本文主要是介绍TPAMI 2023 | Temporal Perceiver:通用时序边界检测方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文介绍一下今年我们组被T-PAMI 2023收录的时序边界检测工作 Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection。

论文名称: Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection 论文链接: Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection | IEEE Journals & Magazine | IEEE Xplore 代码地址:GitHub - MCG-NJU/TemporalPerceiver: [T-PAMI 2023] Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection
我们提出一种对视频中一类因为语义不连贯而自然产生的时序边界 (Generic Boundary) 的通用检测方法,基于Transformer Decoder建立了一个编码器-解码器结构。
在编码阶段,我们利用一组可学习的隐查询量 (Latent Queries) 来压缩冗余的输入时序特征为边界特征 (Boundary Queries) 和上下文特征 (Context Queries),在线性复杂度内有效完成特征压缩;在解码阶段,我们采用另一组可学习查询量 (Proposal Queries) 从压缩特征中解码时序边界的位置和置信度。
我们在镜头级别、事件级别和电影场景级别的自然时序边界数据集上进行测试,均取得了领先前沿的性能。为了进一步推进通用时序检测,我们联合不同语义粒度的时序边界数据集训练了语义层级无关的Temporal Perceiver模型,并取得了和单语义级别TP相比更强的泛化检测能力和接近的检测精度。
01. 任务背景
主流的视频理解任务,包括视频动作识别、动作检测、视频检测等等,通常关注对于较短视频的理解。长时视频,包括监控录像、电影、体育比赛录像等等,在其长达数小时的内容中包含着丰富的语义信息,具有很大的研究价值。然而,由于GPU内存的限制和有效的多层次语义分割方法的缺失,这些长时视频还未在过往视频理解工作中得到彻底的研究与挖掘。因此,我们希望能够提出一种将长视频分割为一系列更短的有意义的视频片段的方法,作为长视频理解的基础预处理模块。
我们着手研究对视频中不同层次的自然时序边界检测(Generic Boundary Detection, GBD),旨在定位长视频中自然产生的时序边界。该任务的核心概念是自然时序边界,该概念描述了一类因为视频语义不连贯而自然形成的时序边界。和过去研究较多的动作检测边界不同,自然时序边界没有任何预先定义的语义类别,可以不受语义/类别偏向影响的体现视频的时序结构。这个generic boundary的概念首先在Mike Shou老师组的GEBD工作[1]中被探索。我们将generic boundary的概念扩展到了多种不同的语义层次,如下图,包括足球比赛中的镜头切换边界和电影中的场景切换边界。对于这样语义层次差异较大的几种边界的检测,需要结合不同语义层次的信息来捕捉视频的时序结构和上下文。
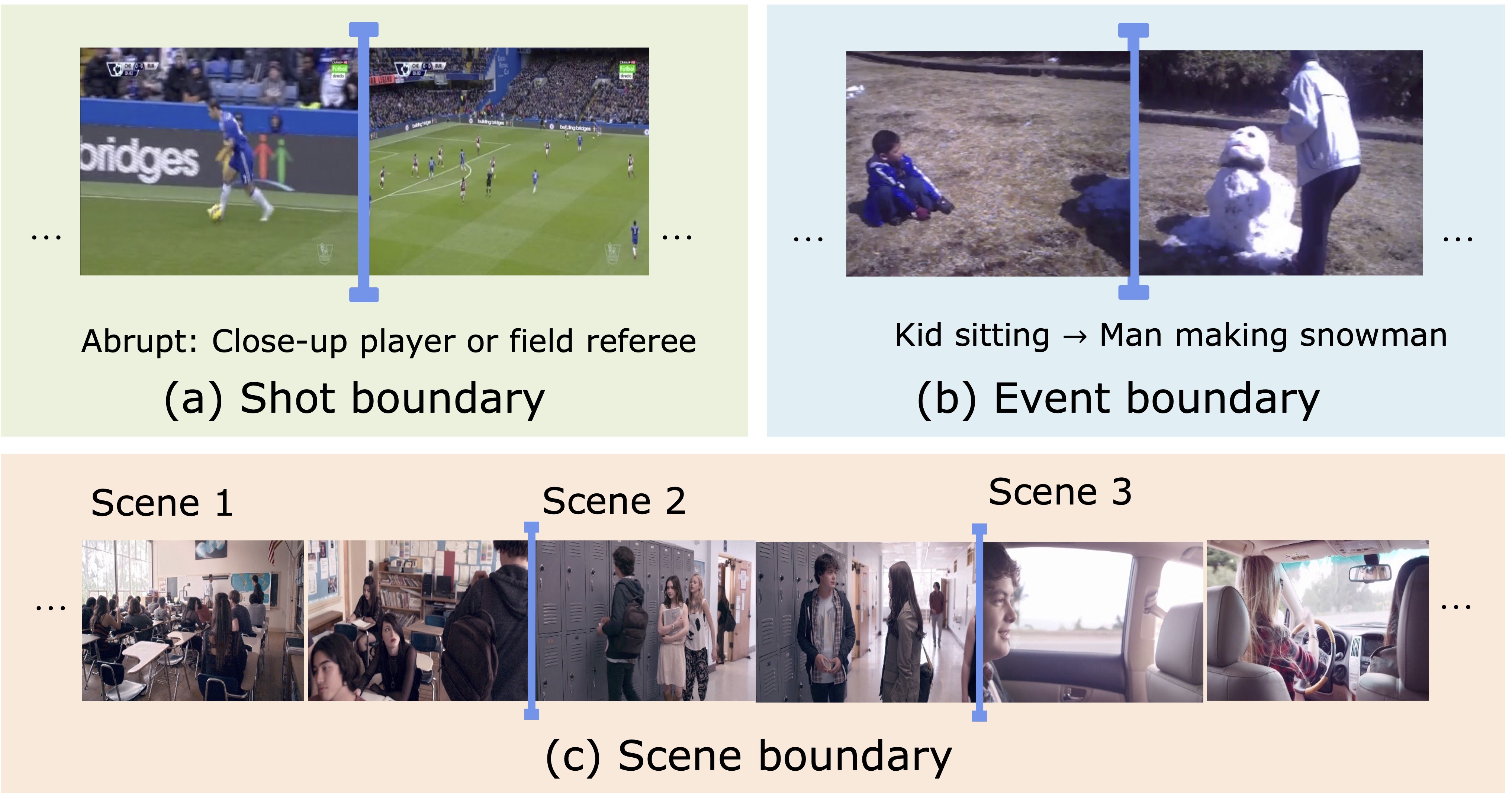
