本文主要是介绍为什么 MySQL 选择 Repeatable Read 作为默认隔离级别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为什么 MySQL 选择 Repeatable Read 作为默认隔离级别?

我们知道,ANSI/ISO SQL-92 标准定义了 4 种隔离级别,从低到高依次为:
读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Reads)、序列化(Serializable)。
在 RU 级别下,可能会出现脏读、幻读、不可重复读等问题。
在 RC 级别下,解决了脏读的问题,但仍存在幻读、不可重复读的问题。
在 RR 级别下,解决了脏读和不可重复读的问题,但仍存在幻读的问题。
在 Serializable 隔离级别下,解决了脏读、幻读、不可重复读全部问题。
然而,Oracle数据库只支持 Serializable 和 Read Committed 。
需要注意的是,Oracle的默认隔离级别是RC,而MySQL的默认隔离级别是RR。
那么,你知道为什么Oracle选择RC作为默认级别,而MySQL选择RR作为默认的隔离级别吗?
Oracle 的隔离级别
前面我们提到过,Oracle只支持ANSI/ISO SQL定义的Serializable和Read Committed隔离级别。
但实际上,根据Oracle官方文档的介绍,Oracle支持三种隔离级别:Read Committed、Serializable 和 Read-Only。

官网链接:
https://docs.oracle.com/cd/E11882_01/server.112/e40540/consist.htm#CNCPT621
Read-Only 隔离级别类似于序列化隔离级别,但只读事务甚至不允许在事务中进行数据修改。
因此,在这三种隔离级别中,Serializable 和 Read-Only 显然都不适合作为默认隔离级别,Oracle 只剩下 Read Committed 这个选择。
MySQL 的隔离级别
