本文主要是介绍深入解读 Flink 1.17,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:本文整理自阿里云技术专家,Apache Flink PMC Member & Committer、Flink CDC Maintainer 徐榜江(雪尽) 在深入解读 Flink 1.17 的分享。内容主要分为四个部分:
Flink 1.17 Overview
Flink 1.17 Overall Story
Flink 1.17 Key Features
Summary
一、Flink 1.17 Overview

Flink 1.17 版本完成了 7 个 FLIP,累计贡献者 170+,解决 600+Issue 以及 1100+Commits,整体来看是一个较大的版本。
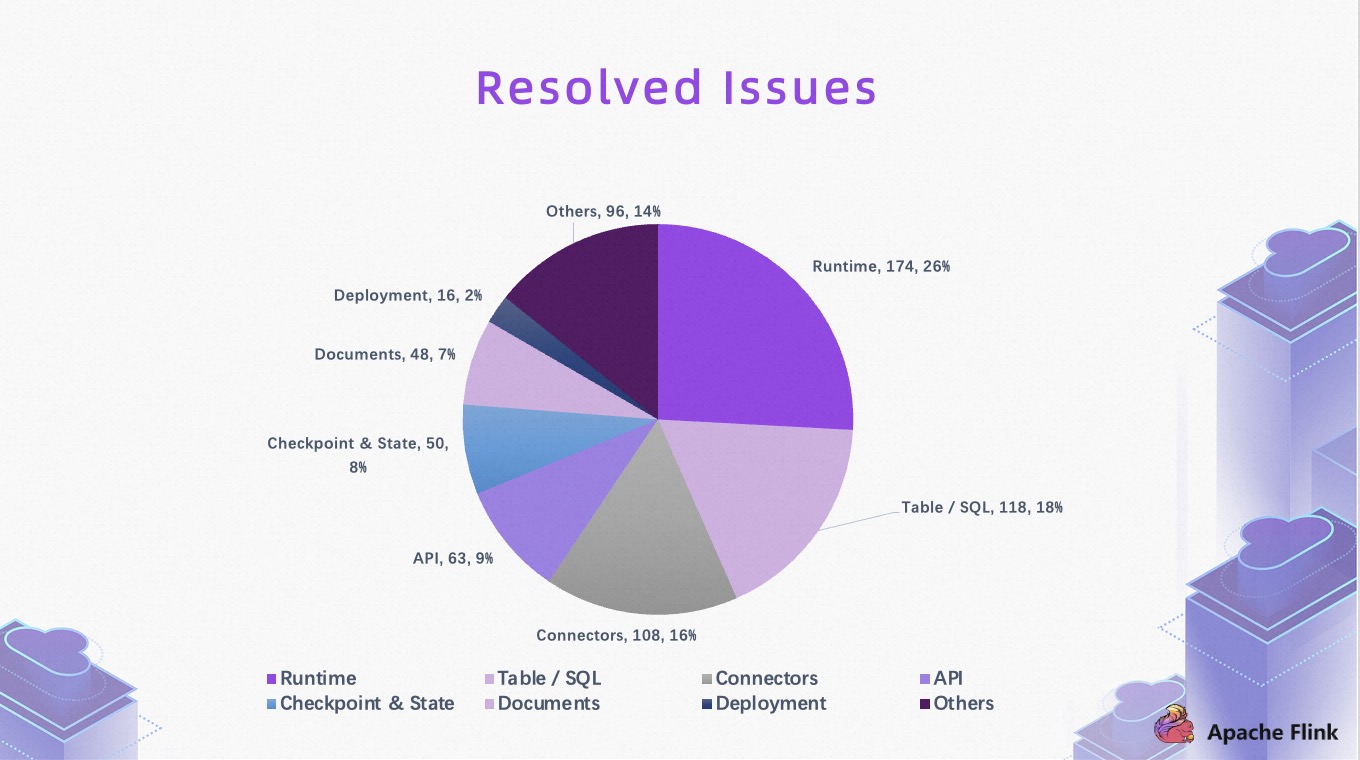
从 Issue 分布来看,1.17 版本主要在 Runtime 层面以及 Table 层面做了较多改进,其中 Runtime 层面约170+Issue,Table 层面约 120个。另外,在 Checkpoint & State、API、Connector 层面也做了诸多提升与改进。

1.17 版本完成的 FLIP 如上图所示,分别为:
-
FLIP-256:扩展了 Rest API 支持提交作业时指定参数,与 Flink CLI 基本对齐。
-
