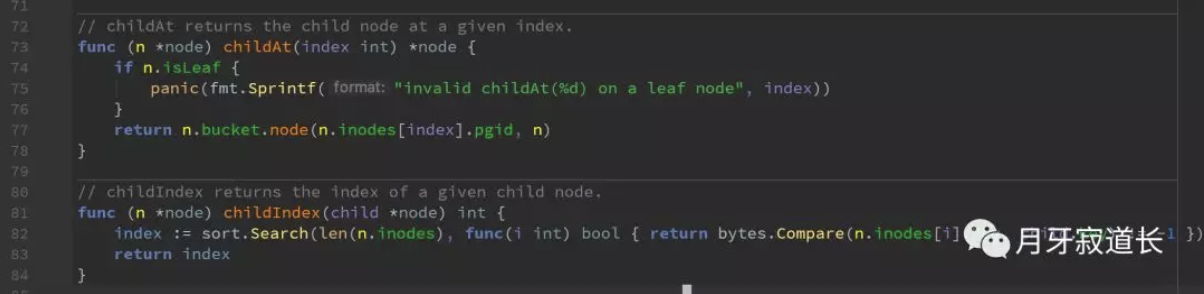
两个函数,一个是通过index查找child node,一个是通过node得到index
上面引出来了node到底是在上面地方初始化的
github.com/boltdb/bolt/bucket.go

bucket的结构体
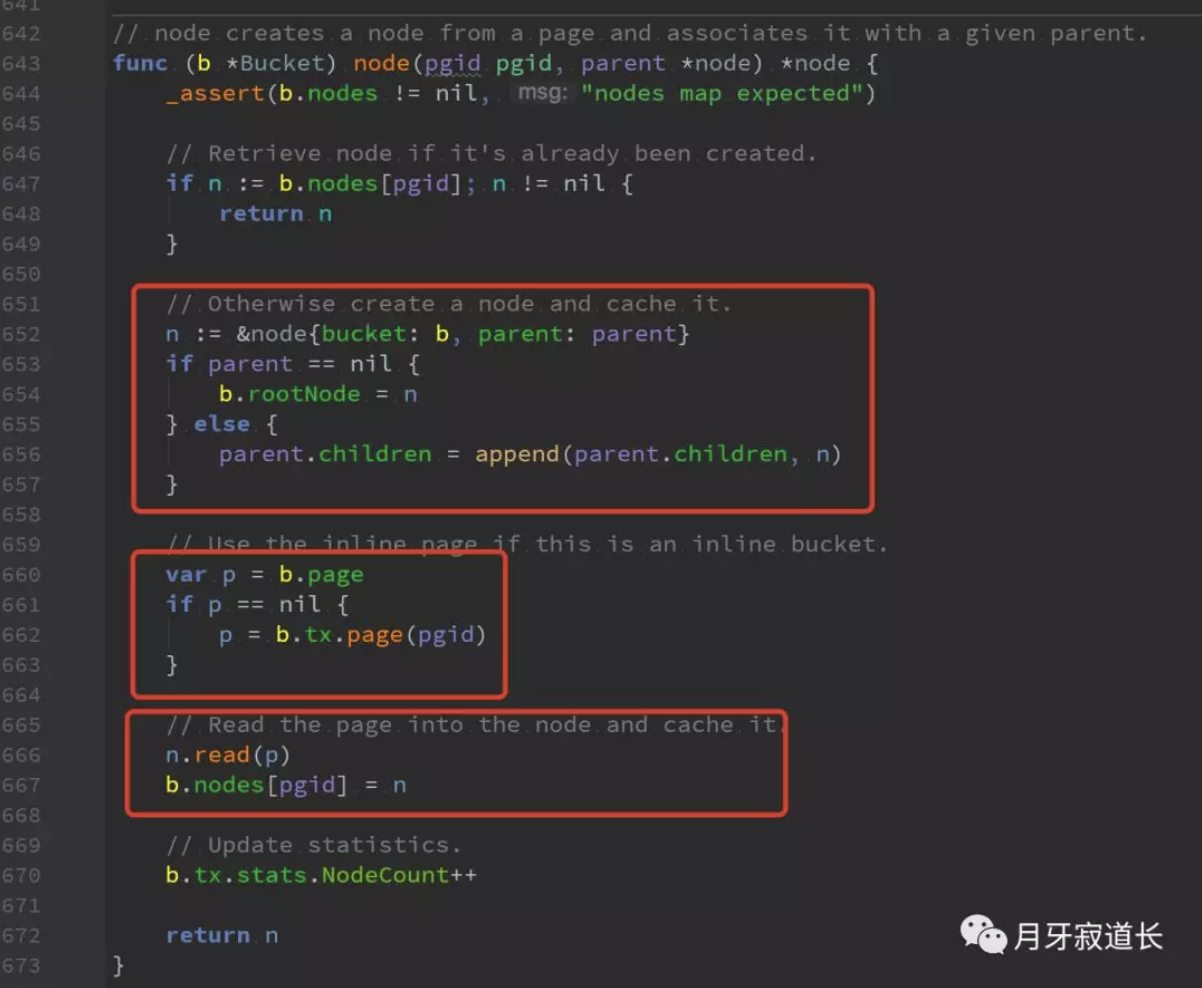
node的初始化步骤
先在bucket中查找,查找到了则直接返回pgid对应的node
没有查找到,则初始化
第一个红框中初始化bucket自己还有parent
第二个红框中定位对应的page
第三个红框则是讲page加载到内存中的node重,并将其记录在bucket中的node信息中。
龚浩华
月牙寂道长
QQ 29185807
2018年04月08日
如果你觉得本文对你有帮助,可以转到你的朋友圈,让更多人一起学习。
第一时间获取文章,可以关注本人公众号:月牙寂道长,也可以扫码关注

这篇关于Boltdb源码分析(二)----node结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






