本文主要是介绍利用shardingSphereJdbc实现根据主键id动态分库分表。后期就算再增加库和表。也不影响之前的业务逻辑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果你还不知道shardingSphereJdbc是什么。这段话有可能让你更清晰点
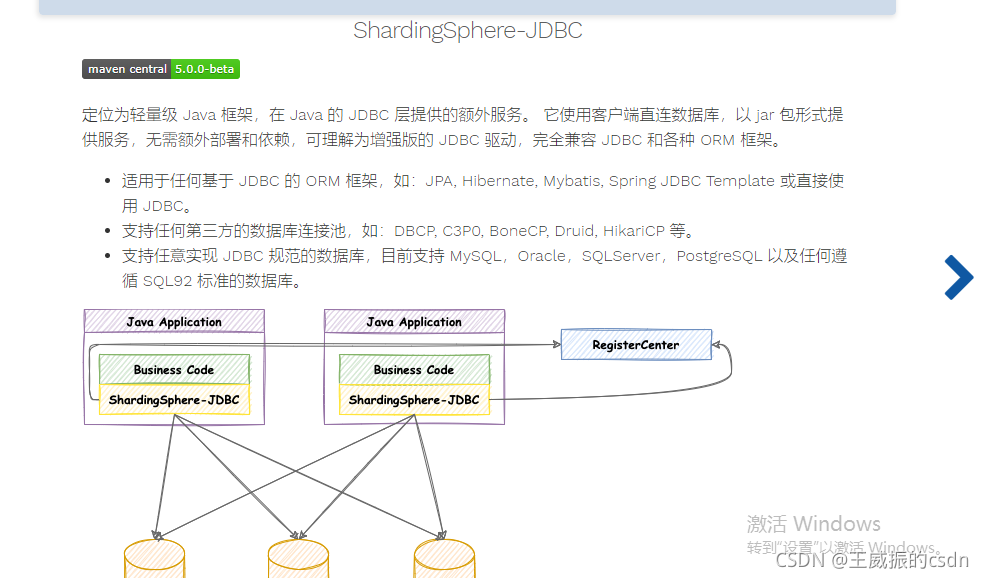
如果你想了解更多。请到官网
概览 :: ShardingSphere![]() https://shardingsphere.apache.org/document/current/cn/overview/#shardingsphere-jdbc根据主键id动态分库分表实现思路:准备两个库:ds0,ds1。两个表:sys_log0,sys_log1
https://shardingsphere.apache.org/document/current/cn/overview/#shardingsphere-jdbc根据主键id动态分库分表实现思路:准备两个库:ds0,ds1。两个表:sys_log0,sys_log1