目前自然时序边界检测仍然是局限于在不同语义层次各自的任务中进行研究。镜头边界检测方法通过局部RGB变化来检测镜头边界;事件边界检测基于局部窗口的CNN捕捉动作语义进行看事件边界检测;场景边界检测利用LSTM建模长时序上下文,依赖于整体场景理解定位场景切换边界。此外,这些方法也常常采用复杂的后处理去重。这几种方法的模型设计和后处理方法和具体的边界类型紧密相关,难以在不同类型的自然时序边界检测中获得较好的泛化能力。
02. 研究动机
我们认为,不同语义层次的自然时序边界检测任务有着类似的视频语义结构和相似的需求。那么自然而然,我们会有这样的问题:我们能否在一个通用的检测框架中解决不同语义层次的自然时序边界检测?因此,我们提出Temporal Perceiver (TP),一个基于Transformer Decoder结构的通用模型,希望解决对任意自然时序边界的检测问题。自注意力模块是一种较为灵活的基础模块,但其复杂度是输入长度的平方。我们观察到输入视频存在时序冗余性,直接对输入视频特征做自注意力会带来很多不必要的计算,因此提出了在自注意力模块前压缩输入视频特征的编码器结构。我们的核心贡献在于提出了一组可学习的 latent queries 自适应地学习特征、压缩较长的视频到一个固定的时序长度,以降低复杂度到线性。
为了更好的利用视频语义结构的先验,我们进一步将latent queries分为两类:boundary queries 和 context queries。边界查询量的目标是在视频中提取边界及其邻域的特征,上下文查询量将视频中语义连续的片段聚合为一系列语义中心来抑制视频冗余。除此之外,我们还提出一个新的对齐损失函数在编码器交叉注意力图上,鼓励边界查询量一对一的学习边界特征,提高了模型的收敛速度和检测性能。我们的贡献如下:
