本文主要是介绍SAS实现临床试验前动态随机化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SAS实现临床试验前动态随机化
方法介绍
临床试验前的随机化分组目的在于保证各个试验组间的非研究因素达到均衡。与传统随机化方法相比,动态随机化法的不同之处在于,动态随机化在分配过程中,每一个受试人员进入某一组的概率不会一直保持固定,而是按照前面已入组个体的情况不断地进行变更,从而达到维持所有试验组之间非研究因素达到平衡的目的。每当有新的受试人员进入试验,研究者首先要假设该受试人员进入每一个组的情况,通过统计每组累计的各因素各水平的数目,并乘以一定的权重w(非研究因素间的相对重要性,下面设定为1),来计算不同分配情况下的均衡程度,两相比较后,最后以某一概率(如80%)将受试人员分入某一假设情况下试验组因素间差最小的试验组,以保持良好的均衡性。
假设试验中有N个试验组,M个非处理因素,各因素的水平数分布为LM,Xijk为第i个试验组中因素j水平k的人数(i=1,2,…,N;j=1,2,…,M;k=1,2,…,LM)。受试者入组时,要首先考虑其进入不同试验组后产生的情况。
假设某3因素2水平(2×2×2)的试验需入组一名各因素分别为1,1,2水平(圆括号表示)的受试人员,原有受试人员的累计数量如表1、表2(非圆括号的数字表示两组已入组人员的因素水平的累计情况):


由表1,表2分别计算出假设新受试个体进入两试验组的情况下,试验组内每个因素的累计水平数即Xijk,再计算表示在与新个体相同因素水平下组1和组2之间的差异Djk值。Pocock和Simon提出了四种计算Djk值的方法,包括极差法、方差法、最大限值法和符号法,其中最常用的是极差法(Djk=|Xi1jk-Xi2jk|)和方差法(Djk=Var(Xi1jk,Xi2jk,…,XiNjk)),这里使用极差法。
假设受试者进入组1时,组1和组2之间的各因素水平差Djk为:
D11=|X111-X211 |=1,
D21=|X121-X221 |=1,
D32=|X111-X232 |=2,
计算总的不均衡值(不妨假设因素重要性相同,权重w全部设定为1),
G1=w1 D11+w2 D21+w3 D32=4.
假设受试者进入组2时,组1和组2之间的各因素水平差Djk为:
D11=|X111-X211 |=3,
D21=|X121-X221 |=1,
D32=|X111-X232 |=4,
计算总的不均衡值(不妨假设因素重要性相同,权重w全部设定为1),
G2=w1 D11+w2 D21+w3 D32=8.
w为各因素的权重,这里全部设为1。由于G1<G2,受试个体进入组1时两组的非研究因素差值较小,表示进入组1时两组的均匀性比进入b组要好,所以设定新的受试者进入组1的概率更高80%)。在实际应用中,若出现G1=G2,优先进入例数少的组,若例数在两组也相等,则进入每组的概率相等。相对于其他的随机化方法,动态随机化综合考量了全部非处理因素的平衡,即使在受试者总人数较少的情况下也能保证良好的均衡性。
SAS9.4代码(八因素(水平不限)动态随机化)
options nodate nonotes nosource;
/*
编号:【ID】001 002 …
因素1:f1
记录日期:date(作为生成随机数的种子数)
因素2:f2
因素3:f3
因素4:f4
因素5:f5
因素6:f6
因素7:f7
因素8:f8
*/
data patient;
input ID $ f1 Date mmddyy10. f2 f3 f4 f5 f6 f7 f8;
cards;
001 1 12-02-2017 1 1 2 1 2 1 1
002 1 01-11-2018 1 2 2 1 2 2 2
003 3 02-05-2018 1 1 1 1 2 1 1
004 1 03-02-2018 1 2 2 1 2 1 1
005 3 04-19-2018 1 2 1 2 1 1 2
006 1 05-08-2018 1 2 2 2 2 1 2
007 1 05-25-2018 1 2 1 2 2 1 1
008 1 06-15-2018 2 1 2 2 2 1 1
009 1 07-13-2018 1 1 2 1 2 2 1
010 1 09-24-2018 1 1 2 2 2 1 2
;
run;
data dataset;
set patient;
i+1;
run;
/*以上是录入数据,最新一行可视作新入组受试个体*//*模拟程序:*/
%let nobs=10;
proc sql; /*建立空表*/
create table test
(ID char(8), /*病人编号*/f1 num(3),f2 num(3),f3 num(3),f4 num(3),f5 num(3), f6 num(3),f7 num(3),f8 num(3),/*考虑的因素*/date num(10) ,group_ char(3), /*分组*/DiffA num(3), /*假设新个体纳入A组时,两组在新个体相同水平上的差异*/DiffB num(3), /*假设新个体纳入B组时,两组在新个体相同水平上的差异*/P num(3)
);
quit;%macro DR(id,f1,f2,f3,f4,f5,f6,f7,f8,date); /*输入编号,非处理因素f1-f8,入组时间*/
proc sql NOPRINT;
insert into test /*假设受试个体纳入A组时,A组与新个体在各因素的水平相同的频数*/
set id="&id" ,f1= %sysevalf(&f1+0),f2= %sysevalf(&f2+0),f3= %sysevalf(&f3+0),f4= %sysevalf(&f4+0),f5= %sysevalf(&f5+0),f6= %sysevalf(&f6+0),f7= %sysevalf(&f7+0),f8= %sysevalf(&f8+0),date=%sysevalf(&date+0),group_='A';
select count(f1) into :AAcount_f1 from test where f1= %sysevalf(&f1) and group_='A';
