本文主要是介绍【Python爬虫+可视化】解析小破站热门视频,看看播放量为啥会这么高!评论、弹幕主要围绕什么展开,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章

如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码
环境使用
-
Python 3.8
-
Pycharm
模块使用
-
import requests
-
import csv
-
import datetime
-
import hashlib
-
import time
一. 数据来源分析
-
明确需求
明确采集网站以及数据
网址:
https://space.bilibili.com/517327498/video?tid=0&pn=2&keyword=&order=pubdate数据: 视频基本信息: 标题 播放量 评论 弹幕 上传时间 …
-
抓包分析
打开开发者工具: F12 / 右键点击检查选择network
点击网页下一页 --> XHR 第一条数据包就是我们需要的内容
数据包:
https://api.bilibili.com/x/space/wbi/arc/search?mid=517327498&ps=30&tid=0&pn=3&keyword=&order=pubdate&platform=web&web_location=1550101&order_avoided=true&w_rid=c9a9f931486961175b1e8138d695680e&wts=1690027894
二. 代码实现步骤 <固定四个大步骤>
-
发送请求, 模拟浏览器对于url地址发送请求
-
获取数据, 获取服务器返回响应数据
-
解析数据, 提取我们需要的数据内容
-
保存数据, 把信息数据保存表格文件
获取视频详情数据
1.发送请求, 模拟浏览器对于url地址发送请求
'''
python资料获取看这里噢!! 小编 V:python10010 好友验证备注:6
即可获取文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
# 模拟浏览器
headers = {# 用户代理 表示浏览器基本身份信息'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}string = f'keyword=&mid=517327498&order=pubdate&order_avoided=true&platform=web&pn=1&ps=30&tid=0&web_location=1550101&wts={int(time.time())}6eff17696695c344b67618ac7b114f92'
# 实例化对象
md5_hash = hashlib.md5()
md5_hash.update(string.encode('utf-8'))
# 请求链接
url = 'https://api.bilibili.com/x/space/wbi/arc/search'
# 请求参数
data = {'mid': '517327498','ps': '30','tid': '0','pn': '1','keyword': '','order': 'pubdate','platform': 'web','web_location': '1550101','order_avoided': 'true','w_rid': md5_hash.hexdigest(),'wts': int(time.time()),
}
# 发送请求 <Response [200]> 响应对象 表示请求成功
response = requests.get(url=url, params=data, headers=headers)
2.获取数据, 获取服务器返回响应数据
-
response.json() 获取响应json数据
字典数据类型
-
response.text 获取响应文本数据
网页源代码 字符串数据
-
response.content 获取响应二进制数据数据
获取图片/视频/音频/特定格式文件
print(response.json())
3.解析数据, 提取我们需要的数据内容
字典数据: 键值对取值
根据冒号左边的内容[键], 提取冒号右边的内容[值]
for index in response.json()['data']['list']['vlist']:# 时间戳 时间节点 --> 上传视频时间点date = index['created']dt = datetime.datetime.fromtimestamp(date)dt_time = dt.strftime('%Y-%m-%d')dit = {'标题': index['title'],'描述': index['description'],'BV号': index['bvid'],'播放量': index['play'],'弹幕': index['video_review'],'评论': index['comment'],'时长': index['length'],'上传时间': dt_time,}print(dit)
4.保存数据, 把信息数据保存表格文件
'''
python资料获取看这里噢!! 小编 V:python10010 好友验证备注:6
即可获取文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
f = open('信息.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题','描述','BV号','播放量','弹幕','评论','时长','上传时间',
])
csv_writer.writeheader()
数据可视化
导入数据
import pandas as pddf = pd.read_csv('B站视频信息.csv')
df.head()

2020~2023年每月视频总播放平均数
'''
python资料获取看这里噢!! 小编 V:python10010 好友验证备注:6
即可获取文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
from pyecharts import options as opts
from pyecharts.charts import Barc = (Bar().add_xaxis(monthly_avg_plays_2021['月份'].tolist()).add_yaxis("", monthly_avg_plays_2021['播放量'].tolist()).set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),title_opts=opts.TitleOpts(title="罗翔视频可视化", subtitle="2020~2023年每月视频总播放平均数"),)
)
c.render_notebook()

