本文主要是介绍【生产力++】脚本自动化提取待复习内容 极大提高复习效率(上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前言
- 正文
- 实现思路
- java脚本开发
- 首先配置pom引入相关依赖
- 然后开始编写逻辑代码
- 解释几个地方:
- 结合bat脚本
- 编写bat脚本
- 效果展示
- 这个程序的拓展性
- 尾声
前言
【插入一句】这个的第二版脚本出来啦,有兴趣可以来看看,或许可以帮助到你
传送门(第二版)
【简单介绍一下大致背景 方便大家更快的get到这个东西的作用】
作为一只计算机的考研狗,每天起早贪黑,日复一日的复习。
知识越来越丰富,头发也越来越稀疏hhh

伴随着时间推移到了八月中,相比于刚刚开始备考的几个月,学科难度持续增大,学习项目越来越庞杂。因此每天的学习热情已经趋于平淡,但又秉持着必要上岸的决心,每天能不能坚持9h+的全凭意志力。(偶尔摆烂呜呜)

在英语的复习中,大纲词汇要背,阅读生词要背诵,真题熟词僻义要背…我原本的思路是把所有地方的单词按照这个样子整理到pdf中来,每天仅需要将不熟悉的部分用高亮选中,然后每天复习就好了。
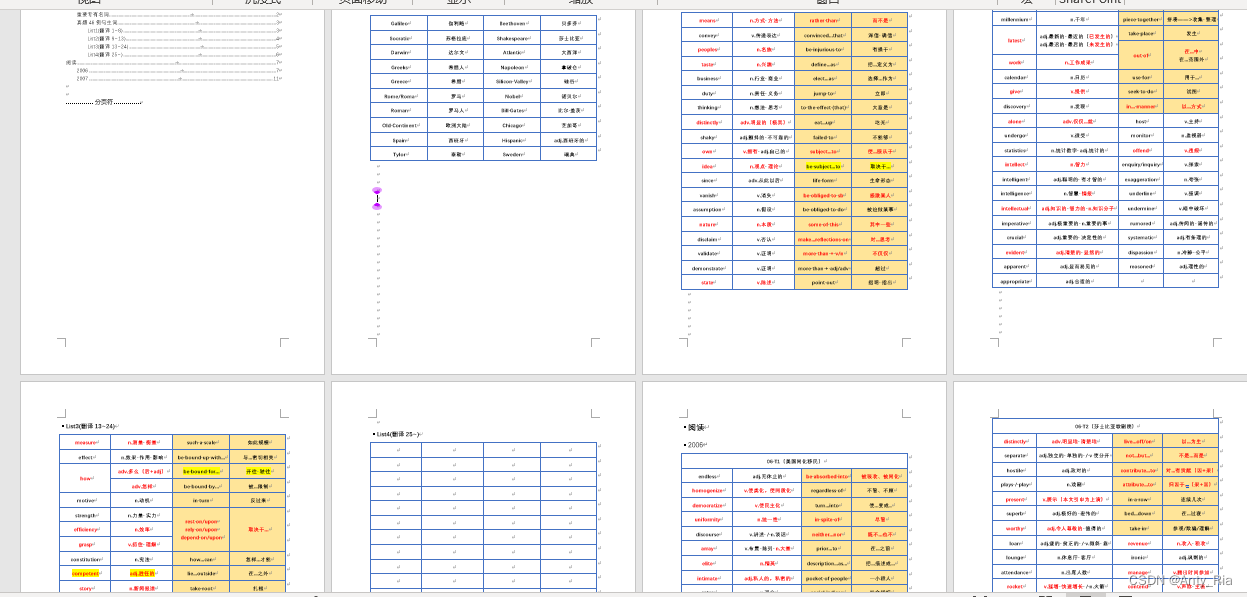
但是随着数量越来越多之后,我发现了一个问题,不熟悉的单词东一个西一个,可能阅读部分有几个,翻译部分有几个…这总不能一页页翻过去找吧…本来就时间紧任务重。那有没有一个办法能把我不会的单词统一到一起,这样我就可以很快速的进行复习了。
左思右想之后,敲定了几种方案:
× 使用word自带的宏,进行编程,实现效果。但是不具备宏编程基础,并且宏编程界面跟记事本一样…开发起来很头痛,会付出很多的额外时间成本。
√ 使用bat脚本+java脚本的方式 实现,之前有研究过bat脚本和java结合的方式,且java使用更加得心应手。
说干就干!!!
正文
实现思路
原来的复习方式 主要分为两部分:
①新词产生:学习产生陌生词汇——登记到word中——高亮标记需要重复学习的部分
②旧词复习:从后向前遍历每一页的新词,若掌握则去除标记,发现新的未掌握则添加标记。
主要的时间开销:在N页的文档中寻找需要复习的单词。
理想的复习方式:
着重针对寻找待复习单词方面进行优化
①新词产生:学习产生陌生词汇——登记到word中——高亮标记需要重复学习的部分
②旧词复习:由脚本帮忙整理出待复习的新词,若全部掌握即可回到文档直接 “全选-去除高亮”。
java脚本开发
省略中间选择实现方式的思考过程,最终选择使用 spire.doc.free的工具包完成
整体使用maven管理项目
首先配置pom引入相关依赖
<dependency><groupId>e-iceblue</groupId><artifactId>spire.doc.free</artifactId><version>3.9.0</version></dependency>
这家伙不像其他依赖那么简单就能引入,他需要配置一下自己的仓库,同样在pom文件中
<!-- 配置word的仓库--><repositories><repository><id>com.e-iceblue</id><url>http://repo.e-iceblue.cn/repository/maven-public/</url></repository></repositories>
然后开始编写逻辑代码
我的word长这样,每一页都是一个N行4列的表格,其中一、三列英语,二、四列汉语。
除了普通的一个单词对应一个汉语,还存在一个单词对应多个汉语,或者多个单词对应一个汉语的情况。
首先简单介绍一下这个依赖读入word文件的流程(具体的实现可以根据名字去查开发手册):
【其实就是读入遍历循环的顺序】
- 将整个文档根据分节符分成很多节
- 将每一节根据我们文档的表格分成很多个表格
- 将每一张表分成很多行
- 将每一行分成很多列
- 将单元格拆分为段落(这个比较抽象 比如回车一下算一段)
- 将段落拆为不同的对象(这个更抽象 可以结合代码理解)
直接上成品代码(后续有解释)
import com.spire.doc.Document;
import com.spire.doc.Section;
import com.spire.doc.TableCell;
import com.spire.doc.TableRow;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.fields.TextRange;
import com.spire.doc.interfaces.ITable;import java.awt.*;public class word_op {public static void main(String[] args) {//加载Word源文档Document doc = new Document();doc.loadFromFile("C:\\Users\\23252\\Desktop\\真题词汇词组.docx");//获取第一节Section section = doc.getSections().get(0);for (int i = 0; i < section.getTables().getCount(); i++) {//获取第i个表格ITable table = section.getTables().get(i);//遍历每个表格的行for (int j = 0; j < table.getRows().getCount(); j++) {TableRow row = table.getRows().get(j);//遍历每行的列for (int k = 0; k < row.getCells().getCount(); k++) {TableCell cell = row.getCells().get(k);//某个单元格整体的内容StringBuilder res = new