自定义分库分表算法。利用雪花算法+自己生成的库索引+特殊字符+自己生成的表索引。例如:4031342968806410001 ===》红色部分就是库索引+000+表索引。所以就是ds1库中sys_log1表.
所以不管你怎么增加库和表。这种算法是不影响之前的业务逻辑。都可以找到你的库和表。也可能有更好的实现方式。只是我还没有遇到。
1、接下来让我们一起实现这样的算法。先把maven依赖引进来。这是第一步要做的:
<sharding-jdbc.version>4.1.1</sharding-jdbc.version>
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>${sharding-jdbc.version}</version>
</dependency>
2、然后配置分库分表规则:
分库配置:
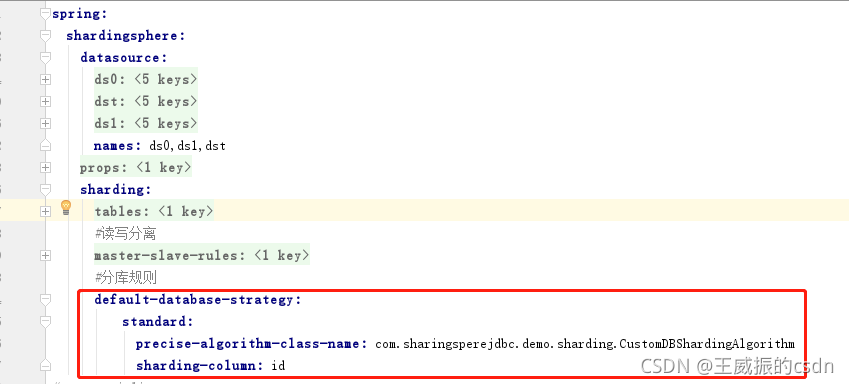
这项的类是自己自定义分库的算法。
precise-algorithm-class-name: com.sharingsperejdbc.demo.sharding.CustomDBShardingAlgorithm
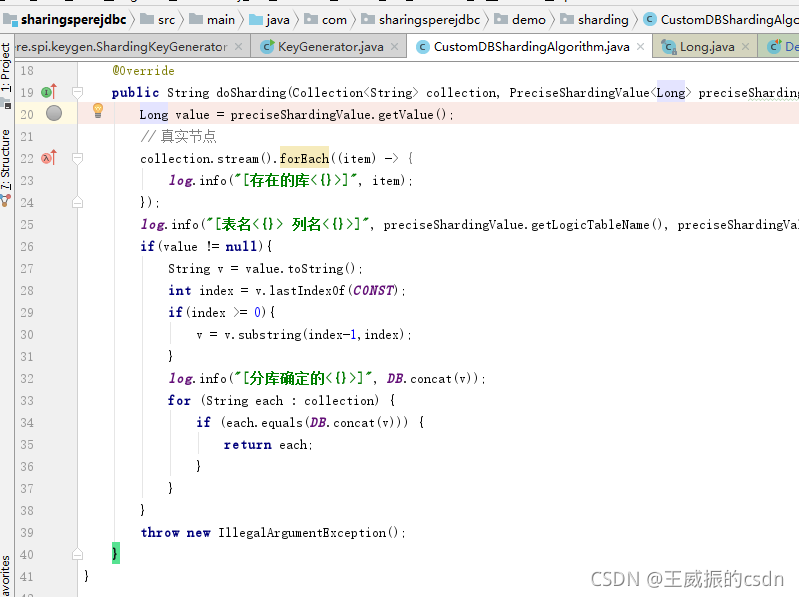
