本文主要是介绍X-VLM:多粒度视觉语言预训练方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文:Zeng, Yan, Xinsong Zhang and Hang Li. “Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts.” ArXiv abs/2111.08276 (2021).
源码:https://github.com/zengyan-97/x-vlm
现有的视觉语言预训练方法大多依赖于通过目标检测提取的以对象为中心的特征,并在提取的特征和文本之间进行细粒度的对齐。我们认为,视觉语言预训练可能不需要目标检测。为此,我们提出了一种新的方法X-VLM来进行“多粒度视觉语言预训练”。学习多粒度对齐的关键是在给定关联文本的图像中定位视觉概念,同时将文本与视觉概念进行对齐,对齐方式是多粒度的。实验结果表明,X-VLM可以有效地将学习到的对齐用到许多下游视觉语言任务上,并始终优于现有的SOTA方法。
★ 相关工作
ALIGN:基于噪声文本监督的视觉和视觉语言表示学习
VL-BERT:可预训练的通用视觉语言表征模型
VinVL:视觉语言模型中的视觉表示
★ 论文故事
视觉语言预训练旨在从大量图像-文本对中学习视觉语言对齐。预训练好的视觉语言模型(VLM)通过少量的标记数据进行微调,在许多视觉语言(V+L)任务中达到了SOTA性能,如视觉问答和图文检索。

图1:视觉语言预训练方法的比较:(a)基于目标检测的方法,(b)文本与整个图像对齐的方法,(c)我们的X-VLM方法。
现有的视觉语言对齐方法分为两种,如图1(a,b)所示。它们大多检测图像中的对象,并将文本与细粒度(以对象为中心)特征对齐。他们要么利用预训练的目标检测器,要么在预训练过程中进行实时目标检测。其他方法不依赖于目标检测,只学习文本和图像粗粒度(整体)特征之间的对齐。
细粒度和粗粒度方法都有缺点。目标检测识别图像中所有可能的对象,其中一些可能与文本无关。以对象为中心的特征无法轻松表示多个对象之间的关系,例如“过街的人”。此外,预定义适合下游任务的对象类别是有挑战性的。另一方面,粗粒度方法无法有效地学习视觉和语言之间的细粒度对齐,例如对象级别,这对于一些下游任务(如视觉推理和视觉定位)至关重要。
理想情况下,我们希望VLM能够在预训练中学习视觉和语言之间的多粒度对齐,而不局限于对象级或图像级,并将学习到的对齐应用到下游的V+L任务中。不幸的是,现有的方法不能令人满意地处理视觉和语言之间的多粒度对齐。
