本文主要是介绍Win7下面安装hadoop2.x插件及Win7/Linux运行MapReduce程序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、win7下
(一)、安装环境及安装包
win7 32 bit
jdk7
eclipse-java-juno-SR2-win32.zip
hadoop-2.2.0.tar.gz
hadoop-eclipse-plugin-2.2.0.jar
hadoop-common-2.2.0-bin.rar
(二)、安装
默认已经安装好了jdk、eclipse以及配置好了hadoop伪分布模式
1、拷贝hadoop-eclipse-plugin-2.2.0.jar插件到Eclipse安装目录的子目录plugins下,重启Eclipse。
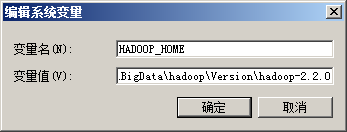
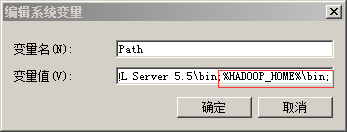
2、设置环境变量
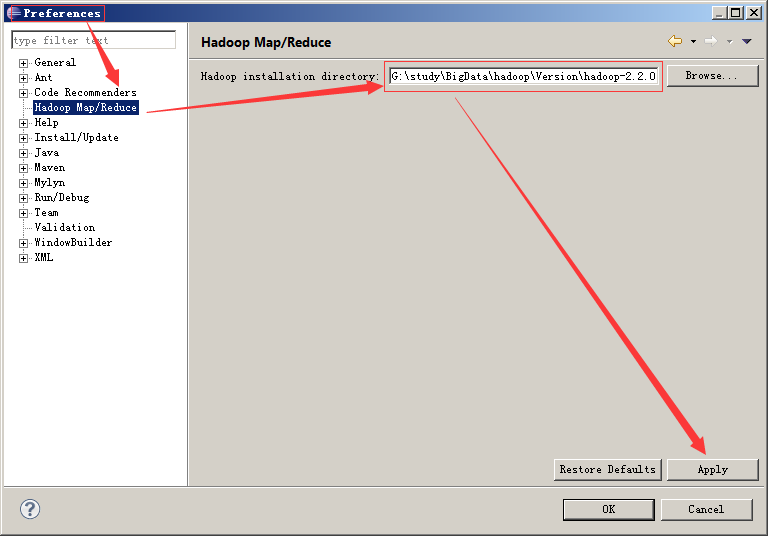
3、配置eclipse中hadoop的安装目录
解压hadoop-2.2.0.tar.gz
4、解压hadoop-common-2.2.0-bin.rar
复制里面的文件到hadoop安装目录的bin文件夹下

(三)、在win7下,MapReuce On Yarn执行
新建一个工程
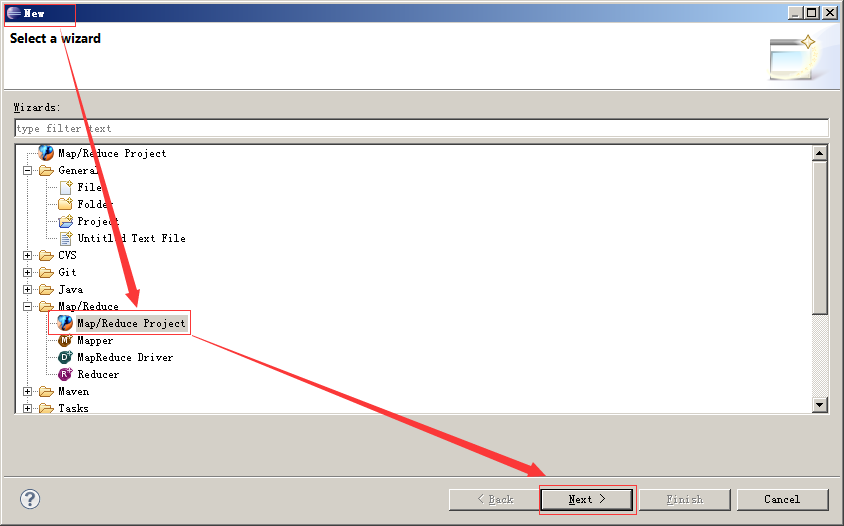
点击window–>show view–>Map/Reduce Locations
点击New Hadoop Location……

添加如下配置,点击完成。
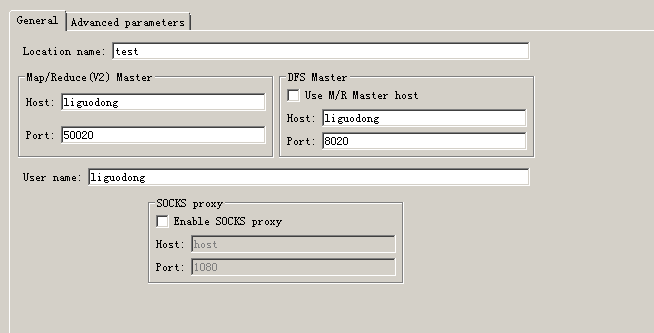
自此,你就可以查看HDFS中的相关内容了。
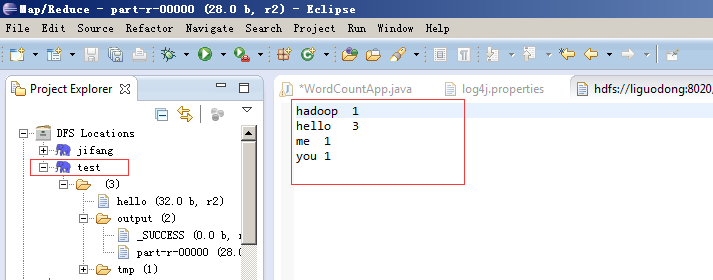
编写mapreduce程序
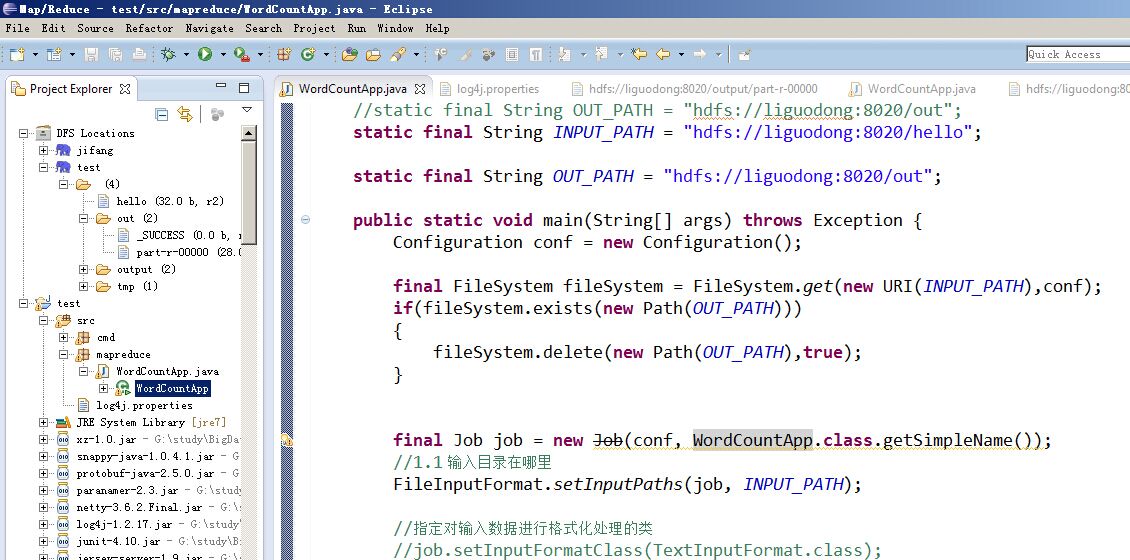
在src目录下添加文件log4j.properties,内容如下:
log4j.rootLogger=debug,appender1log4j.appender.appender1=org.apache.log4j.ConsoleAppenderlog4j.appender.appender1.layout=org.apache.log4j.TTCCLayout
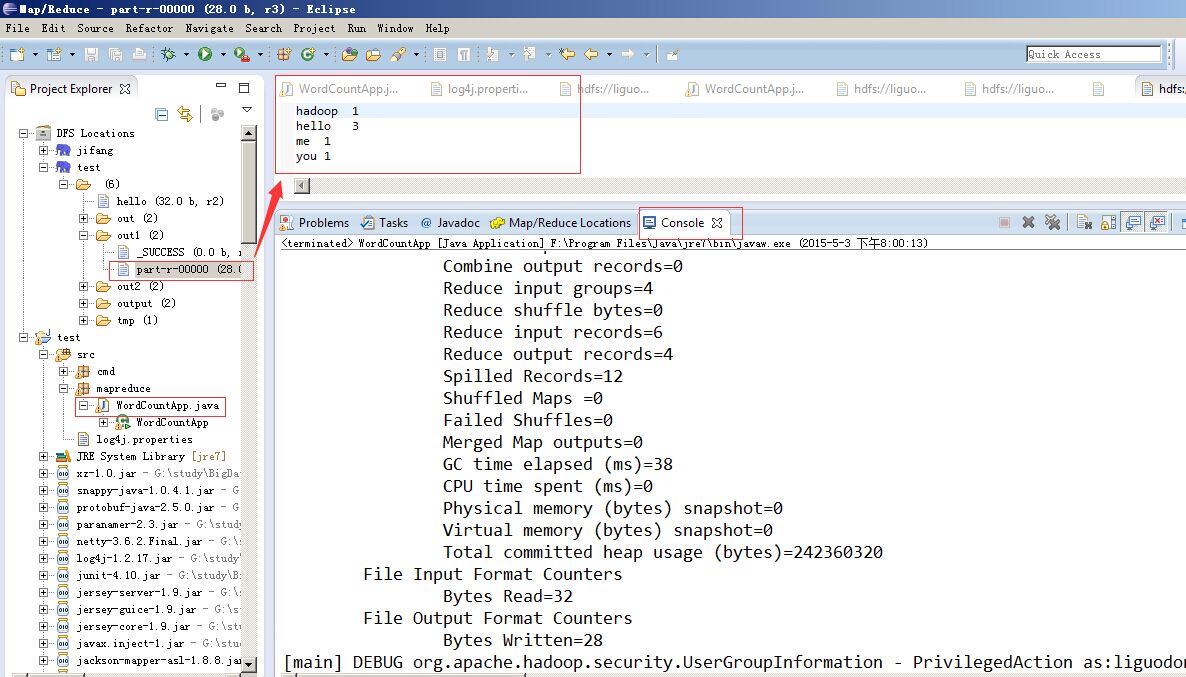
运行,结果如下:
二、在Linux下
(一)在Linux下,MapReuce On Yarn上
运行
[root@liguodong Documents]# yarn jar test.jar hdfs://liguodong:8020/hello hdfs://liguodong:8020/output