分表配置:

这项的类是自己自定义分表的算法。
precise-algorithm-class-name: com.sharingsperejdbc.demo.sharding.CustomTableShardingAlgorithm
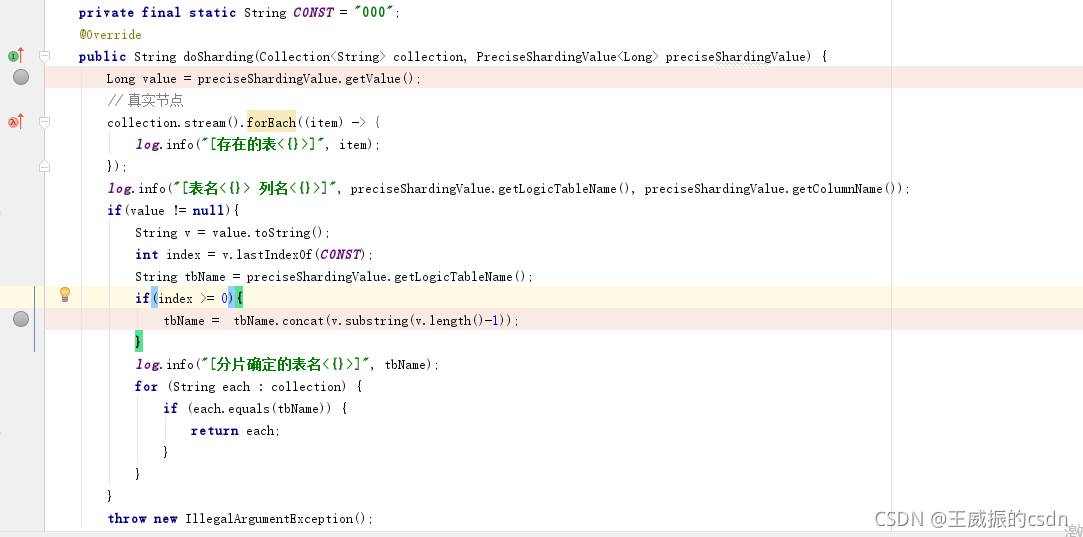
由于是根据主键id进行分库分表。所以我们也要自定义主键id.自动进行生成
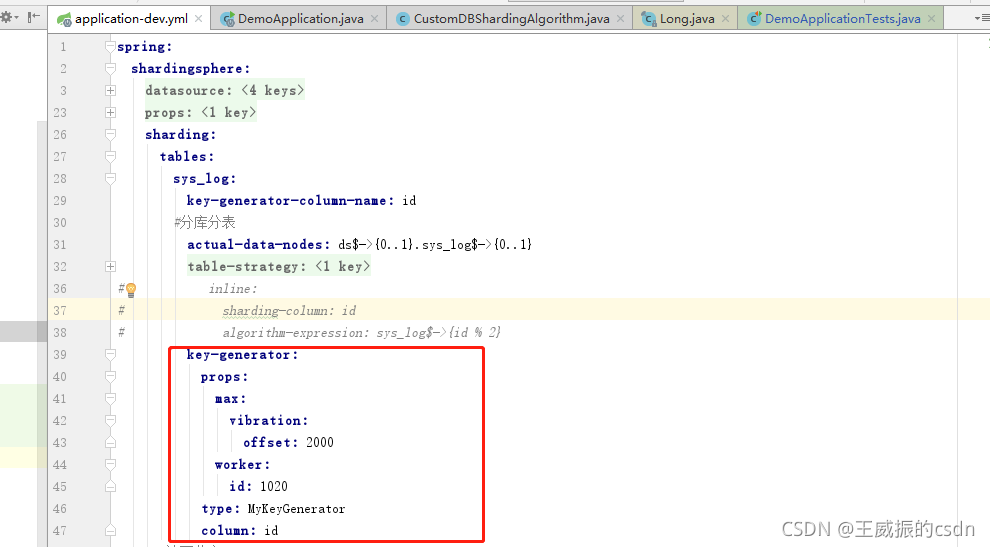
红色框框中的type的定义要和你利用spi机制配置的名字相同
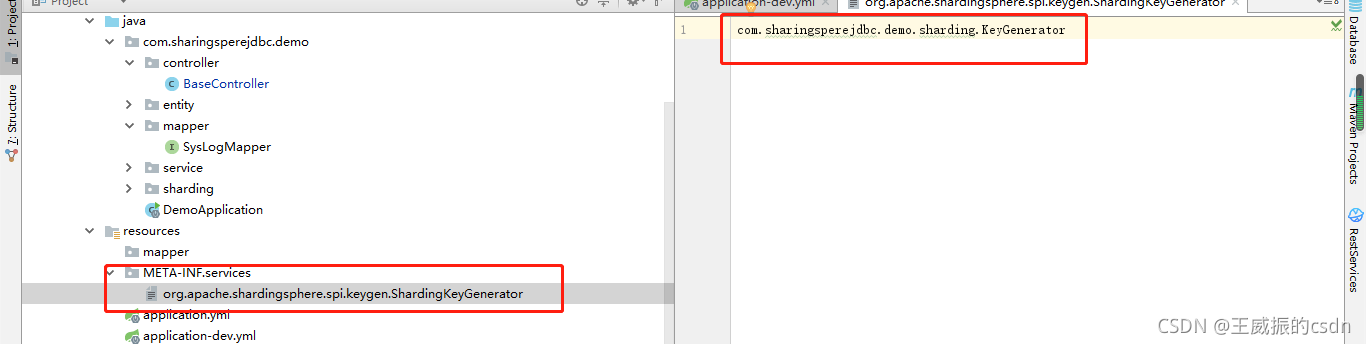
1、首先需要在resources资源文件下。建立META-INF/services目录。然后创建文件名为:
org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator的。
文件的内容:com.sharingsperejdbc.demo.sharding.KeyGenerator就是你自己定义生成主键的类
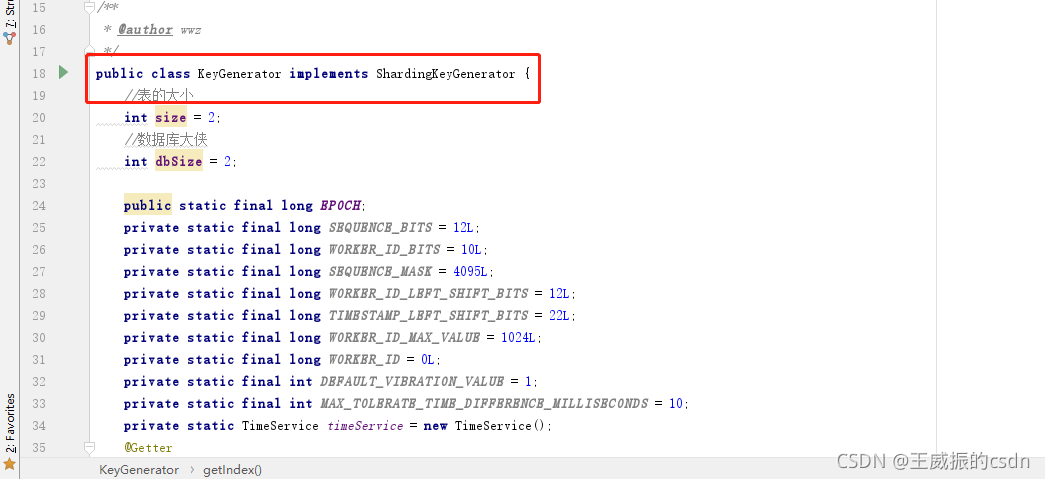