1.我们提出Temporal Perceiver,一个通用的自然时序边界检测模型来解决长时视频中的自然时序边界检测问题,提供了一种基于Transformer的任意边界检测通用模型;
2.为解决长视频中的时序冗余问题、降低模型复杂度,我们提出latent query集合来通过交叉注意力模块进行特征压缩;为提高隐藏查询量的压缩效率,我们根据视频语义结构进行具体模型结构和训练策略设计,划分了边界-上下文查询量并提出基于编码交叉注意力的对齐损失函数;
3.实验展示了我们的方法只用RGB特征在镜头级别、事件级别和场景级别自然时序边界基准数据集上超越了过往前沿方法,并体现了模型在自然时序边界检测问题里对不同语义层次的边界检测的泛化性。
03. 方法

 3.1 特征编码与连贯性打分
3.1 特征编码与连贯性打分
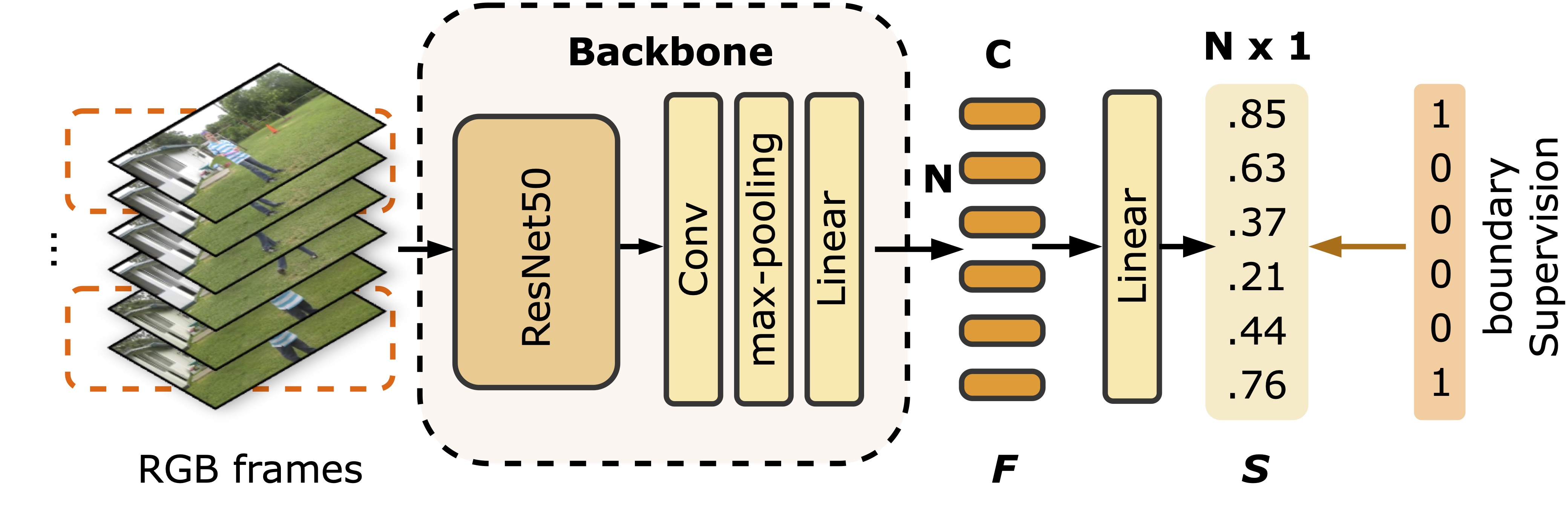

3.2 Temporal Perceiver
3.2.1 编码器:通过隐藏单元进行时序压缩

 3.2.2 解码器:基于提案查询量的稀疏检测
3.2.2 解码器:基于提案查询量的稀疏检测
3.2.3 与Perceiver和Perceiver IO的比较
我们的TP在思想上和Perceiver[4]及Perceiver IO[5]类似,都采用了latent queries进行输入压缩,但我们的方法在以下几个方面区别于Perceiver的方法。
-
基本的处理策略和管线不同。Perceiver和Perceiver IO采用的都是“read-process-write”策略,解耦了压缩结构和处理结构,采用的是一个单独的交叉注意力模块做压缩、多个自注意力模块做特征处理的不对称结构。而我们的TP采用的是一个耦合渐进的“compress-process”策略进行编码,每个编码层都包括堆叠的自注意力模块和交叉注意力模块。TP目标在将原始的视频特征序列逐步渐进压缩到隐特征空间。因此,我们的自注意力和交叉注意力模块数量是相同的。我们认为这种耦合渐进的压缩-处理策略可以提高压缩效率,同时允许在更深网络层加入监督来引导压缩过程。