15/05/03 03:16:12 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
………………
15/05/03 03:16:13 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1430648117067_0001
15/05/03 03:16:13 INFO impl.YarnClientImpl: Submitted application application_1430648117067_0001 to ResourceManager at /0.0.0.0:8032
15/05/03 03:16:13 INFO mapreduce.Job: The url to track the job: http://liguodong:8088/proxy/application_1430648117067_0001/
15/05/03 03:16:13 INFO mapreduce.Job: Running job: job_1430648117067_0001
15/05/03 03:16:21 INFO mapreduce.Job: Job job_1430648117067_0001 running in uber mode : false
15/05/03 03:16:21 INFO mapreduce.Job: map 0% reduce 0%
15/05/03 03:16:40 INFO mapreduce.Job: map 100% reduce 0%
15/05/03 03:16:45 INFO mapreduce.Job: map 100% reduce 100%
15/05/03 03:16:45 INFO mapreduce.Job: Job job_1430648117067_0001 completed successfully
15/05/03 03:16:45 INFO mapreduce.Job: Counters: 43File System CountersFILE: Number of bytes read=98FILE: Number of bytes written=157289FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=124HDFS: Number of bytes written=28HDFS: Number of read operations=6HDFS: Number of large read operations=0HDFS: Number of write operations=2Job CountersLaunched map tasks=1Launched reduce tasks=1Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=16924Total