StringBuilder();//遍历单元格中的段落for (int l = 0; l < cell.getParagraphs().getCount(); l++) {Paragraph paragraph = cell.getParagraphs().get(l);//遍历每个段落的子对象for (int m = 0; m < paragraph.getChildObjects().getCount(); m++) {Object obj = paragraph.getChildObjects().get(m);if (obj instanceof TextRange) {//获取文本String text = ((TextRange) obj).getText();//去除特殊符号text = text.replaceAll("\r|\n", "");//获取文本的高亮颜色(即突出显示颜色)Color color = ((TextRange) obj).getCharacterFormat().getHighlightColor();//判断是否高亮if (!(color.getRGB() == 0)) {res.append(text);//判断是否有多段 进行分割if (cell.getParagraphs().getCount() != 1 && m == paragraph.getChildObjects().getCount() - 1) {//最后一段后面没东西 不需要再加分割if (cell.getParagraphs().getCount() - 1 != l) {res.append(" | ");}}}}}}if (!res.toString().equals("")) {if ((k + 1) % 2 != 0) {System.out.print(generateWordSpan(res.toString()));} else {System.out.println(res);}}}}}}// 组合总长public static int total_length = 50; //30+20// 根据单词长度动态生成后端空格组合public static String generateWordSpan(String word) {int span_length = total_length - word.length();StringBuilder op_word = new StringBuilder(word);for (int i = 0; i < span_length; i++) {op_word.append(" ");}return op_word.toString();}
}解释几个地方:
- 首先是这一部分那个append操作在叠加什么
//遍历每个段落的子对象for (int m = 0; m < paragraph.getChildObjects().getCount(); m++) {Object obj = paragraph.getChildObjects().get(m);if (obj instanceof TextRange) {//获取文本String text = ((TextRange) obj).getText();//去除特殊符号text = text.replaceAll("\r|\n", "");//获取文本的高亮颜色(即突出显示颜色)Color color = ((TextRange) obj).getCharacterFormat().getHighlightColor();//判断是否高亮if (!(color.getRGB() == 0)) {res.append(text);//判断是否有多段 进行分割if (cell.getParagraphs().getCount() != 1 && m == paragraph.getChildObjects().getCount() - 1) {//最后一段后面没东西 不需要再加分割if (cell.getParagraphs().getCount() - 1 != l) {res.append(" | ");}}}}}
首先很明确的是,用我们的视角来看,我们想要的目标是一个单元格,我们只有拿到一整个单元格的内容才能把数据存下来到数组啊,链表啊之类的。我们的操作对象既不是比单元格大的行、列,也不是比单元格更小的段落或者对象。
但是在程序的视角来看,单元格由段落组成,段落由对象组成。
那么我们就需要把较小的东西拼起来,凑成我们想要的东西。
所以核心逻辑就是:从word读入文件,一轮轮for循环下去,不断切切切,切到最小,然后我们操作着最小的对象开始拼装。
- 这部分动态组合是在干什么
// 组合总长public static int total_length = 50; //30+20// 根据单词长度动态生成后端空格组合public static String generateWordSpan(String word) {int span_length = total_length - word.length();StringBuilder op_word = new StringBuilder(word);for (int i = 0; i < span_length; i++) {op_word.append(" ");}return op_word.toString();}
这部分相对于上面那部分就简单太多啦,纯粹是因为个人强迫症。
因为单词不一样长,所以他和汉语之间的空格也不一样,所以最后控制台打印出来会歪歪扭扭,于是我设置了 单词+空格+汉语 的总长,一个太长另一个就短一点,也算是自己实现了动态调剂算法哈哈哈哈。
其他地方不难理解,可以按着我的样子建个表,然后自己代码贴过去跑一跑,很快就能理解。
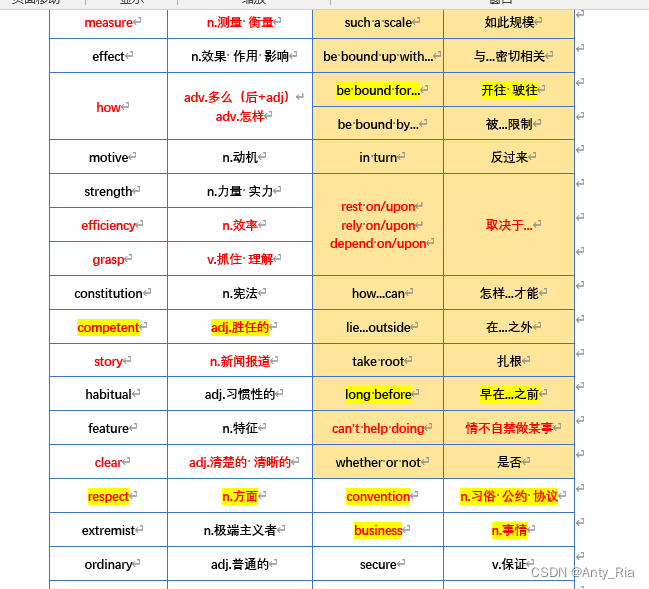
贴一个效果图,节选了上面那一页的部分。