select count(f2) into :AAcount_f2 from test where f2= %sysevalf(&f2) and group_='A';
select count(f3) into :AAcount_f3 from test where f3= %sysevalf(&f3) and group_='A';
select count(f4) into :AAcount_f4 from test where f4= %sysevalf(&f4) and group_='A';
select count(f5) into :AAcount_f5 from test where f5= %sysevalf(&f5) and group_='A';
select count(f6) into :AAcount_f6 from test where f6= %sysevalf(&f6) and group_='A';
select count(f7) into :AAcount_f7 from test where f7= %sysevalf(&f7) and group_='A';
select count(f8) into :AAcount_f8 from test where f8= %sysevalf(&f8) and group_='A';/*假设受试个体纳入A组时,B组与新个体在各因素的水平相同的频数*/
select count(f1) into :ABcount_f1 from test where f1= %sysevalf(&f1) and group_='B';
select count(f2) into :ABcount_f2 from test where f2= %sysevalf(&f2) and group_='B';
select count(f3) into :ABcount_f3 from test where f3= %sysevalf(&f3) and group_='B';
select count(f4) into :ABcount_f4 from test where f4= %sysevalf(&f4) and group_='B';
select count(f5) into :ABcount_f5 from test where f5= %sysevalf(&f5) and group_='B';
select count(f6) into :ABcount_f6 from test where f6= %sysevalf(&f6) and group_='B';
select count(f7) into :ABcount_f7 from test where f7= %sysevalf(&f7) and group_='B';
select count(f8) into :ABcount_f8 from test where f8= %sysevalf(&f8) and group_='B';update test
set group_= 'B' where id="&id"; /*假设受试个体纳入B组时,A组与新个体在各因素的水平相同的频数*/
select count(f1) into :BAcount_f1 from test where f1= %sysevalf(&f1) and group_='A';
select count(f2) into :BAcount_f2 from test where f2= %sysevalf(&f2) and group_='A';
select count(f3) into :BAcount_f3 from test where f3= %sysevalf(&f3) and group_='A';
select count(f4) into :BAcount_f4 from test where f4= %sysevalf(&f4) and group_='A';
select count(f5) into :BAcount_f5 from test where f5= %sysevalf(&f5) and group_='A';
select count(f6) into :BAcount_f6 from test where f6= %sysevalf(&f6) and group_='A';
select count(f7) into :BAcount_f7 from test where f7= %sysevalf(&f7) and group_='A';
select count(f8) into :BAcount_f8 from test where f8= %sysevalf(&f8) and group_='A';/*假设受试个体纳入B组时,B组与新个体在各因素的水平相同的频数*/
select count(f1) into :BBcount_f1 from test where f1= %sysevalf(&f1) and group_='B';
select count(f2) into :BBcount_f2 from test where f2= %sysevalf(&f2) and group_='B';
select count(f3) into :BBcount_f3 from test where f3= %sysevalf(&f3) and group_='B';
select count(f4) into :BBcount_f4 from test where f4= %sysevalf(&f4) and group_='B';
select count(f5) into :BBcount_f5 from test where f5= %sysevalf(&f5) and group_='B';
select count(f6) into :BBcount_f6 from test where f6= %sysevalf(&f6) and group_='B';