time spent by all reduces in occupied slots (ms)=3683Map-Reduce FrameworkMap input records=3Map output records=6Map output bytes=80Map output materialized bytes=98Input split bytes=92Combine input records=0Combine output records=0Reduce input groups=4Reduce shuffle bytes=98Reduce input records=6Reduce output records=4Spilled Records=12Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=112CPU time spent (ms)=12010Physical memory (bytes) snapshot=211070976Virtual memory (bytes) snapshot=777789440Total committed heap usage (bytes)=130879488Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format CountersBytes Read=32File Output Format CountersBytes Written=28
查看结果
[root@liguodong Documents]# hdfs dfs -ls /
Found 3 items
-rw-r--r-- 2 root supergroup 32 2015-05-03 03:15 /hello
drwxr-xr-x - root supergroup 0 2015-05-03 03:16 /output
drwx------ - root supergroup 0 2015-05-03 03:16 /tmp
[root@liguodong Documents]# hdfs dfs -ls /output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2015-05-03 03:16 /output/_SUCCESS
-rw-r--r-- 2 root supergroup 28 2015-05-03 03:16 /output/part-r-00000
[root@liguodong Documents]# hdfs dfs -text /output/pa*
hadoop 1
hello 3
me 1
you 1
遇到的问题
File /output/……… could only be replicated to 0 nodes instead of minReplication (=1).