在本文中,我们提出通过将文本描述与图像中相应的视觉概念对齐来进行多粒度视觉语言预训练。以图1为例,我们有以下训练数据:1)描述整个图像的图像标题;2) 区域标记,例如“背包男”,每个标记都与图像中的一个区域相关,而以前的方法大致将区域描述与整个图像对齐;3) 物体标签,如“背包”,这是以前的方法用来训练目标检测器的。我们重新定义了数据,这样一幅图像就可以有多个边界框,文本与每个框中的视觉概念直接关联。“视觉概念”可以是对象、区域或图像本身,如图1(c)中的示例。通过这样做,我们的方法学习到了与各种文本描述相关的视觉概念,这些概念也不局限于对象级或图像级。
我们的多粒度模型称为X-VLM,由图像编码器(生成图像中视觉概念的表示)、文本编码器和跨模态编码器组成,跨模态编码器在视觉特征和语言特征之间进行跨模态注意,以学习视觉语言对齐。学习多粒度对齐的关键是优化X-VLM:1)通过结合边框回归损失和IoU损失,在给定关联文本的图像中定位视觉概念;2)同时,通过对比损失、匹配损失和掩码语言建模损失,将文本与视觉概念进行多粒度对齐,如图1(c)所示。在微调和推理中,X-VLM可以利用学习到的多粒度对齐来执行下游的V+L任务,而无需在输入图像中添加边框注释。
我们在各种下游任务上证明了X-VLM方法的有效性。在图像-文本检索方面,X-VLM学习的多粒度视觉语言对齐优于基于以对象为中心特征的VinVL,在MSCOCO上获得了4.65%的绝对提升。X-VLM也比ALIGN、ALBEF和METER有很大的优势,尽管它们在更多的数据或参数上进行了预训练。在视觉推理任务中,与VinVL相比,X-VLM在VQA和NLVR2上的分别提升了0.79%和1.06%,且推理速度更快。X-VLM也比经过18亿内部数据预训练的SimVLM base表现更好,特别是在NLVR2上,它比SimVLM base高出2.4%。在视觉定位(RefCOCO+)方面,X-VLM与UNITER相比实现了4.5%的绝对提高,与专门用于定位任务的MDETR相比实现了1.1%的绝对提高。X-VLM在图像标题任务中也具有与强基线相当的性能。源码和预训练模型可以在https://github.com/zengyan-97/x-vlm获得。
