本文主要是介绍Python 遇见茶文化,鉴茶指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


Start
阅读本文及源码,可以和小编一起学到 xpath 表达式爬取数据,多进程爬取,pandas 基本操作,pyecharts 可视化,stylecloud 词云,文本余弦相似度相似度,KMeans,关键词提取算法:TextRank,TF-IDF,LDA 主题模型。
源码获取在文末
前言
最近上班买了点茶叶,搞了一个 1L 的杯子放桌上,每天泡茶想着喝那么久的茶,还没怎么了解过茶,于是从数据的角度来探索一下茶。
小编找到一个和茶有关网站:
https://chaping.chayu.com/?bid=1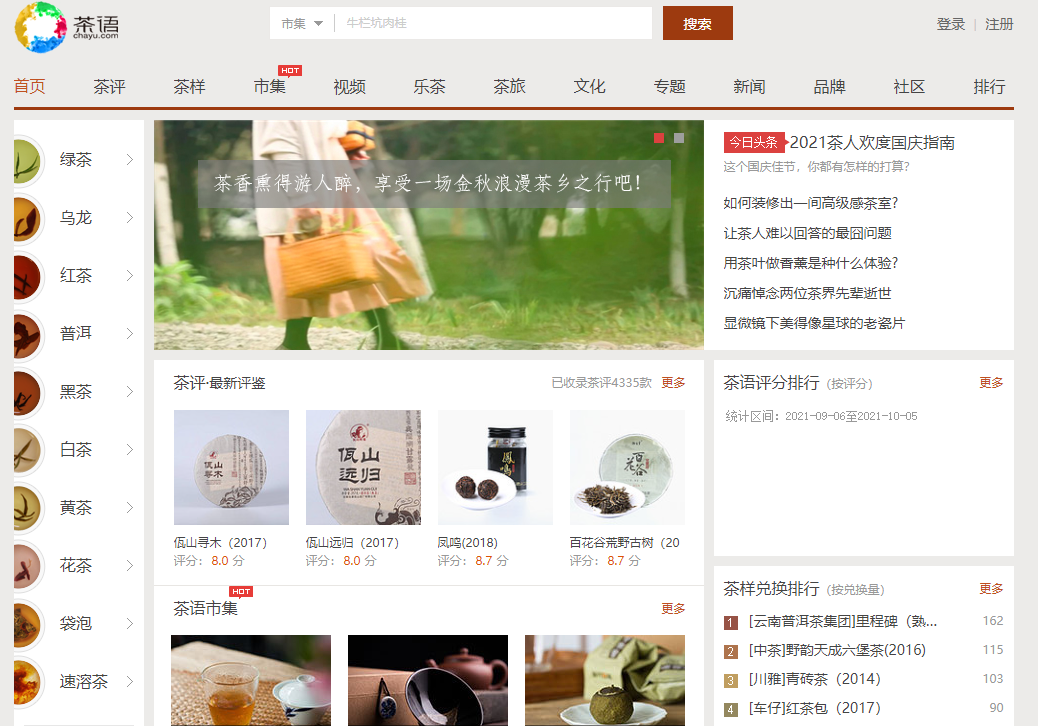
数据获取
从首页进入茶评,可以看到所有茶的基本信息,结果有多页,获取所有的基本信息包括标题,评分,品牌,产地,茶类,详细链接,id:
