本文主要是介绍Java 的高性能缓存库-caffeine!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在项目中用到的除了分布式缓存,还有本地缓存,例如:Guava、Encache,使用本地缓存能够很大程度上提升程序性能,本地缓存是直接从本地内存中读取,没有网络开销。
今天给大家介绍一个高性能的 Java 缓存库 – Caffeine 。
简介
Caffeine是基于Java8 的高性能缓存库,借鉴了 Guava 和 ConcurrentLinkedHashMap 的设计经验,拥有更高的缓存命中率和更快的读写速度。
性能比Guava更强

数据结构
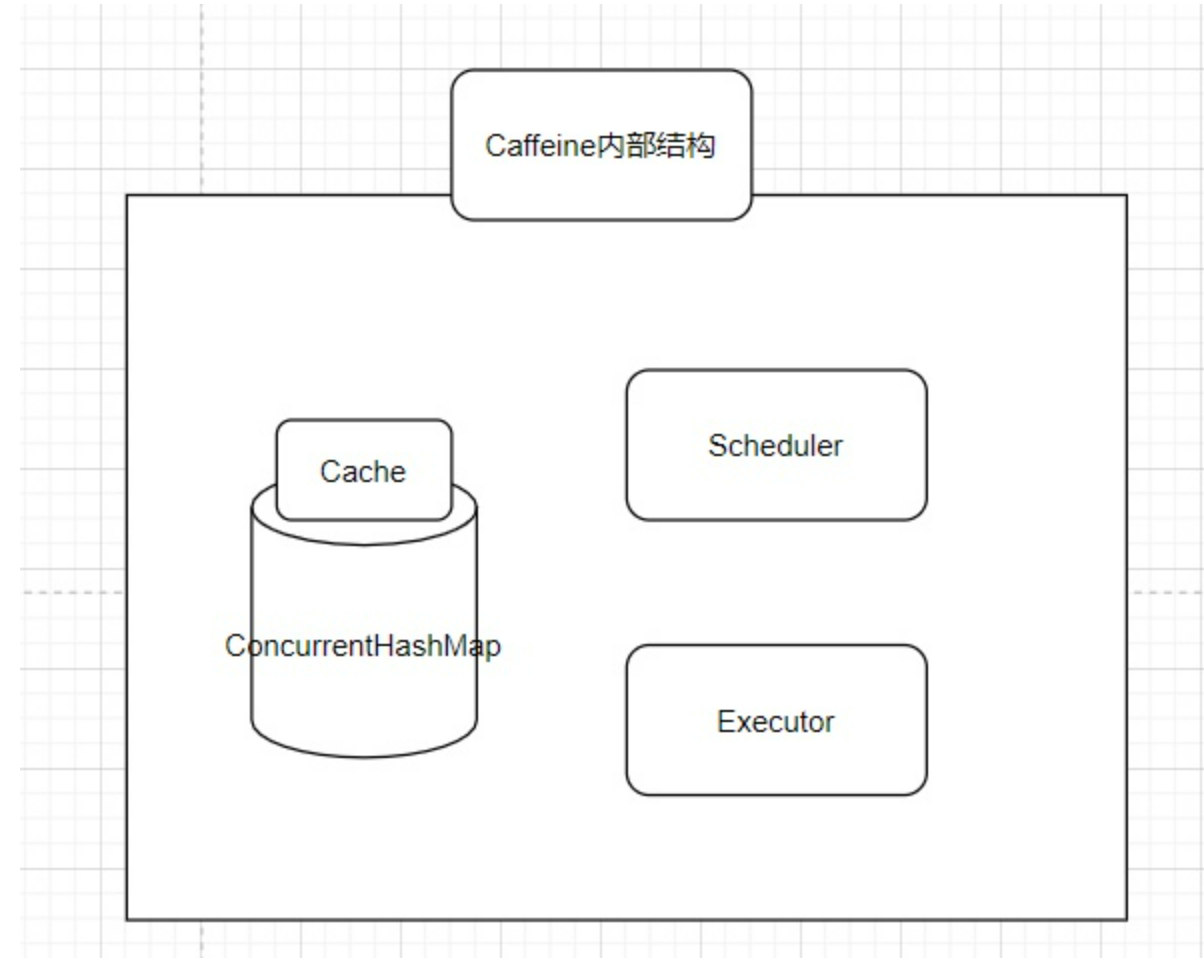
- Cache的内部包含着一个ConcurrentHashMap,这也是存放我们所有缓存数据的地方。
- Scheduler,定期清空数据的一个机制,可以不设置,如果不设置则不会主动的清空过期数据。
- Executor,指定运行异步任务时要使用的线程池。
功能特性
- 基于时间的回收策略:包括写入时间和访问时间
- 基于容量的回收策略:一种是基于容量大小,一种是基于权重大小,两者只能取其一。
- 基于数量回收策略
- 基于引用的回收策略:GC并且内存不足时,会触发软引用回收策略;GC并且内存不足时,会触发软引用回收策略。
- value自动封装弱引用或软引用
- 缓存访问统计
使用方式
引入依赖
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId></dependency>
手动创建缓存
Cache<Object, Object> cache = Caffeine.newBuilder()//初始数量.initialCapacity(10)//最大条数.maximumSize(10)//PS:expireAfterWrite和expireAfterAccess同时存在时,以expireAfterWrite为准。//最后一次写操作后经过指定时间过期.expireAfterWrite(1, TimeUnit.SECONDS)//最后一次读或写操作后经过指定时间过期.expireAfterAccess(1, TimeUnit.SECONDS)//监听缓存被移除.removalListener((key, val, removalCause) -> { })//记录命中.recordStats().build();cache.put("1","张三");System.out.println(cache.getIfPresent("1"));System.out.println(cache.get("2",o -> "默认值"));
自动添加缓存
LoadingCache<String, String> cache = Caffeine.newBuilder().maximumSize(10_000).expireAfterWrite(10, TimeUnit.MINUTES).build(new CacheLoader<String, String>() {@Nullable@Overridepublic String load(@NonNull String s) throws Exception {System.out.println("load:" + s);return "小明";}@Overridepublic @NonNullMap<String, String> loadAll(@NonNull Iterable<? extends String> keys) throws Exception {System.out.println("loadAll:" + keys);Map<String, String> map = new HashMap<>();map.put("phone", "188888888888");map.put("address", "深圳");return map;}});//查找缓存,如果缓存不存在则生成缓存元素,如果无法生成则返回nullString name = cache.get("name");System.out.println("name:" + name);//批量查找缓存,如果缓存不存在则生成缓存元素Map<String, String> graphs = cache.getAll(Arrays.asList("phone", "address"));System.out.println(graphs);
异步加载缓存