FLIP-265:将 Scala 的 API 支持标记为 deprecated, Flink 里的 API 有 Scala 与 Java 两套, 随着社区的不断发展与演进,Scala API 出现了各种问题,比如Scala版本升级困难,在 Flink 1.15 里,从 Scala 2.12.7 升级到 2.12.15 必须做出兼容性破坏的改造;另一方面,Java API 比 Scala API 在社区演进更快一些,前者的 Feature 会更多; 再加之社区比较缺少熟悉 Scala 技术栈的 Contributor,因此社区决定将 Scala 的 API 慢慢移除,更专注于 Java API。
-
FLIP-266:对 TM 的网络层配置做了很多简化,新增了多个核心特性,提高了 Runtime 层面网络的开箱即用,用户做更少的配置即可获得较好的作业优化效果。
-
FLIP-280:在 SQL 层面引入了 PLAN ADVICE 功能,帮助用户检查 PLAN 的正确性以及对 SQL 做优化,比如聚合是否应该拆分、非确定性的列导致不正确性的问题等,并提示用户改写和优化 SQL。
-
FLIP-281:Sink 对于 Batch 作业支持了预测执行。预测执行主要分为三个 FLIP 来逐步实现,第一个 FLIP 支持作业链路中除 Source、Sink 之外的算子,第二个 FLIP 支持了 Source 算子, FLIP-281是最后一个 FLIP,支持了 Sink 算子。Sink 算子比较特殊,在 Flink 作业的拓扑里,它会 flush 数据到外部系统,需要写入数据,多个 Task 协同外部系统的执行对于数据的一致性会带来较大挑战。而 FLIP-281 支持了 Sink 的预测执行之后,Batch 作业的全链路都支持了预测执行。
-