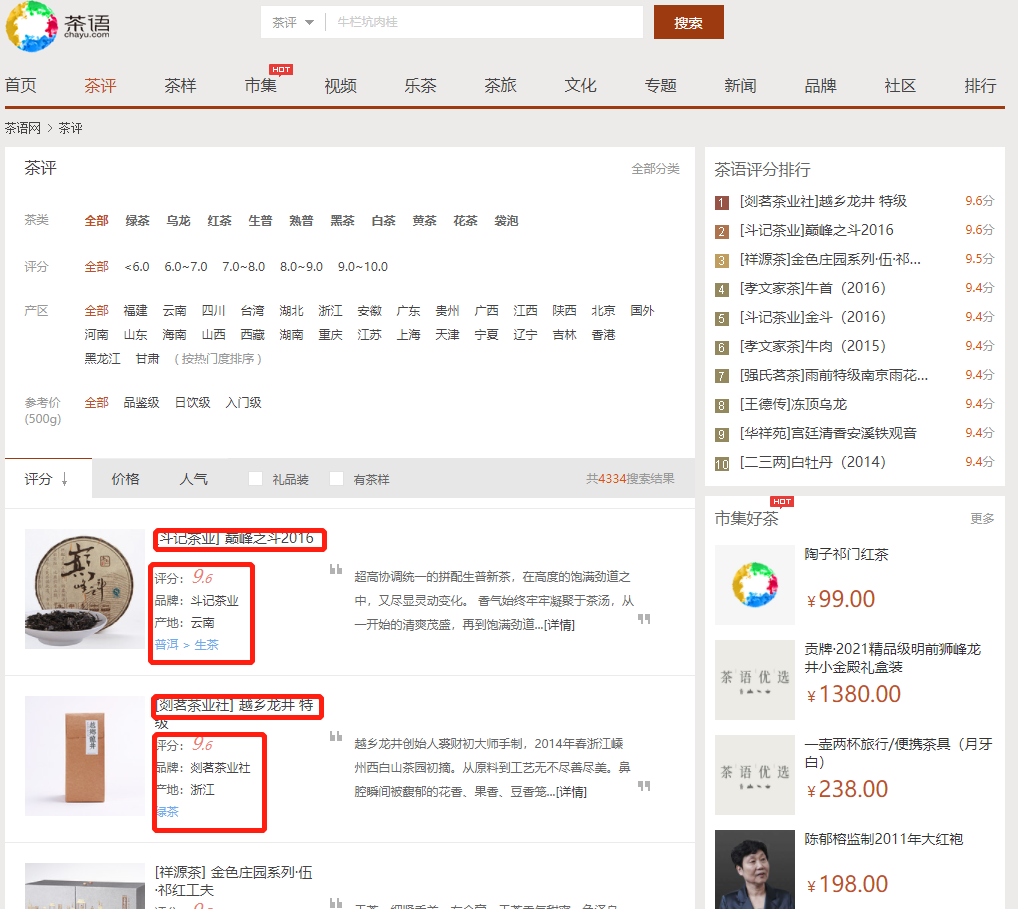

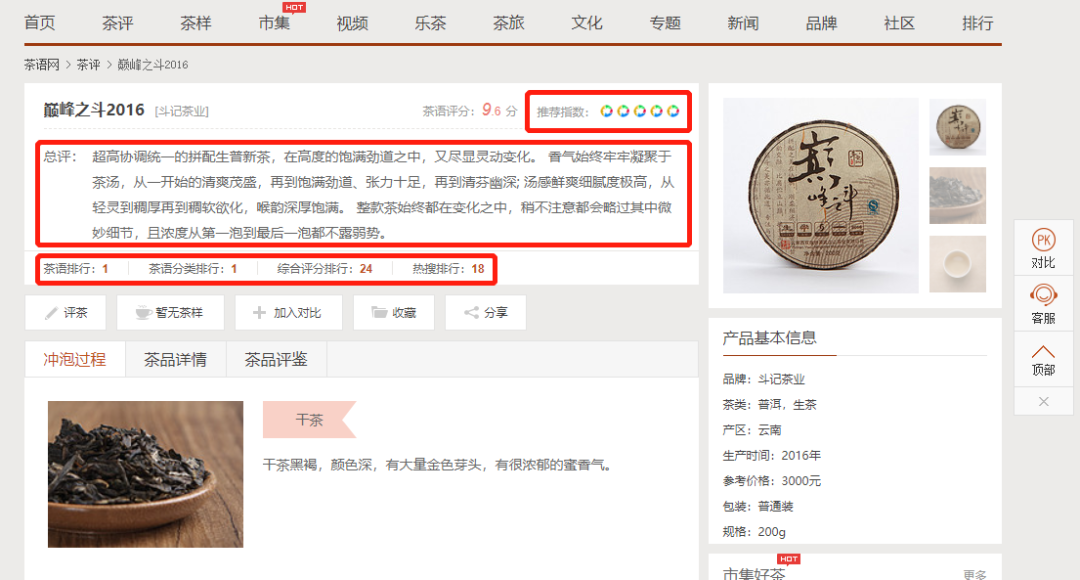
再根据获得的链接,下钻爬取每一种茶的推荐指数,总评,所有排行:
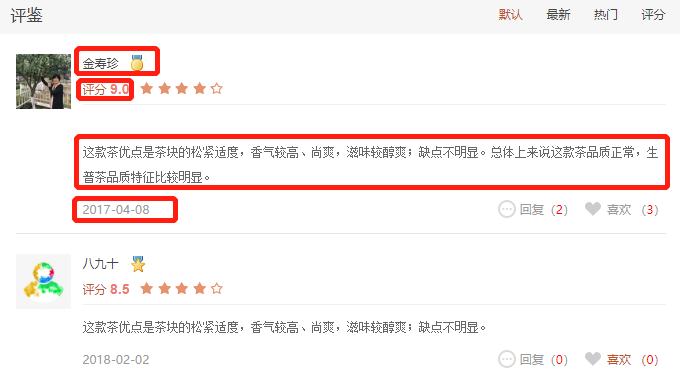
及爬取对应的评论,有多页就爬取多页,包含字段评论人,评论人等级,评分,评论,评论时间:

最后保存为 tea.csv,comment.csv 两个 csv:
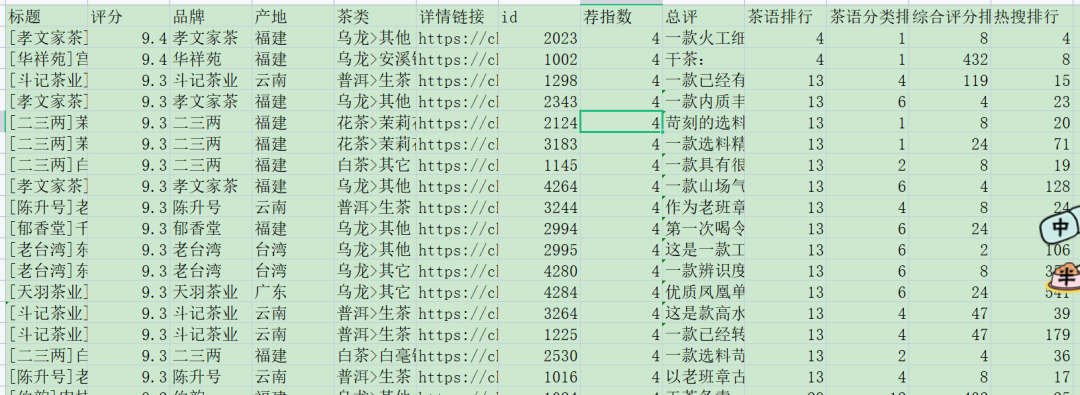
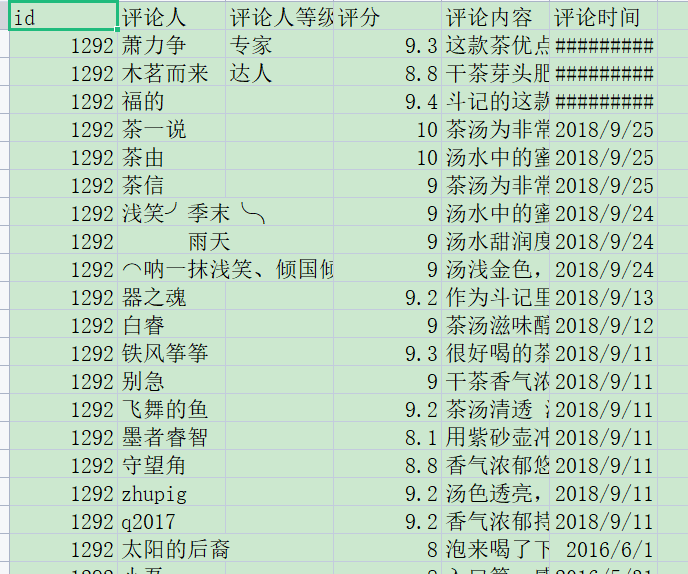
整个爬虫流程就这样,使用了 xpath 提取,多进程爬取,逻辑不算复杂,详细实现逻辑可查看源码。
数据分析
总共获得 3w 条数据,获得数据后就可以开始进行探索了。
先对标题进行查看,标题是由品牌及名称构成,处理为只保留名称部分,绘制词云。