-
训练策略和损失函数不同。Perceiver与Perceiver IO均不能采用显式的损失函数直接引导 latent units 的训练,仅依赖于最终结果的分类/预测损失函数。这样的训练过程可能会导致对latent unit的利用不充分、得到较差的性能。相比之下,我们仔细考虑了视频数据的特殊性质,结合GBD任务的特点,提出了定制的latent queries(边界、上下文)来处理输入视频数据的时序冗余。同时,我们还提出了一个新的对齐损失函数,在交叉注意力权重图上约束boundary queries的训练,而Perceiver和Perceiver IO没有采用额外的监督。消融实验也表明该对齐损失函数可以加快模型收敛,同时提高模型性能。
-
目标问题和领域不同。Perceiver和Perceiver IO 解决的都是经典分类问题和空间上的密集预测。这些任务常常需要一个分类头结构来生成分类标签,或者利用一个密集预测头结构来生成像素级标签。与之不同,我们的TP解决的是视频中的时序检测问题。我们需要将TP和稀疏检测头结合来直接回归得到generic boundary的位置。总体来说,由于检测目标之间存在很大的差异性,因此相对来说检测任务要比分类和密集预测任务难一点。因此,直接将Perceiver结构运用在解决检测问题上是无法得到很好的效果的,而我们TP针对视频数据和模型结构的创新模型都能在GBD任务上提高模型性能。
04. 实验