MySQL 默认使用RR(可重复读)隔离级别的原因是基于历史和技术考虑。
MySQL 主从复制是通过 binlog 日志进行数据同步的,而早期的版本中 binlog 记录的是SQL语句的原文。
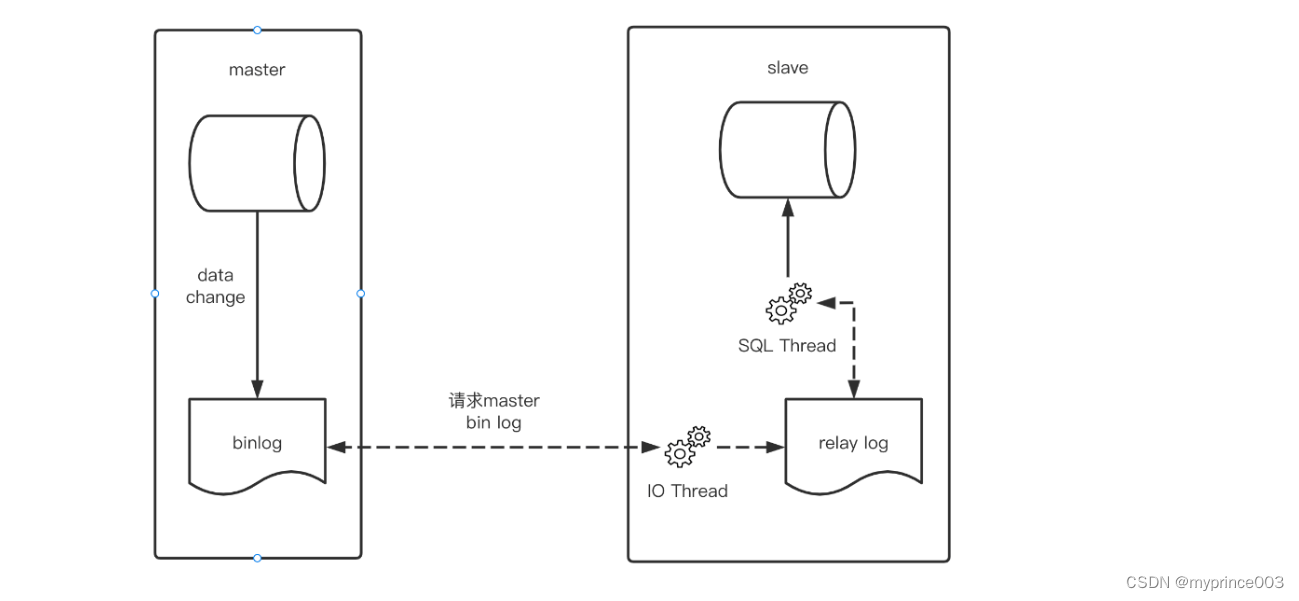
而早期的版本的 statement 格式下,记录到 binlog 里的是SQL语句原文,因此可能会出现这样一种情况:
例如这样一条SQL语句:
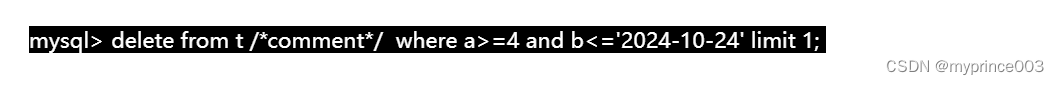
在主库执行这条 SQL 语句的时候,用的是索引 a;而在备库执行这条 SQL 语句的时候,却使用了索引 b。
【MySQL 执行优化器会进行采样预估,在不同的MySQL库里,采样计算出来的预估结果不一样,会影响优化器的判断,由于优化器会进行成本分析,可能最终选择的索引不一样。】
而又因为这条 delete 语句带了 limit,很可能会出现主备数据不一致的情况。
因此,MySQL 认为这样写是有风险的。
另外,如果使用读已提交(Read Committed)或读未提交(Read Uncommitted)这两种隔离级别,是不会添加 Gap Lock 间隙锁的。
而主从复制过程中出现的事务乱序的问题,更加容易导致备库在SQL回滚之后与主库内容不一致。
为了解决这个问题,MySQL选择了可重复读(Repeatable Read)隔离级别作为默认选项。
可重复读隔离级别,在更新数据时会增加记录锁和间隙锁,可以避免事务乱序导致的数据不一致问题。
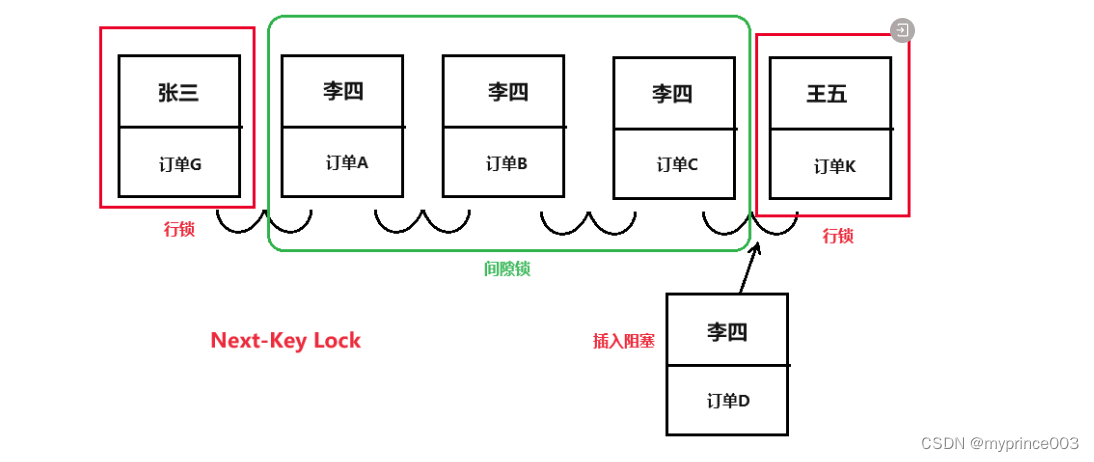
除了设置默认的隔离级别外,MySQL还禁止在使用 statement 格式的 bin log 情况下,使用 READ COMMITTED 作为事务隔离级别。
一旦用户主动修改隔离级别,尝试更新时,会报错:

所以,现在我们知道了,为什么MySQL选择RR作为默认的数据库隔离级别了
其实就是为了兼容历史上的那种 statement 格式的bin log,解决主从复制过程中的数据一致性问题。
为什么默认 RR,大厂要改成 RC?
