本文主要是介绍python爬虫十四:scrapy crawlspider的介绍及使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、scrapy crawlspider的介绍
他有着自动提取规则,内部封装的只要我们爬取的数据有规律并且在网页源码中,就可以实现他的自动抓取,我们不用管具体交给它做,下面会有案例展示
之前的代码中,我们有很大一部分时间在寻找下一页的URL地址或者内容的URL地址上面,这个过程能更简单一些吗?
思路:
1.从response中提取所有的li标签对应的URL地址
2.自动的构造自己resquests请求,发送给引擎
目标:通过爬虫了解crawlspider的使用
生成crawlspider的命令:scrapy genspider -t crawl 爬虫名字 域名
2、Rule规则类
class scrapy.spiders.Rule(link_extractor, # 一个LinkExtractor对象,用于定义爬取规则。callback = None, # 满足这个规则的url,应该要执行哪个回调函数。cb_kwargs = None, follow = None, # 指定根据该规则从response中提取的链接是否需要跟进。process_links = None, # 从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。process_request = None
)
3、LinkExtractors链接提取器的介绍
class scrapy.linkextractors.LinkExtractor(allow = (), # 允许的url。所有满足这个正则表达式的url都会被提取。deny = (), # 禁止的url。所有满足这个正则表达式的url都不会被提取。allow_domains = (), # 允许的域名。只有在这个里面指定的域名的url才会被提取。deny_domains = (), # 禁止的域名。所有在这个里面指定的域名的url都不会被提取。deny_extensions = None,restrict_xpaths = (), # 严格的xpath。和allow共同过滤链接。tags = ('a','area'),attrs = ('href'),canonicalize = True,unique = True,process_value = None
)
5、案例演示 爬取小程序社区(实操crawlspider让他自动抓取感受他的强大)
附上代码,有问题留言我解答,这是Rule内部封装的提取规则,你想看他怎么实现的就看他的源码,我只会用知道他很神奇,我也不知道他的原理,大家别问我原理,其余的欢迎提问
目标网址:点击进入目标网址
第一步:创建项目scrapy startproject 项目名
我以heihei为例(先在setting里面写一下:LOG_LEVEL='WARNING')
第二步:进入项目cd 项目名
cd heihei
第三步:创建crawlspiderscrapy genspider -t crawl 爬虫名 爬虫区域
我以scrapy genspider -t crawl haha wxapp-union.com
为例爬取
第四步:在爬虫里面搞事情
将下面的代码写入haha就可实现
第五步:终端输入scrapy crawl haha回车就可以看到效果
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
# 需求:爬取微信小程序社区的 标题 作者 日期 翻页
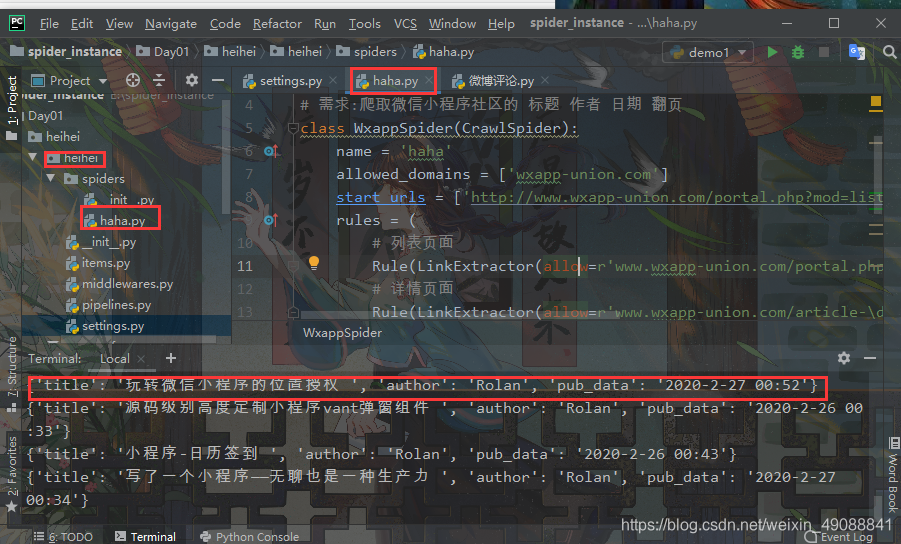
class WxappSpider(CrawlSpider):name = 'haha'allowed_domains = ['wxapp-union.com']start_urls = ['http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1']rules = (# 列表页面Rule(LinkExtractor(allow=r'www.wxapp-union.com/portal.php\?mod=list&catid=2&page=\d+'), follow=True),# 详情页面Rule(LinkExtractor(allow=r'www.wxapp-union.com/article-\d+-1.html'), callback='parse_item'),)def parse_item(self, response):item = {}item['title'] = response.xpath("//h1[@class='ph']/text()").extract_first()item['author'] = response.xpath("//p[@class='authors']/a/text()").extract_first()item['pub_data'] = response.xpath("//p[@class='authors']/span/text()").extract_first()print(item)
效果图:ctrl+c终止进程,想要保存数据在pipeline里面操作,我的前几篇文章有讲,想保存的话自己翻着看看
这篇关于python爬虫十四:scrapy crawlspider的介绍及使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