AsyncLoadingCache<String, String> asyncLoadingCache = Caffeine.newBuilder()//创建缓存或者最近一次更新缓存后经过指定时间间隔刷新缓存;仅支持LoadingCache.refreshAfterWrite(1, TimeUnit.SECONDS).expireAfterWrite(1, TimeUnit.SECONDS).expireAfterAccess(1, TimeUnit.SECONDS).maximumSize(10)//根据key查询数据库里面的值.buildAsync(key -> {Thread.sleep(1000);return "hello world";});System.out.println("come in ");//异步缓存返回的是CompletableFutureCompletableFuture<String> future = asyncLoadingCache.get("1");System.out.println(future.get());
缓存策略
/*** 最大数量* @throws InterruptedException*/@Testpublic void maximumSizeTest() throws InterruptedException {Cache<Integer, Integer> cache = Caffeine.newBuilder()//超过10个后会使用LFU算法进行淘汰.maximumSize(10).build();for (int i = 1; i < 20; i++) {cache.put(i, i);}Thread.sleep(500);//缓存淘汰是异步的// 打印还没被淘汰的缓存System.out.println(cache.asMap());}/*** 权重淘汰*/@Testpublic void maximumWeightTest() throws InterruptedException {Cache<Integer, Integer> cache = Caffeine.newBuilder()//限制总权重,若所有缓存的权重加起来>总权重就会淘汰权重小的缓存.maximumWeight(100).weigher((Weigher<Integer, Integer>) (key, value) -> key).build();for (int i = 1; i < 20; i++) {cache.put(i, i);}Thread.sleep(500);//缓存淘汰是异步的// 打印还没被淘汰的缓存System.out.println(cache.asMap());}/*** 访问后到期(每次访问都会重置时间,也就是说如果一直被访问就不会被淘汰)*/@Testpublic void expireAfterAccessTest() throws InterruptedException {Cache<Integer, Integer> cache = Caffeine.newBuilder().expireAfterAccess(1, TimeUnit.SECONDS).build();cache.put(1, 2);System.out.println(cache.getIfPresent(1));Thread.sleep(3000);System.out.println(cache.getIfPresent(1));//null}/*** 写入后到期*/@Testpublic void expireAfterWriteTest() throws InterruptedException {Cache<Integer, Integer> cache = Caffeine.newBuilder().expireAfterWrite(1, TimeUnit.SECONDS).build();cache.put(1, 2);Thread.sleep(3000);System.out.println(cache.getIfPresent(1));//null}总结
Caffeine 是当前优秀的内存缓存框架,无论读还是写的效率都远高于其他缓存,从 Spring5 开始的默认缓存实现就将 Caffeine 代替原来的Google Guava,支持多种回收策略,感兴趣的小伙伴赶快去试试吧~
这篇关于Java 的高性能缓存库-caffeine!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