红茶,白杜丹,铁观音,绿茶,毛尖等一些听到过的茶名称还是比较多的:

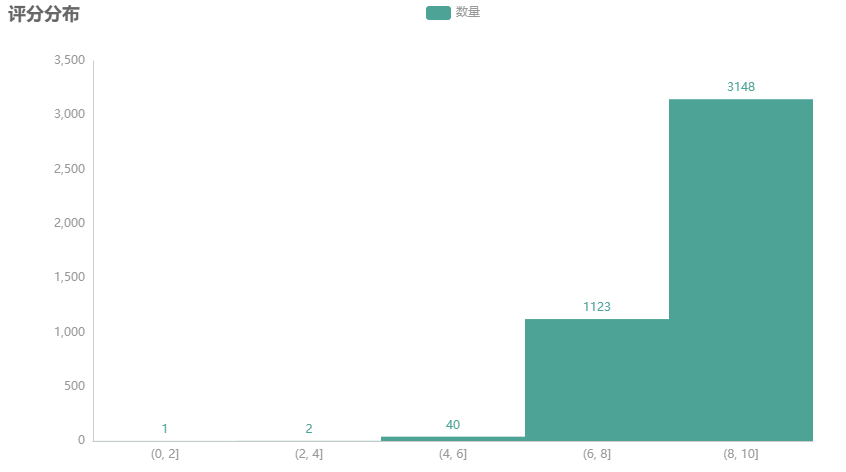
茶评分取值为 0-10,对评分每两分进行切分后绘制直方图。
从结果上看,评分都挺高的,只有个别评分是低于 4 分的,小编选出数据看了看,总评价对这些低分的茶评价不是特别友好:
现在基本上每种茶都有专门的品牌在售卖,对品牌进行统计,绘制词语。
发现斗记茶业,中茶,大益,天福茗茶等较为突出,这些品牌就算不了解茶,但多多少少也听到过在大街上看到过:

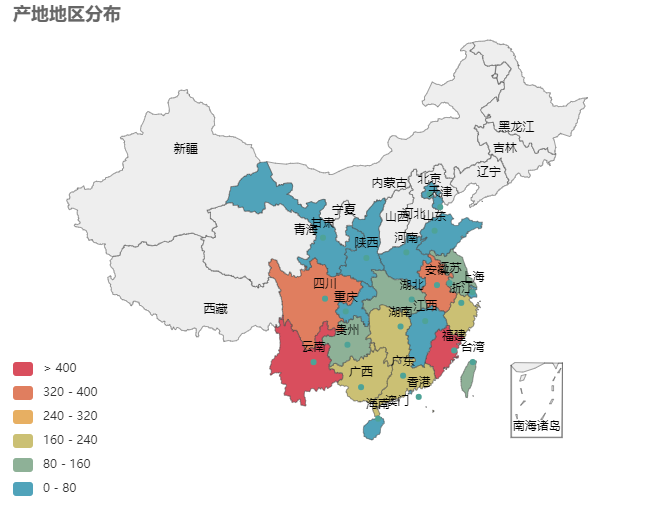
每种茶都有它独特的产地,对产地绘制热力地图。
发现产地来自云南的是最多的,多达上千种,小编查了查,云南茶叶最重要的原产地,云南是茶叶最为古老的故乡。
其次是福建,有着一千多年的茶文化历史,是最中国产茶的重要产地:
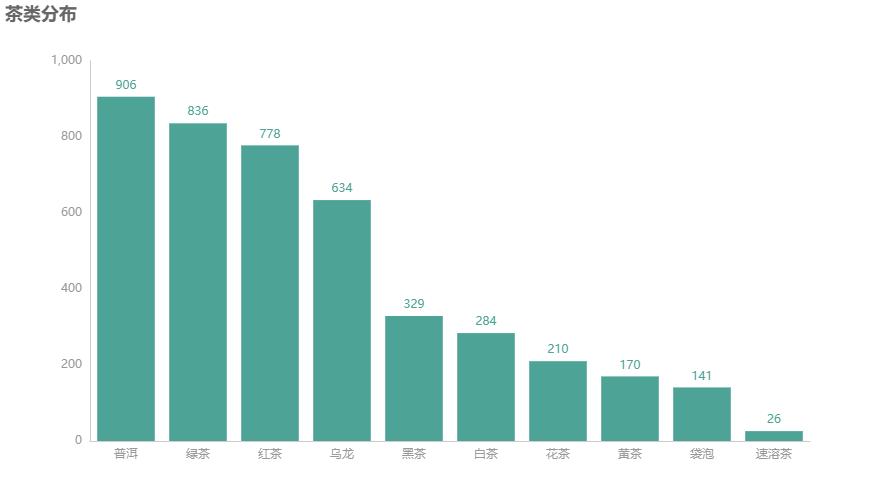