我们分别在镜头级别 (shot-level)、事件级别 (event-level)和场景级别 (scene-level)的generic boundary benchmark上进行了测试,并与过往工作进行性能对比。
4.1 镜头级别
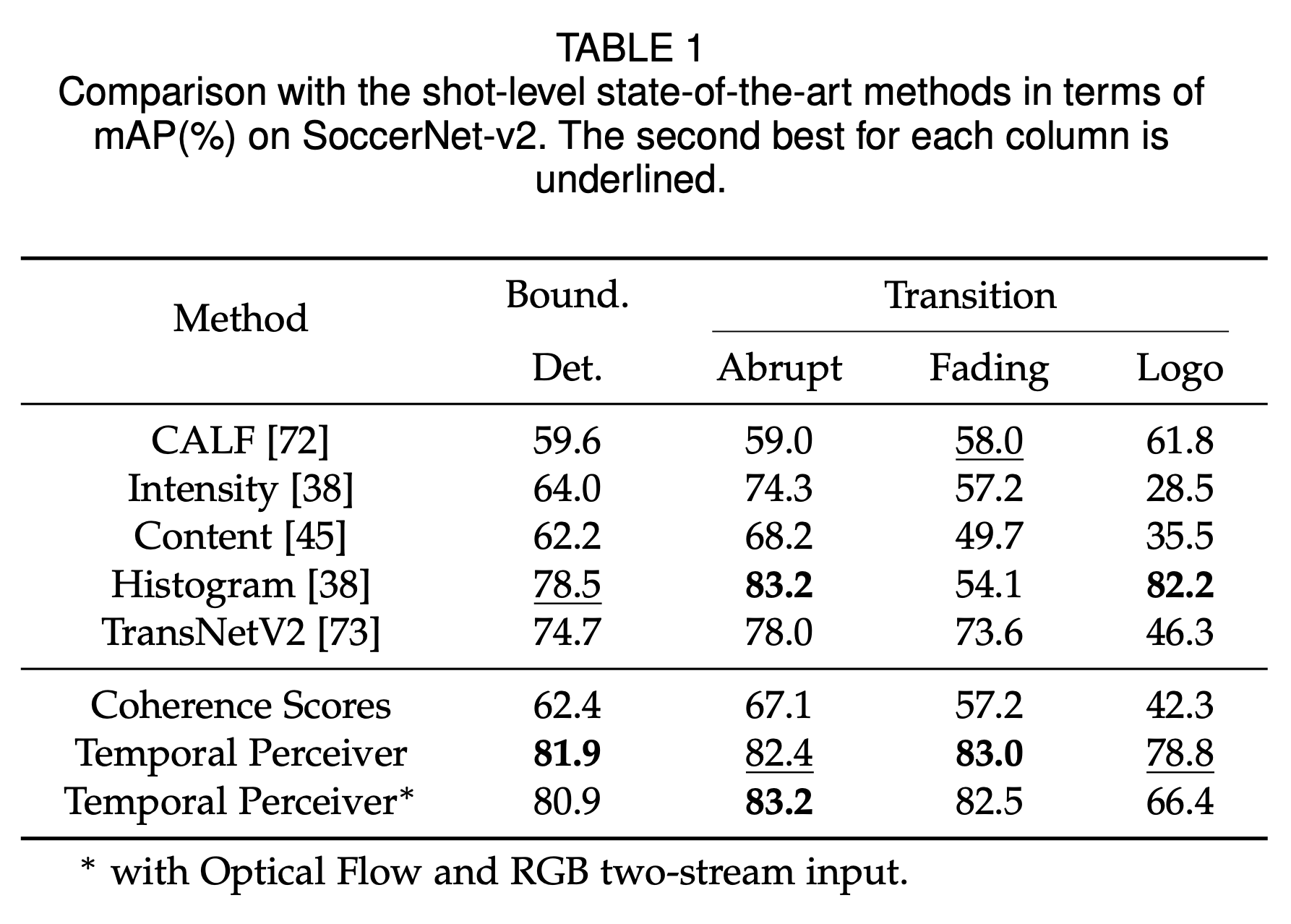
对于镜头切换检测,我们选择了基于足球赛事的 SoccerNet-v2[6]数据集上的 camera segmentation benchmark 进行测试。表1 展示了镜头级别比较结果,过往工作往往侧重于对某一类镜头转换的检测,可以看到TP在所有transition类别上综合性能优于过往工作。同时,我们也可以看到TP的性能并非依赖于coherence score的粗检测结果,相比coherence score检测结果有着很大的提高。实验结果也显示,光流信息(*)的引入并不能对性能有进一步的提升,这可能是因为RGB信息已经足以在当前任务获得很高的检测性能。
4.2 事件级别
对于事件转换检测,我们在基于日常行为视频的Kinetics-GEBD[1]数据集和基于奥林匹克体育赛事的TAPOS[7]数据集上进行测试。表2给出了我们方法在两个数据集上和过往工作的对比。
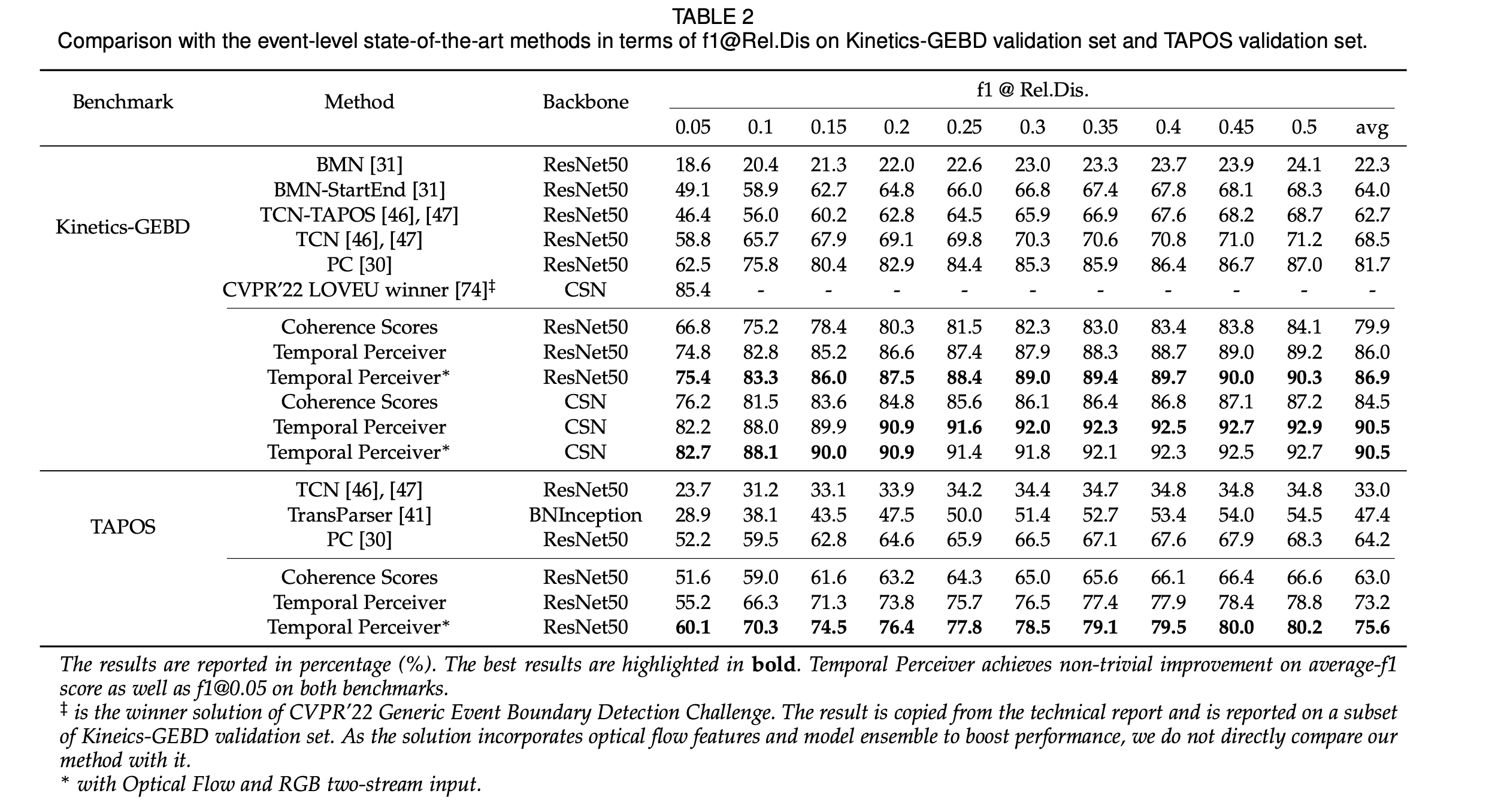
可以看出,TP在两个数据集上都能取得state-of-the-art的结果,尤其在rel.dis.较小的情况下我们的结果与之前工作的差距更大,体现出TP边界定位的准确性。除了ResNet50网络之外,我们也采用了IG-65M[8]预训练的CSN网络[9]作为backbone,其结果也接近 CVPR‘22 该任务的challenge winner结果。
4.3 场景级别
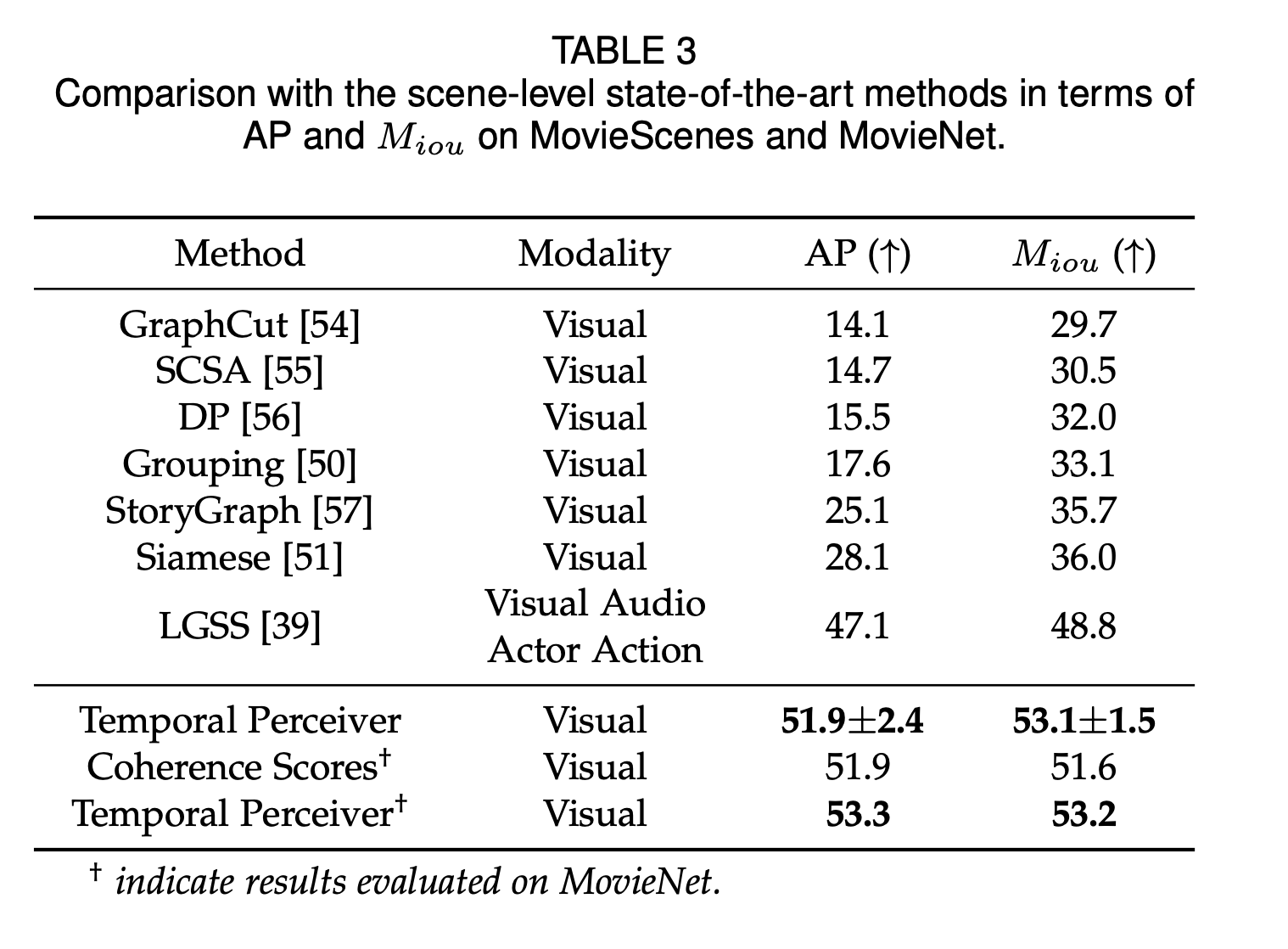
