本文主要是介绍在MDP环境下训练强化学习智能体,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.创建MDP环境
2.创建Q-learning智能体
3. 训练Q-learning智能体
4.验证Q-learning结果
本文示例展示了如何训练Q-learning智能体来解决一般的马尔可夫决策过程(MDP)环境。有关这些智能体的更多信息,请参阅Q-Learning智能体。
MDP环境如下图:

其中:
- 每一个圆圈代表一个状态。
- 每个状态可以决定上升或下降。
- 智能体从状态1开始。
- 智能体收到的奖励等于图中每个转换的值。
- 训练目标是获得最大的累积奖励。
1.创建MDP环境
创建具有8个状态和2个动作(上和下)的MDP环境。
MDP = createMDP(8,["up";"down"]);为了对上图中的转换建模,需要修改MDP的状态转移矩阵和奖励矩阵。默认情况下,这些矩阵包含零。
为MDP指定状态转移矩阵和奖励矩阵。例如,在以下命令中:
- 前两行指定通过采取动作1(“向上”)从状态1转移到状态2并且奖励+3。
- 接下来的两行指定了通过采取动作2(“向下”)从状态1转移到状态3,并且奖励+1。
MDP.T(1,2,1) = 1;
MDP.R(1,2,1) = 3;
MDP.T(1,3,2) = 1;
MDP.R(1,3,2) = 1;类似地,为图中剩余的规则指定状态转换和奖励。
% State 2 transition and reward
MDP.T(2,4,1) = 1;
MDP.R(2,4,1) = 2;
MDP.T(2,5,2) = 1;
MDP.R(2,5,2) = 1;
% State 3 transition and reward
MDP.T(3,5,1) = 1;
MDP.R(3,5,1) = 2;
MDP.T(3,6,2) = 1;
MDP.R(3,6,2) = 4;
% State 4 transition and reward
MDP.T(4,7,1) = 1;
MDP.R(4,7,1) = 3;
MDP.T(4,8,2) = 1;
MDP.R(4,8,2) = 2;
% State 5 transition and reward
MDP.T(5,7,1) = 1;
MDP.R(5,7,1) = 1;
MDP.T(5,8,2) = 1;
MDP.R(5,8,2) = 9;
% State 6 transition and reward
MDP.T(6,7,1) = 1;
MDP.R(6,7,1) = 5;
MDP.T(6,8,2) = 1;
MDP.R(6,8,2) = 1;
% State 7 transition and reward
MDP.T(7,7,1) = 1;
MDP.R(7,7,1) = 0;
MDP.T(7,7,2) = 1;
MDP.R(7,7,2) = 0;
% State 8 transition and reward
MDP.T(8,8,1) = 1;
MDP.R(8,8,1) = 0;
MDP.T(8,8,2) = 1;
MDP.R(8,8,2) = 0;指定状态“s7”和"s8"作为终止状态。
MDP.TerminalStates = ["s7";"s8"];
为这个过程模型创建强化学习MDP环境:
env = rlMDPEnv(MDP);要指定智能体的初始状态始终为状态1,请指定一个返回初始智能体状态的重置函数。这个函数在每一次训练的开始被调用。创建一个匿名函数句柄,将初始状态设置为1。
env.ResetFcn = @() 1;为了再现结果固定随机生成器种子:
rng(0)2.创建Q-learning智能体