目前茶类可分为普洱,绿茶,红茶,乌龙,黑茶,白茶,花茶,黄茶,袋泡,速溶茶十大类,每个大类别有细分很多小类,对每个大类进行统计绘制柱状图。
发现普洱茶是类别最多的,其次是绿茶,红茶,看到这里小编想到自己都很少喝普洱茶:
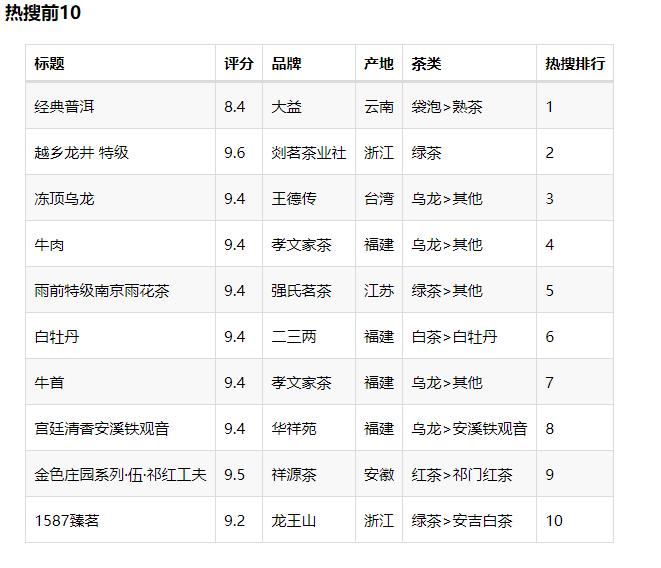
热搜能从侧面反映一种茶受不受欢迎,小编选出热搜排名前 10 的茶,拉出明细。
发现排名第一的是经典普洱,普洱也是种类最多的茶,以后可以特地买一点试试:
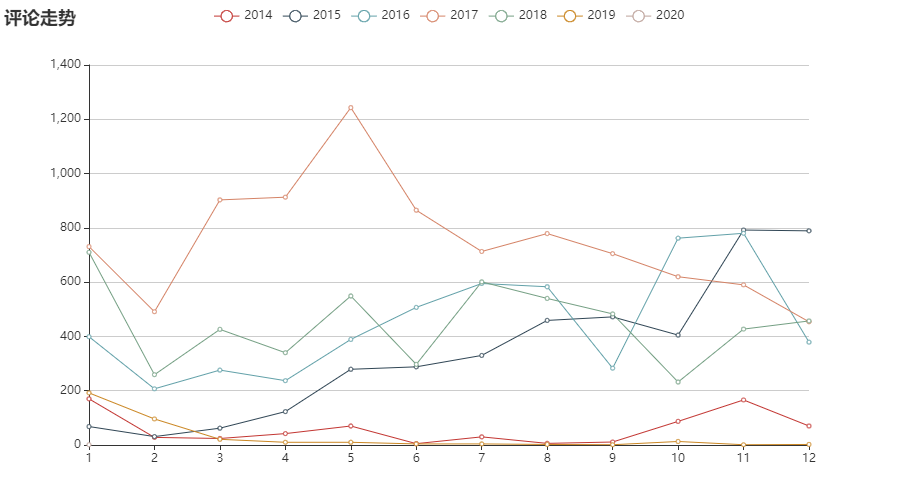
对评论时间以时间年月为维度,同比每一年每一月的评论走势图。
发现评论用户 14-17 年活跃程度是一直攀升,之后下跌了:
到这里,探索性分析就完成了,主要用到了 ,pandas,stylecloud,jieba,pyecharts 这些技术,详细实现过程可参考源码。
关键词提取