尽管 MySQL 默认使用 RR 隔离级别,是为了解决主从复制过程中的数据一致性问题,但在实际应用中,根据具体需求和性能考虑,可以选择适合的隔离级别。
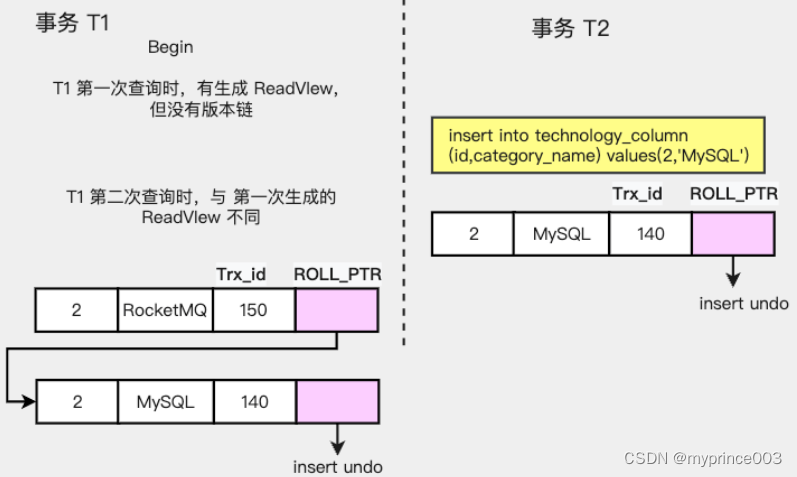
对于「读已提交」和「可重复读」两种隔离级别的事务来说,它们都是通过 Read View 来实现的。
它们的区别在于创建 Read View 的时机不同:
RC「读已提交」隔离级别是在每个 select 查询时都会生成一个新的 Read View。
这意味着,如果在事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致的情况,因为可能这期间另外一个事务修改了该记录,并提交了事务。
RR「可重复读」隔离级别是在启动事务时生成一个 Read View,然后在整个事务期间都使用这个 Read View。
这样就保证了在事务期间读到的数据都是事务启动前的记录。
一些大型互联网公司,如阿里等会根据自身需求,将数据库的隔离级别从默认的 RR 调整为 RC(读已提交)。
这是因为 RC 隔离级别可以提供更高的并发度和降低死锁发生的概率。
对于互联网公司来说最重要的是什么?
当然是,高并发!
RC 隔离级别在一致性读方面比 RR 更加灵活。
在 RC 隔离级别下,每次读取都会重新生成一个快照,总是读取行的最新版本。
这意味着 RC 隔离级别可以提供更高的并发度,允许读取其他事务已提交的数据,从而减少了锁的竞争和等待时间。
这对于互联网公司来说,特别是在高并发的场景下,可以提升系统的性能和响应速度。
其次,RC隔离级别可以降低死锁的发生概率。
在 RR 隔离级别下,由于锁的范围更广,可能会导致更多的锁竞争和死锁情况。
而在 RC 隔离级别下,由于只对已提交的数据进行读取,锁的范围更小,减少了死锁的可能性。
此外,RC隔离级别相对于RR隔离级别来说,对于一些特定的业务场景更加适用。
例如,对于一些需要实时数据的应用,RC 隔离级别可以提供更及时的数据更新,满足业务需求。
然而,RC 隔离级别仍然存在幻读和不可重复读的问题。就需要自己解决了。
而且,很多时候,不可重复读问题其实是可以忽略的。
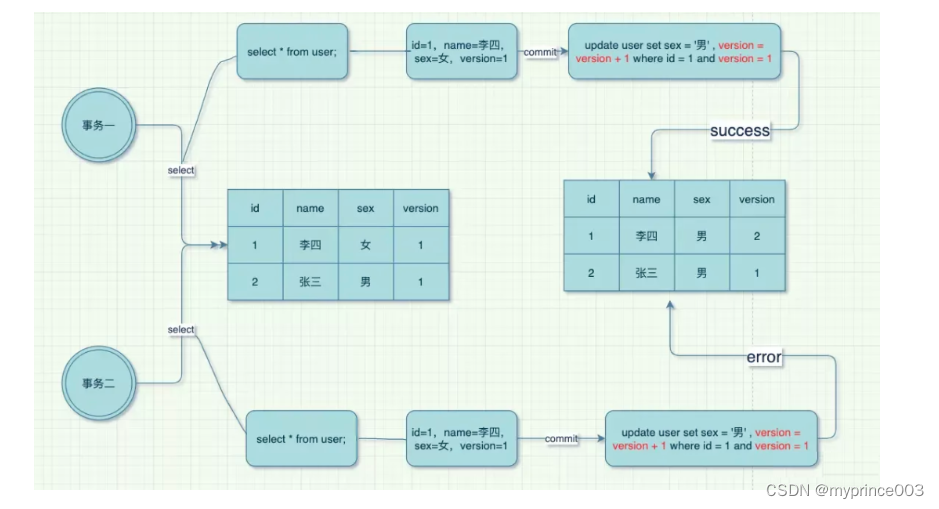
比如,读取到别的事务修改的值,其实问题不太大的,只要修改的时候的不基于错误数据就可以了。
所以,我们都会在核心表中增加乐观锁标记,更新的时候都要带上锁标记,进行乐观锁更新。
总结起来,MySQL 默认使用 RR 隔离级别是为了解决,主从复制过程中的数据一致性问题,但在实际应用中,需要根据具体需求和性能考虑,可以选择适合的隔离级别。
这篇关于为什么 MySQL 选择 Repeatable Read 作为默认隔离级别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