select count(f7) into :BBcount_f7 from test where f7= %sysevalf(&f7) and group_='B';
select count(f8) into :BBcount_f8 from test where f8= %sysevalf(&f8) and group_='B';
quit;
proc sql noprint;
select count(*) into :count_A from test where id^="&id" and group_="A";
select count(*) into :count_B from test where id^="&id" and group_="B";
quit;/*在Test数据集中入组对应信息,1对应A,2对应B(对照组)*/
data test;
set test;
format date DDMMYY10.;
if id="&id" then
do;
count_A=%sysevalf(&count_A+0); count_B=%sysevalf(&count_B+0);
date= %sysevalf(&date);
seed=%sysevalf(&date*&id);/*假设受试个体纳入A组时,A组与新个体在各因素的水平相同的频数总和*/
DiffA=%sysevalf(%sysfunc(abs(&AAcount_f1-&ABcount_f1))+%sysfunc(abs(&AAcount_f2-&ABcount_f2))+%sysfunc(abs(&AAcount_f3-&ABcount_f3))+%sysfunc(abs(&AAcount_f4-&ABcount_f4))+%sysfunc(abs(&AAcount_f5-&ABcount_f5))+%sysfunc(abs(&AAcount_f6-&ABcount_f6))+%sysfunc(abs(&AAcount_f7-&ABcount_f7))+%sysfunc(abs(&AAcount_f8-&ABcount_f8)));
DiffB=%sysevalf(%sysfunc(abs(&BAcount_f1-&BBcount_f1))+%sysfunc(abs(&BAcount_f2-&BBcount_f2))+%sysfunc(abs(&BAcount_f3-&BBcount_f3))+%sysfunc(abs(&BAcount_f4-&BBcount_f4))+%sysfunc(abs(&BAcount_f5-&BBcount_f5))+%sysfunc(abs(&BAcount_f6-&BBcount_f6))+%sysfunc(abs(&BAcount_f7-&BBcount_f7))+%sysfunc(abs(&BAcount_f8-&BBcount_f8)));/*假设受试个体纳入A组时,B组与新个体在各因素的水平相同的频数总和*/if DiffA=DiffB then do; /*差异相等时,按相等概率进入A组或B组*/
P=uniform(%sysevalf(&date*&id)); if count_A=count_B then do;
if P<0.5 then group_='A' ; else group_='B';end;
if count_A<count_B then do;
if P<0.8 then group_='A' ; else group_='B';end;
if count_A>count_B then do;
if P<0.8 then group_='B' ; else group_='A';end;
end;if DiffA<DiffB then /*A组差异较小时,按0.8概率进入A组,0.2概率进入B组*/
do;
P=uniform(%sysevalf(&date*&id));
if P<=0.8 then group_='A' ; else group_='B';
end;if DiffA>DiffB then /*B组差异较小时,按0.8概率进入B组,0.2概率进入A组*/
do;
P=uniform(%sysevalf(&date*&id));
if P<=0.8 then group_='B' ; else group_='A';
end;
end;
run;
%mend;%macro test;
%do t=1 %to &nobs;
proc sql noprint;
select id,f1,f2,f3,f4,f5,f6,f7,f8,date into :id, :f1,:f2,:f3,:f4,:f5,:f6,:f7,:f8,:date from dataset where i=%sysevalf(&t);
quit;
%let id=&id; /*需要在宏test里面用%let赋值转换成局部宏参数,另一种方法用%global声明亦可*/
%let F_1=%sysevalf(&f1);
%let F_2=%sysevalf(&f2);
%let F_3=%sysevalf(&f3);
%let F_4=%sysevalf(&f4);
%let F_5=%sysevalf(&f5);
%let F_6=%sysevalf(&f6);
%let F_7=%sysevalf(&f7);
%let F_8=%sysevalf(&f8);
%let seed=%sysevalf(&date);
%DR(&id,&f_1,&f_2,&f_3,&f_4,&f_5,&f_6,&f_7,&f_8,&seed);
%end;
run;
%mend;
%test;
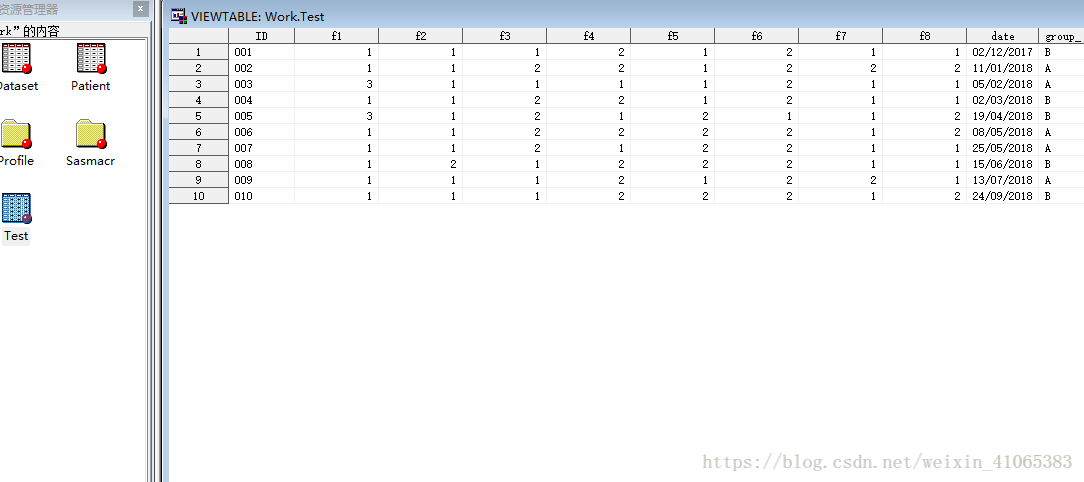
sas程序结果如下,work.test数据集中给出了新个体010的分组分组结果,如再有新个体011,在patient数据集中录入新个体各因素数并将全局宏变量nobs赋值为11即可.
这篇关于SAS实现临床试验前动态随机化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