在获得的数据中,有总评字段,即对每一种茶的评语,有每一个用户评论的字段,利用这两个字段来实现文本关键词提取。
对于总评,我们想把总评相似的茶分到一起,可以使用 KMeans 聚类算法,但总评是文本数据。
需要先提取每条总评中的关键词,使用了 TextRank 算法提取关键词,原理是基于句子进行分词,对每个词进行权重打分,获得分数高的作为关键词。
对关键词向量化,再计算余弦相似度,最后使用聚类算法,分为了两种种类。
种类一主要是从品尝方向进行评价的,香气,滋味,入口,顺滑等。
种类二主要是从外表方向进行评价的,外形,条索,色泽,原料等:

对评论先使用了 TF-IDF 算法进行关键词的提取,是有 TF,IDF 两部分算法组成。
TF,计算每一个词在所有文本中出现的频率。
IDF,计算每一个词在所有评论中,在多少条评论中出现的次数,映射一个分值。
最后 TF*IDF 选出分值前 10 的关键词:
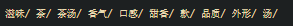
第二种方法是利用主题模型 LDA 进行关键词提取,需要先确定主题数,再提取关键词,这里就选取 1 个主题,及前 10 关键词:
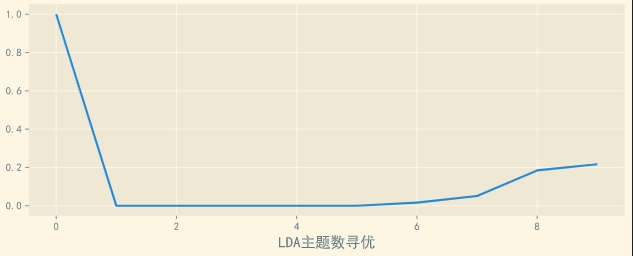
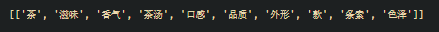
对于 LDA 主题模型的使用,可以参考小编之前的文章:
《炎炎夏日,漂流去哪漂?评论情感分析告诉你》
可以看到两种方式提取出来的关键词大部分相似,可以根据场景进行选择。
源码获取
在公众号回复关键字“tea”即可获取
END
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “赞” 的都变得更好看呐~
关注关注小编呗~小编给你分享爬虫,数据分析,可视化的内容噢~
扫一扫下方二维码即可关注我噢~
-END-

这篇关于Python 遇见茶文化,鉴茶指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