There are 1 datanode(s) running and no node(s) are excluded in this operation.在网上找了很多方法是试了没有解决,然后自己根据这句话的中文意思是只有被复制到0个副本,而不是最少的一个副本。
我将最先dfs.replication.min设置为0,但是很遗憾,后面运行之后发现必须大于0,我又改为了1。
然后再dfs.datanode.data.dir多设置了几个路径,就当是在一个系统中多次备份吧,后面发现成功了。
设置如下,在hdfs-site.xml中添加如下配置。
<property><name>dfs.datanode.data.dir</name> <value> file://${hadoop.tmp.dir}/dfs/dn,file://${hadoop.tmp.dir}/dfs/dn1,file://${hadoop.tmp.dir}/dfs/dn2 </value></property>
(二)在Linux下,MapReuce On Local上
在mapred-site.xml中,添加如下配置文件。
<configuration><property><name>mapreduce.framework.name</name><value>local</value></property>
</configuration>可以不用启动ResourceManager和NodeManager。
运行
[root@liguodong Documents]# hadoop jar test.jar hdfs://liguodong:8020/hello hdfs://liguodong:8020/output三、MapReduce运行模式有多种
mapred-site.xml中
1)本地运行模式(默认)
<configuration><property><name>mapreduce.framework.name</name><value>local</value></property>
</configuration>2)运行在YARN上
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>四、Uber Mode
Uber Mode是针对于在Hadoop2.x中,对于MapReuduce Job小作业来说的一种优化方式(重用JVM的方式)。
小作业指的是MapReduce Job 运行处理的数据量,当数据量(大小)小于 HDFS 存储数据时block的大小(128M)。
默认是没有启动的。
mapred-site.xml中
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>这篇关于Win7下面安装hadoop2.x插件及Win7/Linux运行MapReduce程序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