FLIP-282:引入了 Delete 和 Update API。在 Flink 从 Streaming Processing 到 Streaming Warehouse 的演进中,需要为 Streaming Warehouse 定制一些 API,比如行级数据的 Delete 与 Update API,方便与其他Connector 的对接。
-
FLIP-283:将自适应的 Batch 调度器作为默认调度器。之前的 1.16 版本已经推出 Adaptive Batch Scheduler,但它不是默认调度器,而 1.17 版本将设置为默认调度器。
二、Flink 1.17 Overall Story
Flink 1.17 版本向 Streaming Warehouse 迈进了一大步。
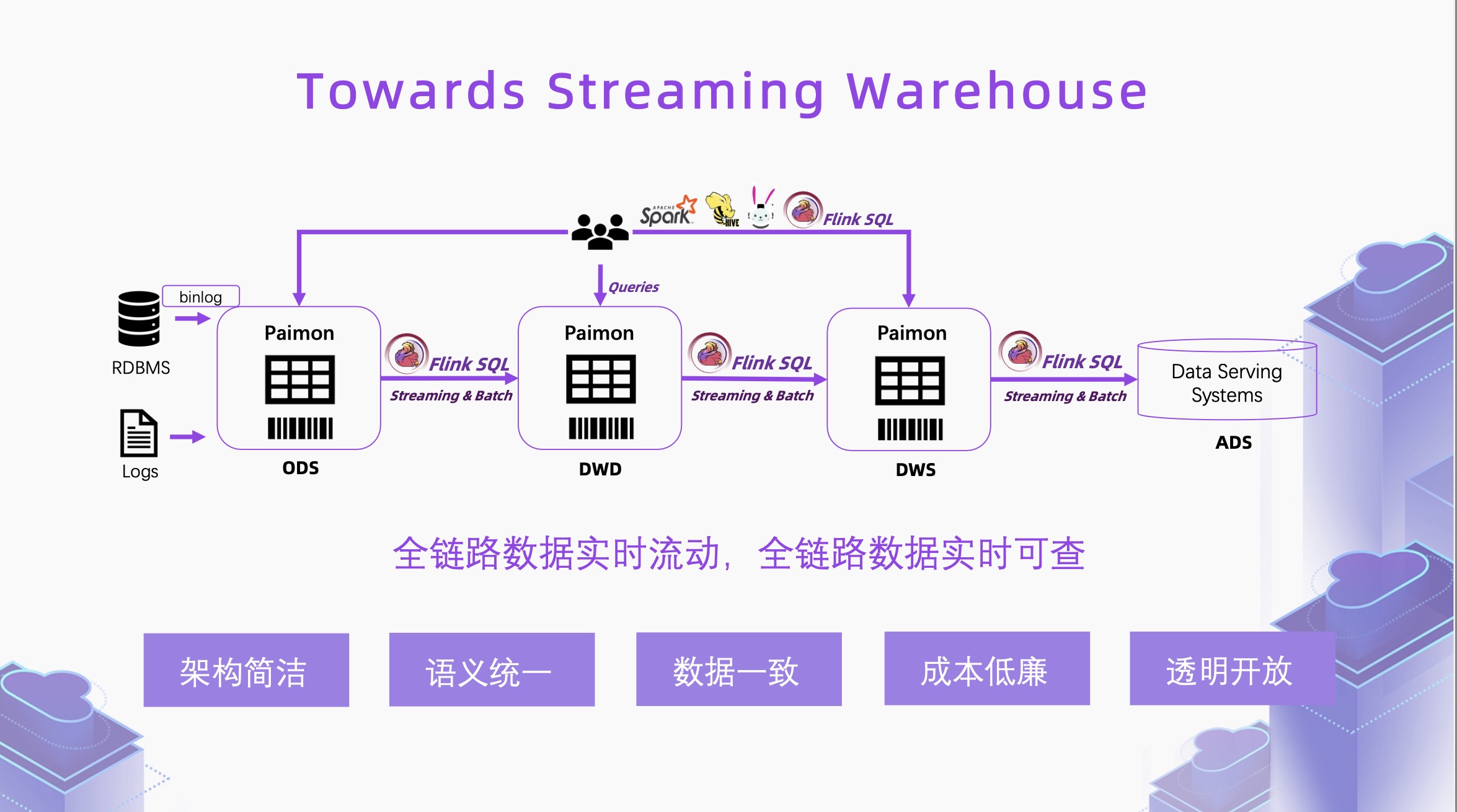
如图所示,Flink 在从 Streaming Processing 到 Streaming Warehouse 迈进后,我们不再需要批处理的链路,也不用拆分流处理的链路,批处理和流处理链路是统一的、流批一体的。
数据在数仓的每一层之间都通过 Flink 进行实时的流动,并且每一层数据实时可查,可以通过其他引擎查询湖存储里的数据,湖存储可以是 Paimon(从 Flink Table Store 子项目孵化出的 Apache 项目),也可以是 Hudi 等,提供了真正的流式服务。
该架构的优势在于,不再需要两套系统,架构更简洁。同时,将离线与实时整合在一起,只需一份存储,成本更低,通过 Flink SQL 流批一体的引擎做加工,语义和数据均可保持一致。垂直方向上,每一层数据实时可查,架构透明开放。