本文工作的贡献如下:1)我们提出进行多粒度视觉语言的预训练来处理文本和视觉概念之间的对齐。2)我们提出优化模型X-VLM,在给定相关文本的图像中定位视觉概念,同时将文本与视觉概念对齐,其中对齐是多粒度的。实证研究表明,我们的方法在微调中有效地利用了学习到的多粒度对齐。在许多下游V+L任务中,X-VLM的性能始终优于现有的SOTA方法。
★ 模型方法
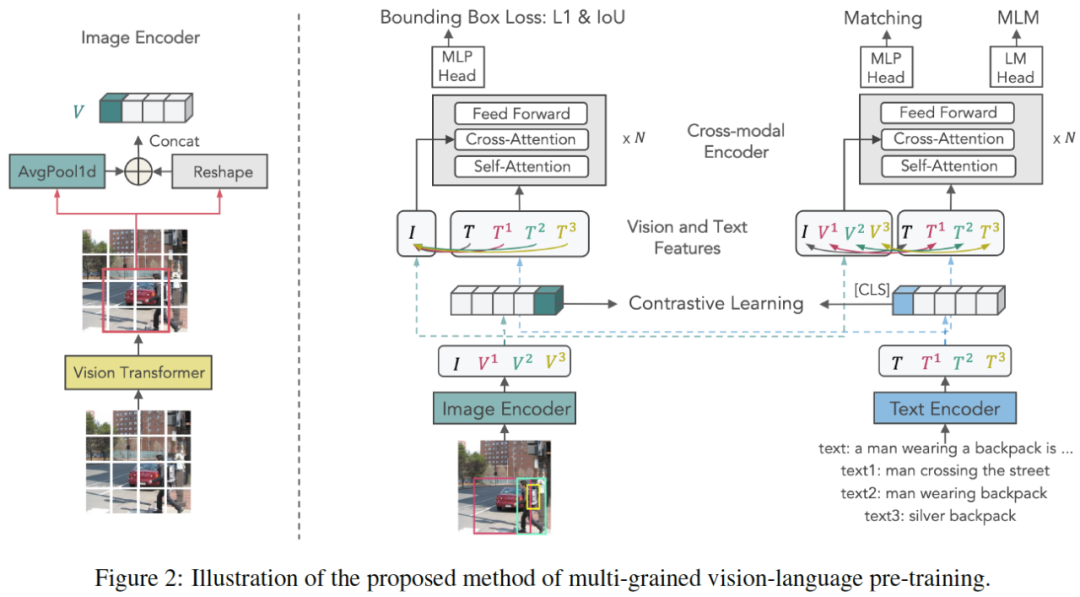
图2:本文提出的多粒度视觉语言预训练方法。
X-VLM由图像编码器、文本编码器和跨模态编码器组成。所有编码器都是基于Transformer的。跨模态编码器通过每一层的交叉注意力将视觉特征与语言特征融合在一起。如图2所示,我们通过在给定相应文本的图像中定位视觉概念,同时对齐文本和视觉概念来优化X-VLM,其中对齐是多粒度的。
★ 实验结果
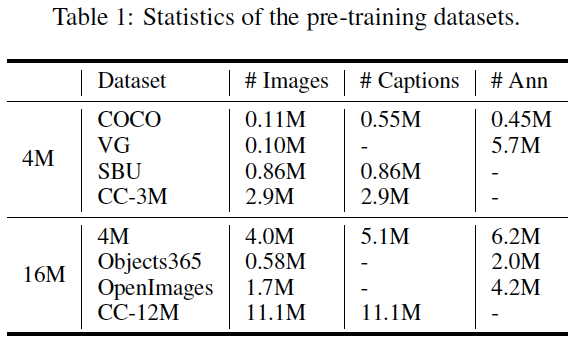
表1:预训练数据集。
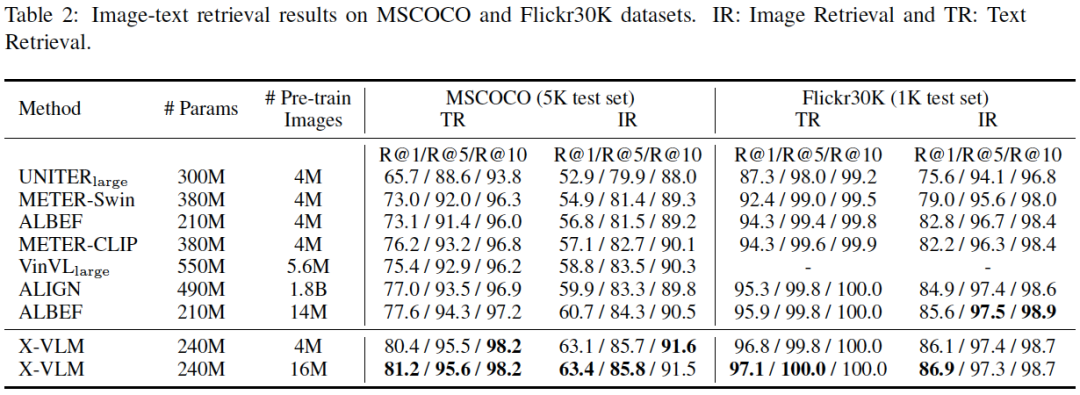
表2:MSCOCO和Flickr30K数据集上的图像-文本检索结果。IR:图像检索;TR:文本检索。
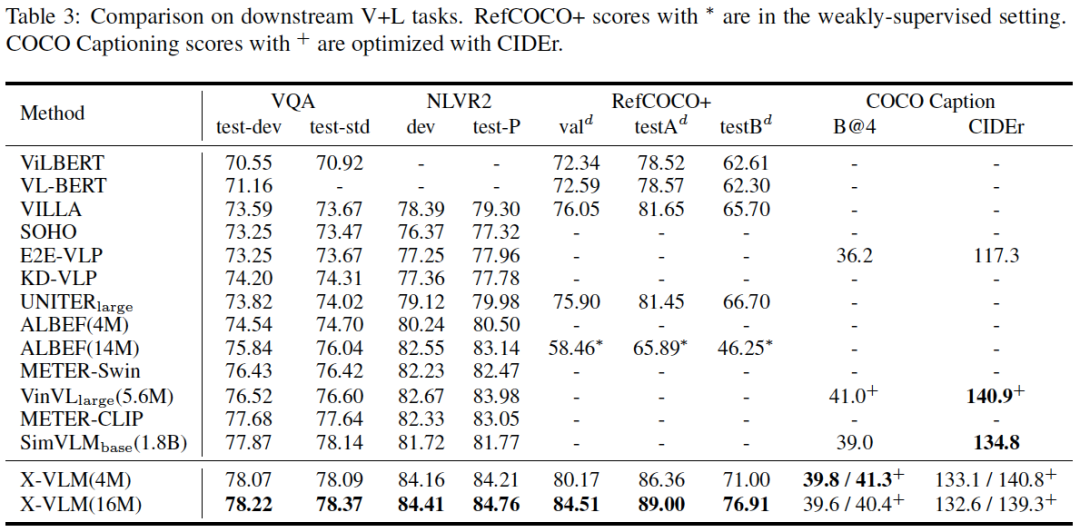
表3:下游视觉语言任务上的结果比较。

图3:在未见过的图像上的Grad-CAM可视化和边框预测。
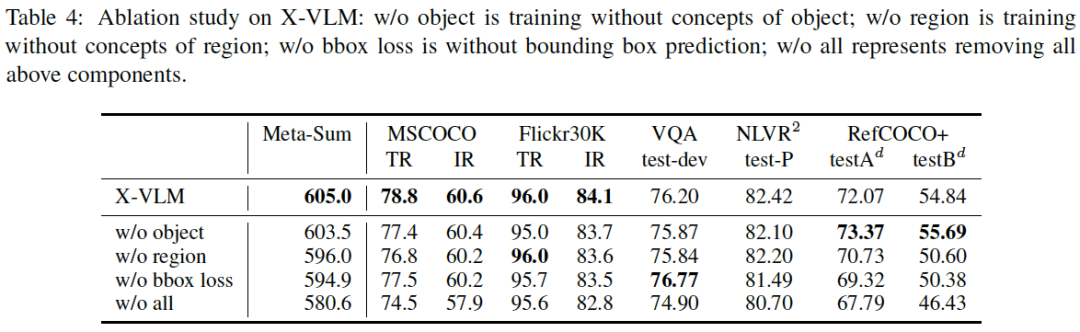
表4:X-VLM的消融研究。

图4:在未见过的给定文本描述的图像中定位视觉概念。

图5:在未见过的图像中进行边框预测和单词可视化。这表明X-VLM还可以将“拉”和“拿”等概念与图像中的相应区域进行对齐。
★ 总结讨论
现有的视觉语言模型要么使用图像的细粒度特征(以对象为中心)对齐文本,要么使用图像整体的粗粒度特征对齐文本。这两种方法虽然有效,但仍存在一些不足。本文将现有的数据集重构为图像/区域/对象-文本对,并提出了一种新的多粒度视觉语言预训练方法X-VLM。X-VLM模型的训练是通过在给定相关文本的图像中定位视觉概念,并将文本与相关的视觉概念对齐来驱动的,其中对齐是多粒度的。在图像-文本检索、视觉推理和视觉定位等视觉语言任务上的实验表明,X-VLM优于现有的SOTA方法。
多模态人工智能
为人类文明进步而努力奋斗^_^↑
欢迎关注“多模态人工智能”公众号,一起进步^_^↑
这篇关于X-VLM:多粒度视觉语言预训练方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