对于场景切换检测,我们选择了MovieNet[10]数据集的 scene boundary detection 任务进行测试,其指标为AP和Miou,其中Miou是边界预测划分的场景和场景真值的IoU加权和。表 3 展示了场景切换检测结果。可以看出,我们的方法在AP和Miou上都取得了超越过往有监督工作的性能,同时也展现出TP在不同语义粒度的自然边界检测问题上的泛化性。
4.4 类别无关Perceiver (Class-agnostic Perceiver)
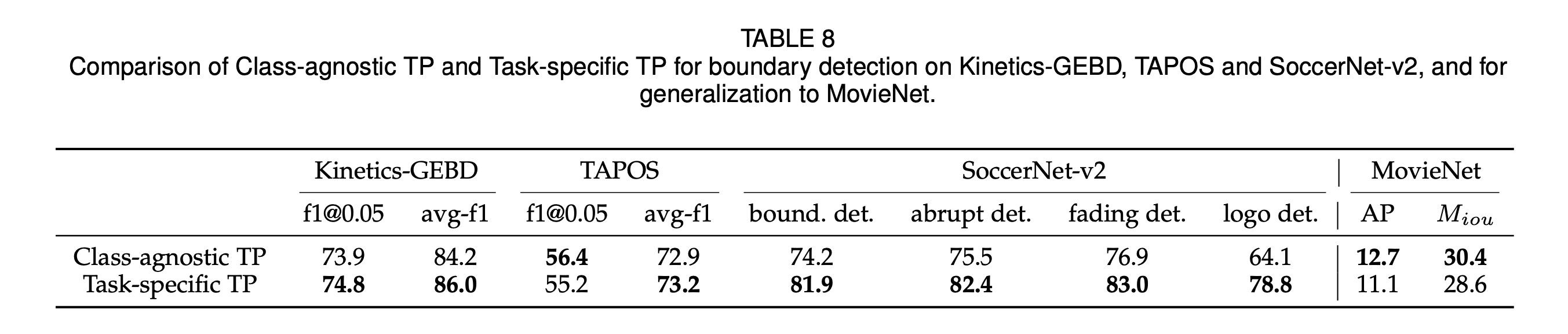
此外,我们联合多个时序边界数据集训练了一个语义层级无关的Temporal Perceiver模型,尝试进一步推进通用时序检测模型。我们对不同任务和数据集采用了同一个共享的模型:编码器和解码器均为任务共享;只有数据预处理步骤、编码器和解码器所使用的查询量(latent queries 和 proposal queries)因为不同数据集的数据分布、压缩度和解码先验不同而分别设计。我们没有在MovieNet上做泛化训练,是因为其视频帧并不连续(每个镜头只提供三帧关键帧图片),难以和其他时序连续的数据集一同训练,因此我们只在MovieNet上测试模型的unseen泛化性能。Unseen测试时,我们遵循locked tuning protocol[11],冻住编码器和解码器层,只finetune latent queries和feature queries来得到泛化性能。该实验的结果在表8中汇报,我们在所有的数据集上都取得了和单语义级别TP检测器相比更强的泛化检测能力和接近的检测精度。
由于篇幅限制,更多的消融实验、efficiency比较和结果可视化在此略过,欢迎查阅论文!