是不是很整齐

到这里
结合bat脚本
到这里,我们需要把写好的文件打成jar包或者exe文件,方便我们bat脚本调用(打jar包过程可以看我其他文章或者自行百度),这里因为习惯就打jar包了。

编写bat脚本
接下来我们可以写一个启动脚本,运行这个java程序,目前这个简易版的小脚本只有下面这三句。
cd C:\XXXX (你的脚本的目录)
java -jar XXXXX.jar (你的jar包的名字)
pause > nul (这一句是为了让你的窗口执行完停下来,而不是直接闪退,可以多贴几行防止手误)
把这句话写到记事本里,保存为bat文件。
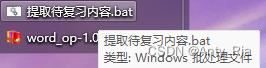
效果展示
双击bat文件,等待之后。

成功啦!!!正文部分到这里完全结束!!!接下来是小的碎碎念时间。
这个程序的拓展性
假设场景:在学校,白天去图书馆懒得搬电脑:
或许我们可以在java脚本中加一段发送邮件的代码(很简单),这样每天早上出门前运行一下代码,待复习内容就可以发送到邮箱,手机就可以随时随地查看了。不过那样发过去的单词可能看起来没那么整齐哈哈哈。
后续可能方案:做一个简单的图形化界面,在界面上通过勾选框选择已经掌握的单词,bat界面关闭后自动修改word文档里的高亮标识。(这个不难但是我是懒狗现在不想做)
高性价比方案:当前脚本保持不变,配合远程控制软件ToDesk使用,在图书馆使用iPad链接寝室的电脑,仅需双击bat文件,通过pad屏幕来看打印出来的单词,我们仅需要在晚上睡前修改一下待复习单词。
尾声
到这里也算是终于结束啦,原本预定一早上搞定,但是因为有段日子没有写过代码了,手有点生。
从完全不了解spire.doc.free这个依赖,到自己看开发文档,再到设计实现逻辑,还是学到了很多东西。
整个程序看起来不是很难,但每一步都不容出错。代码虽然很短,但是其中的核心逻辑大改了三遍hhh(纯菜狗了哈哈哈),从开始设计到写完这篇博客,用了大半天时间。今天是光明正大的摆烂的一天。

这篇关于【生产力++】脚本自动化提取待复习内容 极大提高复习效率(上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