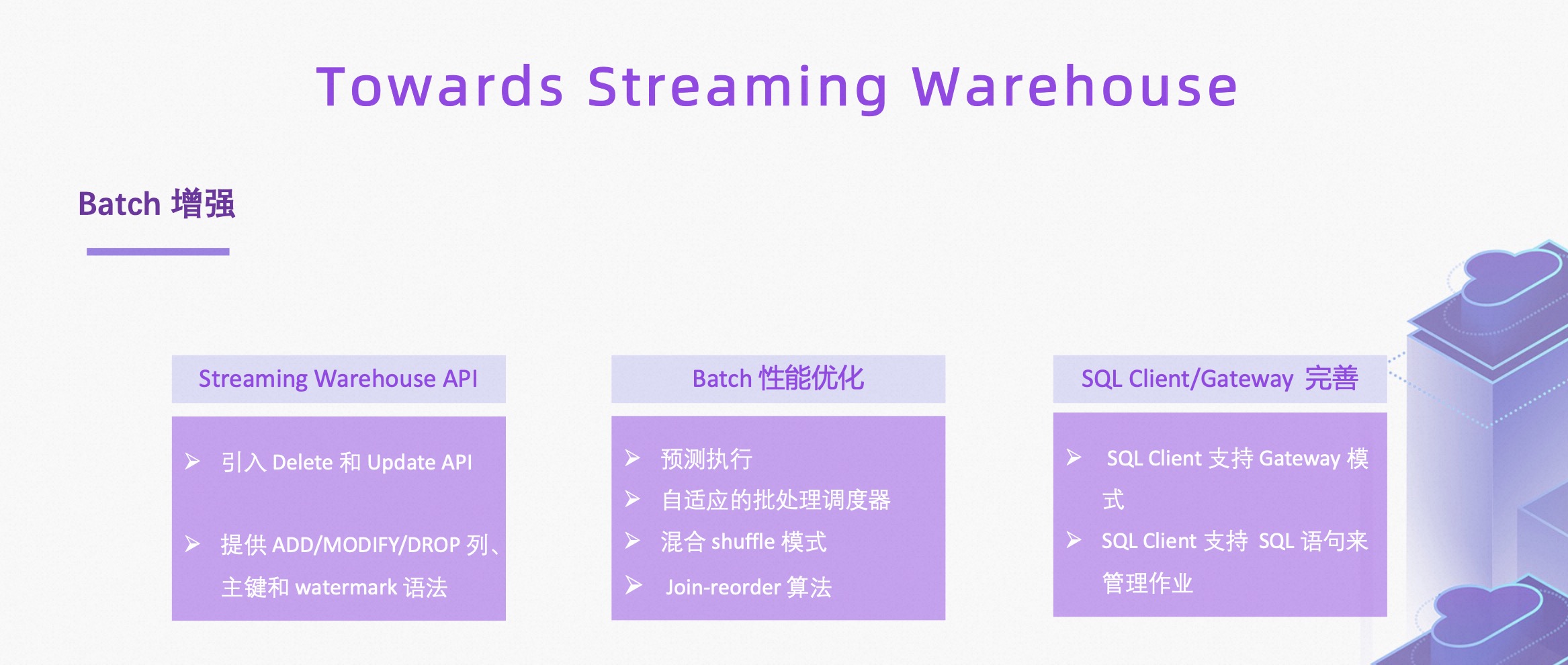
为了更好地向流式数仓迈进,我们在 Batch 方面做了很多增强。
-
Streaming Warehouse:引入了 Delete 与 Update API,同时提供了 add/modify/drop 列,主键以及Watermark 语法。
-
Batch 性能优化块:预测执行、自适应 Batch 调度器、混合 Shuffle 模式以及 Join-reorder 算法。
-
提交工具:SQL Client 支持了 Gateway 模式,支持通过 SQL 语句管理 Flink 作业。

Streaming 性能也在不断演进。
-
Streaming SQL 语义增强:修复了非确定性操作导致的 PLAN 错误,引入了 PLAN ADVICE 提供 SQL 的优化建议以及错误的 warning,完善了 Watermark 对齐。
-
Checkpoint 改进:提出通用的增量 Checkpoint,主要实现了速度以及稳定性的提升。同时,Unaligned Checkpoint 实现了生产可用。
-
Statebackend 升级:将 FRocksDB 的版本做了升级,带来了更多 Feature,支持 Apple 的芯片组,比如 Mac M1。
三、Flink 1.17 Key Features
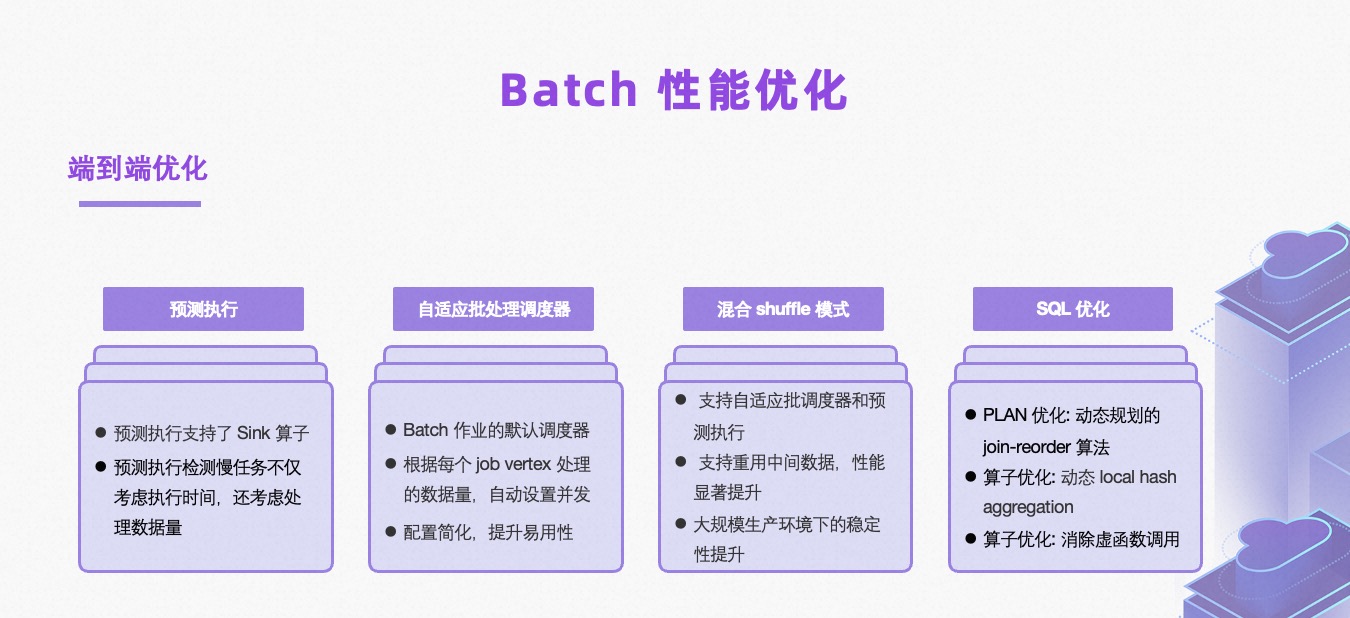
我们对 Batch 做了端到端的性能优化,涵盖了 SQL 的 PLAN、Runtime 算子、调度全流程。
-