05. 总结
在这篇工作中,我们为不同语义粒度的自然边界检测提出了一个通用检测框架 Temporal Perceiver (TP)。TP 基于 Transformer Decoder 结构提出了一个有效的边界检测管线,为任意自然边界的检测提供了统一的网络结构。我们的核心贡献在于使用交叉注意力模块和一个 latent query 集合来将冗余的视频输入压缩到一个固定大小的隐空间里,以降低复杂度到线性。除此之外,我们还利用了视频的时序结构,将latent query分为 boundary query 和 context query 来分别压缩视频的边界特征和其余语义连贯的上下文特征。为了帮助收敛,我们在编码器交叉注意力层上提出了一个对齐约束,将边界特征和边界查询量对齐提取特征。得到压缩特征后,我们采用 Transformer Decoder 作为解码器完成对边界的稀疏检测。
实验表明,TP可以在不同语义层级的数据集上取得SOTA,体现了模型的检测性能和对不同粒度边界的泛化性能。我们在不同语义层次数据集的联合训练后也发现了对 unseen 粒度边界的更强泛化性能。如何进一步提高不同粒度边界的联合训练性能,以实现更强大的通用检测框架,也是我们未来探索的方向。
参考
[1] abShou, Mike Zheng, Stan Weixian Lei, Weiyao Wang, Deepti Ghadiyaram, and Matt Feiszli. "Generic event boundary detection: A benchmark for event segmentation." In ICCV, pp. 8075-8084. 2021.
[2] Carion, Nicolas, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. "End-to-end object detection with transformers." In ECCV, pp. 213-229. Cham: Springer International Publishing, 2020.
[3] Tan, Jing, Jiaqi Tang, Limin Wang, and Gangshan Wu. "Relaxed transformer decoders for direct action proposal generation." In ICCV, pp. 13526-13535. 2021.
[4] Jaegle, Andrew, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. "Perceiver: General perception with iterative attention." In ICML, pp. 4651-4664. PMLR, 2021.
[5] Jaegle, Andrew, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula et al. "Perceiver io: A general architecture for structured inputs & outputs." arXiv preprint arXiv:2107.14795 (2021).
[6] Deliege, Adrien, Anthony Cioppa, Silvio Giancola, Meisam J. Seikavandi, Jacob V. Dueholm, Kamal Nasrollahi, Bernard Ghanem, Thomas B. Moeslund, and Marc Van Droogenbroeck. "Soccernet-v2: A dataset and benchmarks for holistic understanding of broadcast soccer videos." In CVPR, pp. 4508-4519. 2021.
[7] Shao, Dian, Yue Zhao, Bo Dai, and Dahua Lin. "Intra-and inter-action understanding via temporal action parsing." In CVPR, pp. 730-739. 2020. [10] Huang, Qingqiu, Yu Xiong, Anyi Rao, Jiaze Wang, and Dahua Lin.
[8] Ghadiyaram, Deepti, Du Tran, and Dhruv Mahajan. "Large-scale weakly-supervised pre-training for video action recognition." In CVPR, pp. 12046-12055. 2019.
[9] Tran, Du, Heng Wang, Lorenzo Torresani, and Matt Feiszli. "Video classification with channel-separated convolutional networks." In ICCV, pp. 5552-5561. 2019.
[10] Huang, Qingqiu, Yu Xiong, Anyi Rao, Jiaze Wang, and Dahua Lin. "Movienet: A holistic dataset for movie understanding." In ECCV, pp. 709-727. 2020.
[11] Zhai, Xiaohua, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. "Lit: Zero-shot transfer with locked-image text tuning." In CVPR, pp. 18123-18133. 2022.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区
这篇关于TPAMI 2023 | Temporal Perceiver:通用时序边界检测方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




