本文主要是介绍pandas数据分析36——快速独热和反独热处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
做数据预处理的时候,很多文本分类变量需要变为数值型。
下面提供一些方法,就以最经典的泰但尼克号数据集作为例子。
先导包读取数据
import numpy as np
import pandas as pddata=pd.read_csv('train.csv')
data=data.drop(columns=['Name','Ticket','Cabin'],axis=1)
data['Embarked'].fillna(method='pad',axis=0,inplace=True)
data.head() 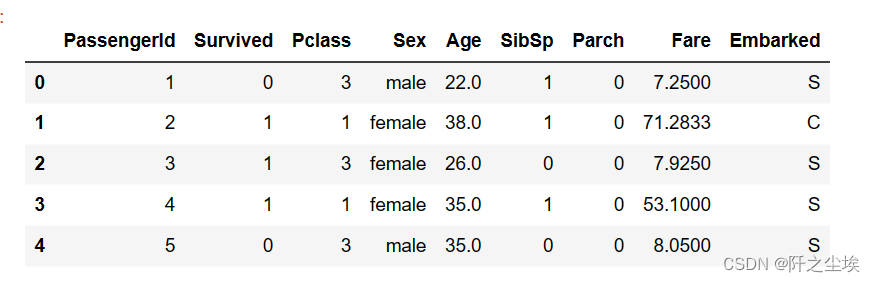
可以看到sex和embarked两列是文本,下面处理为能运算的数值型。
方法一:get_dummies
这是pandas库提供的最快的独热方法:
pd.get_dummies(data).head()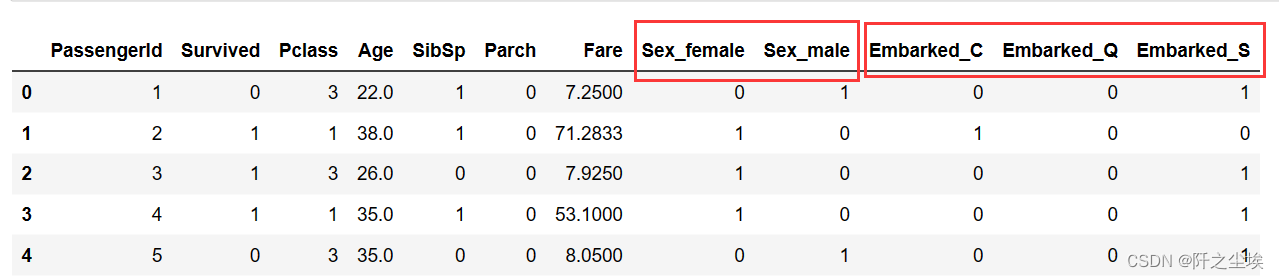
可以看到SEX两类和embarked三类都变为了虚拟变量。
方法二:字典映射
上面的方法简单,但是这样独热处理可能会让数据特征变多,列变多了。若某些特征的分类类别很多,那么将会造成维度灾难,数据变得超高维,超级稀疏。
那么可以将分类变量还是为一列,相对应的类别是=就用0,1,2...去表示。
d1={'male':0,'female':1}
d2={'S':1,'C':2,'Q':3}data['Sex']=data['Sex'].map(d1)
data['Embarked']=data['Embarked'].map(d2)data.head() 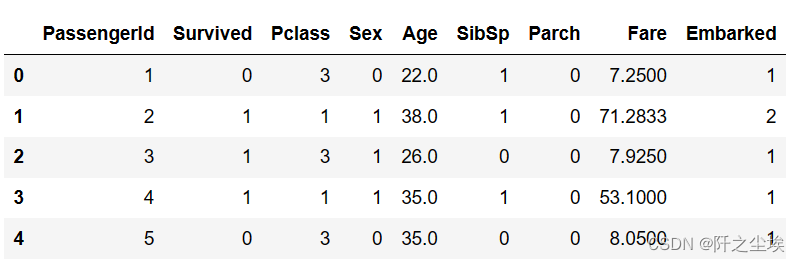
上面代码就将男性映射为0,女性为1,embarked里面的SCQ映射为1,2,3。
方法三:unique()
思路和上面的方法二差不多,方法二的缺点是,一个变量里面的类别太多了,我们手写字典很麻烦...所以就用unique生成变量的类别
#映射
lis=list(data['Embarked'].unique())
d=dict([(key,value) for (value,key) in enumerate(lis)])
print(d)
然后可以像上面方法二一样映射就行。
有时候我们预测出来了数值,但是想映射回文本变量怎么办 ,可以反转一下字典,然后再映射回去:
#反转
d2=dict([ (value,key) for (key,value) in d.items()])
print(d2)方法四:groupby
分组聚合的函数也是可以直接将文本变为数值的:
#还可以
data.groupby('Embarked').ngroup()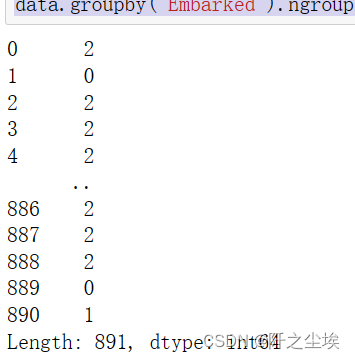
方法五:因子化
上面的方法或多或少都有点不全面或者不简洁,下面这个是最简洁的
#最简单的
codes,uniques=pd.factorize(data['Embarked'])
uniques
codes
可以看到因子化factorize方法,直接就生成了所有类别变量的唯一取值列表,然后把对应的数值映射好了。