如果增加表和库了。需要对以下内容size和dbsize更改。具体是表的多少

这个type一定要和刚刚说的在yml中一样。不然找不到会报错
大致做完后,然后进行测试
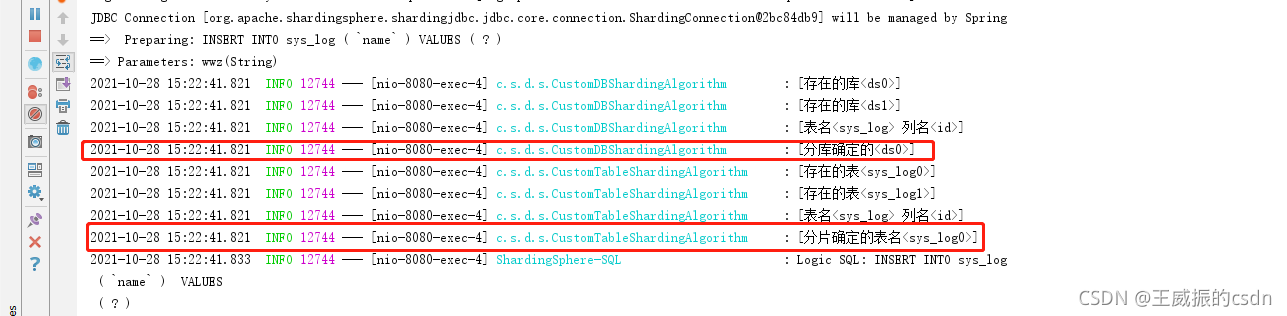
找到ds0库sys_log0表
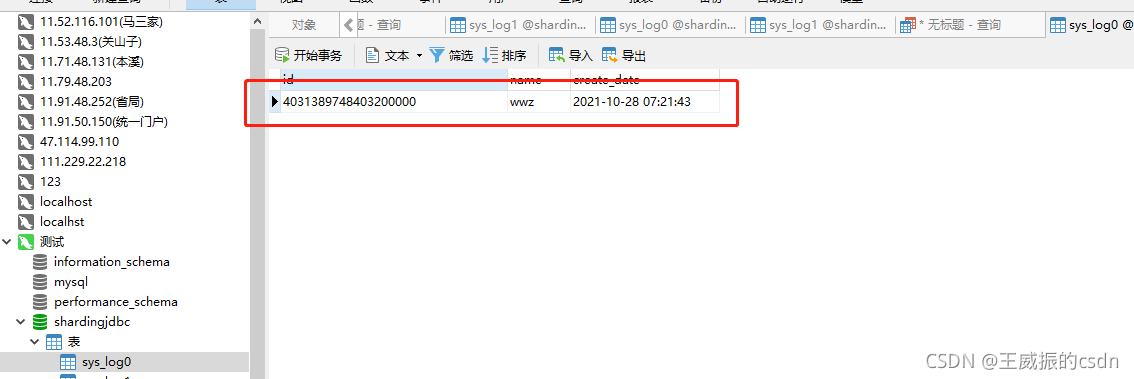
源码已开放。如果有需要的请自取https://gitee.com/eduction/shardingspherejdbc.git
我结合了mybatisplus持久层。如果你自定义的生成主键的类。一直不 进generateKey方法。那就需要把实体类中主键id去掉。让shardingspherejdbc去处理主键
分布式主键生成类:
实体类:

以上内容只是代表个人观点。如果有更好的方式。可以私聊或者文章内评论。进行探讨哦!
这篇关于利用shardingSphereJdbc实现根据主键id动态分库分表。后期就算再增加库和表。也不影响之前的业务逻辑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