为了创建Q-learning智能体,首先使用MDP环境中的观察值和动作创建一个Q表,并设置学习率为1。
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);
qTable = rlTable(obsInfo, actInfo);
qFunction = rlQValueFunction(qTable, obsInfo, actInfo);
qOptions = rlOptimizerOptions(LearnRate=1);接下来,使用这个表创建一个Q-learning智能体,配置贪心探索算法。
agentOpts = rlQAgentOptions;
agentOpts.DiscountFactor = 1;
agentOpts.EpsilonGreedyExploration.Epsilon = 0.9;
agentOpts.EpsilonGreedyExploration.EpsilonDecay = 0.01;
agentOpts.CriticOptimizerOptions = qOptions;
qAgent = rlQAgent(qFunction,agentOpts);3. 训练Q-learning智能体
为了训练智能体,首先指定训练选项,对于这个例子,使用如下选项:
- 训练最多500次,每次最多持续50个时间步。
- 当智能体在连续30次中获得的平均累计奖励大于10时,停止训练。
trainOpts = rlTrainingOptions;
trainOpts.MaxStepsPerEpisode = 50;
trainOpts.MaxEpisodes = 500;
trainOpts.StopTrainingCriteria = "AverageReward";
trainOpts.StopTrainingValue = 13;
trainOpts.ScoreAveragingWindowLength = 30;使用Train函数训练智能体。这可能需要几分钟才能完成。为了节省运行此示例时的时间,通过将doTraining设置为false来加载预训练的智能体。要训练自己的智能体,就将doTraining设置为true。
doTraining = false;if doTraining% Train the agent.trainingStats = train(qAgent,env,trainOpts); %#ok<UNRCH>
else% Load pretrained agent for the example.load("genericMDPQAgent.mat","qAgent");
end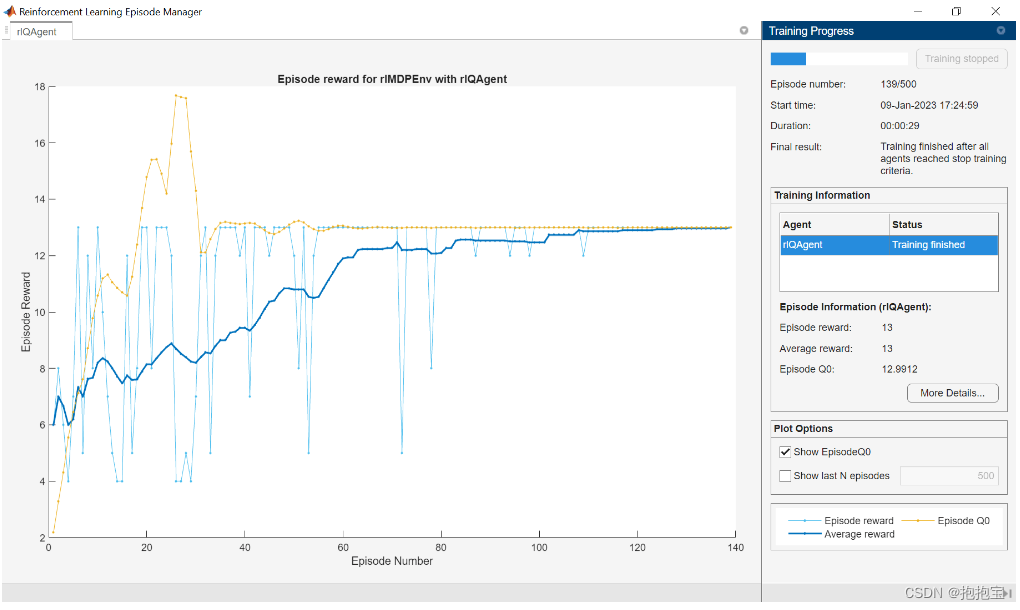
4.验证Q-learning结果
为了验证训练结果,使用sim函数在训练环境中模拟智能体。agent成功找到最优路径,累计奖励为13。
Data = sim(qAgent,env);
cumulativeReward = sum(Data.Reward)由于折扣因子设置为1,因此训练智能体的Q表中的值与环境的未折现收益相匹配。
QTable = getLearnableParameters(getCritic(qAgent));
QTable{1}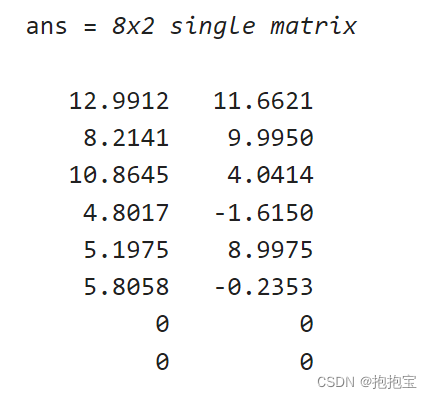
TrueTableValues = [13,12;5,10;11,9;3,2;1,9;5,1;0,0;0,0]
这篇关于在MDP环境下训练强化学习智能体的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