当然预测出来的数值型数据也可以像方法二映射回去:
d=dict([(key,value) for (value,key) in enumerate(uniques)])
d2=dict([ (value,key) for (key,value) in d.items()])
pd.Series(codes).map(d2)
反独热
有时候需要进行反独热处理,就是将多个列的虚拟变量变为一个变量,例如下面这个例子:
data = pd.read_excel('副本data.xlsx').iloc[:,6:] # 读取数据
data=data[data['是否了解购买']==2]
data.head()
例如前几列变量,其实只表示一个变量:‘了解渠道’,有淘宝,新媒体,杂志,门店等等,这是标准的独热了的情况,取值只有0和1,现在自定义一个函数,处理这种反独热情况:
def rev_onehot(df,onehot_columns,new_column,drop=False): #要处理的数据框,反独热的列,新的总名称,是否删除df[new_column]=list(df[onehot_columns].to_numpy().argmax(axis=1))df[new_column]=data[new_column].map(dict([(value,key)for (value,key)in enumerate(onehot_columns)]))if drop:df=df.drop(columns=onehot_columns)return df上面的函数有四个参数 :要处理的数据框,反独热的列,新的总名称,是否删除。
使用像下面这样:
data=rev_onehot(df=data,onehot_columns=['淘宝','新媒体','电视杂志','线下门店','熟人推荐','其他'],new_column='了解渠道',drop=True)
data=rev_onehot(df=data,onehot_columns=['鲜天麻','干天麻','天麻粉','天麻切片','天麻药剂'],new_column='了解天麻制品种类',drop=True)
data=rev_onehot(df=data,onehot_columns=['口感','价格','包装','种类'],new_column='购买考虑因素',drop=True)
data=rev_onehot(df=data,onehot_columns=['价格偏高','不了解食用方法','不了解功效','购买渠道','质量参差不齐'],new_column='未购买原因',drop=True)
data=rev_onehot(df=data,onehot_columns=['100以下','101-200','201-300','300以上'],new_column='接受价格区间',drop=True)查看处理完的:
data.head()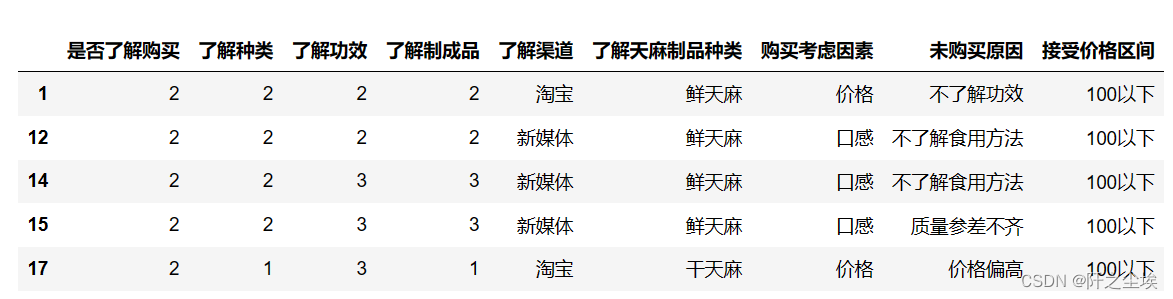
可以看到变量变少了,后面几个变量都是反独热回去了的。
这篇关于pandas数据分析36——快速独热和反独热处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