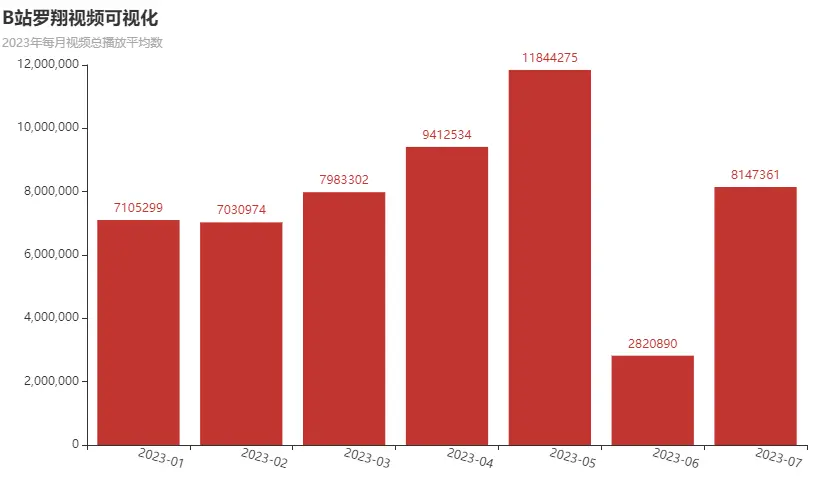
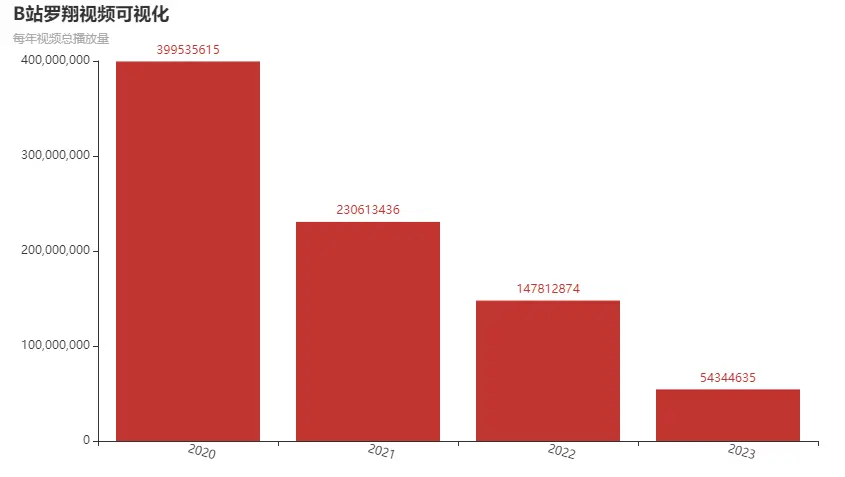
每年视频总播放量
df['年份'] = pd.to_datetime(df['上传时间']).dt.strftime('%Y')
yearly_total_plays_all = df.groupby('年份')['播放量'].sum().reset_index()
yearly_total_plays_allc = (Bar().add_xaxis(yearly_total_plays_all['年份'].tolist()).add_yaxis("", yearly_total_plays_all['播放量'].tolist()).set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),title_opts=opts.TitleOpts(title="B站罗翔视频可视化", subtitle="每年视频总播放量"),)
)
c.render_notebook()
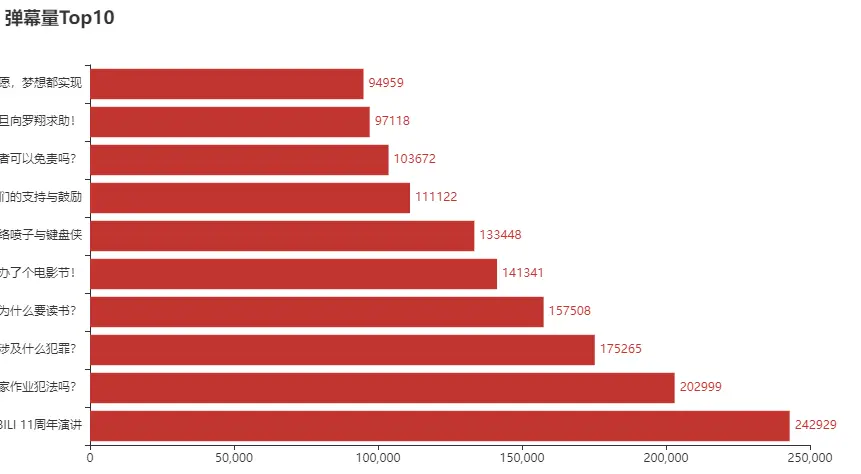
弹幕量Top10
'''
python资料获取看这里噢!! 小编 V:python10010 好友验证备注:6
即可获取文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
top10 = df[['标题', '弹幕']].sort_values('弹幕', ascending=False)[:10]
names = list(top10['标题'])
counts = list(top10['弹幕'])
c = (Bar().add_xaxis(names).add_yaxis("", counts).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position="right")).set_global_opts(title_opts=opts.TitleOpts(title="弹幕量Top10"))
# .render("bar_reversal_axis.html")
)
c.render_notebook()
评论量Top10
top10 = df[['标题', '评论']].sort_values('评论', ascending=False)[:10]
names = list(top10['标题'])
counts = list(top10['评论'])
c = (Bar().add_xaxis(names).add_yaxis("", counts).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position="right")).set_global_opts(title_opts=opts.TitleOpts(title="评论量Top10"))
# .render("bar_reversal_axis.html")
)
c.render_notebook()

尾语
好了,今天的分享就差不多到这里了!
对下一篇大家想看什么,可在评论区留言哦!看到我会更新哒(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!

最后,宣传一下呀~👇👇👇 更多源码、资料、素材、解答、交流 皆点击下方名片获取呀👇👇👇
这篇关于【Python爬虫+可视化】解析小破站热门视频,看看播放量为啥会这么高!评论、弹幕主要围绕什么展开的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