Runtime 的预测执行:支持了 Sink 算子,同时改进了慢任务的检测,之前只考虑慢任务的执行时间,现在还考虑数据量。
-
自适应 Batch 调度器:将自适应调度器作为默认调度器。调度器可以根据每个 Job 和节点处理的数据量自动设置并发,更智能。另外,做了配置简化,提升整体的易用性。
-
混合 Shuffle:混合 Shuffle 是一种结合了 blocking 与 pipeline 优点提出的新的 Shuffle 模式。在 1.17 版本里支持了自定义 Batch 调度器、预测执行,同时支持重用中间数据,提升性能。另外,混合 Shuffle 模式在大规模生产环境下的稳定性得到进一步提升。
-
SQL 层面的优化:Planner 引入了动态规划的的 Join-reorder 算法,之前的 Join-reorder 算法优化出的 PLAN 树相当于是一棵偏左树,并发处理往往只有两路;而动态规划的 Join-reorder 算会使得 PLAN 树更平衡,并发也更高。在算子层面做了动态 local hash 聚合优化,通过 code 键实现,比如 count 聚合时,数据比较稀疏处可以直接跳过聚合,提升性能。同时,在算子上消除了部分虚函数的调用,使得性能进一步提升。

经过上述各层的优化,Flink 1.17 整体相比 Flink 1.16 的 TPC-DS 性能提升 26%。
Flink 1.16 耗时接近 7000 秒,1.17 降为 5000+秒。上图可见,部分 Query 的性能提升十分明显,比如 Q58 从 150+秒降低至几十秒。
另外,我们对 Checkpoint 和 State 也做了很多改进。
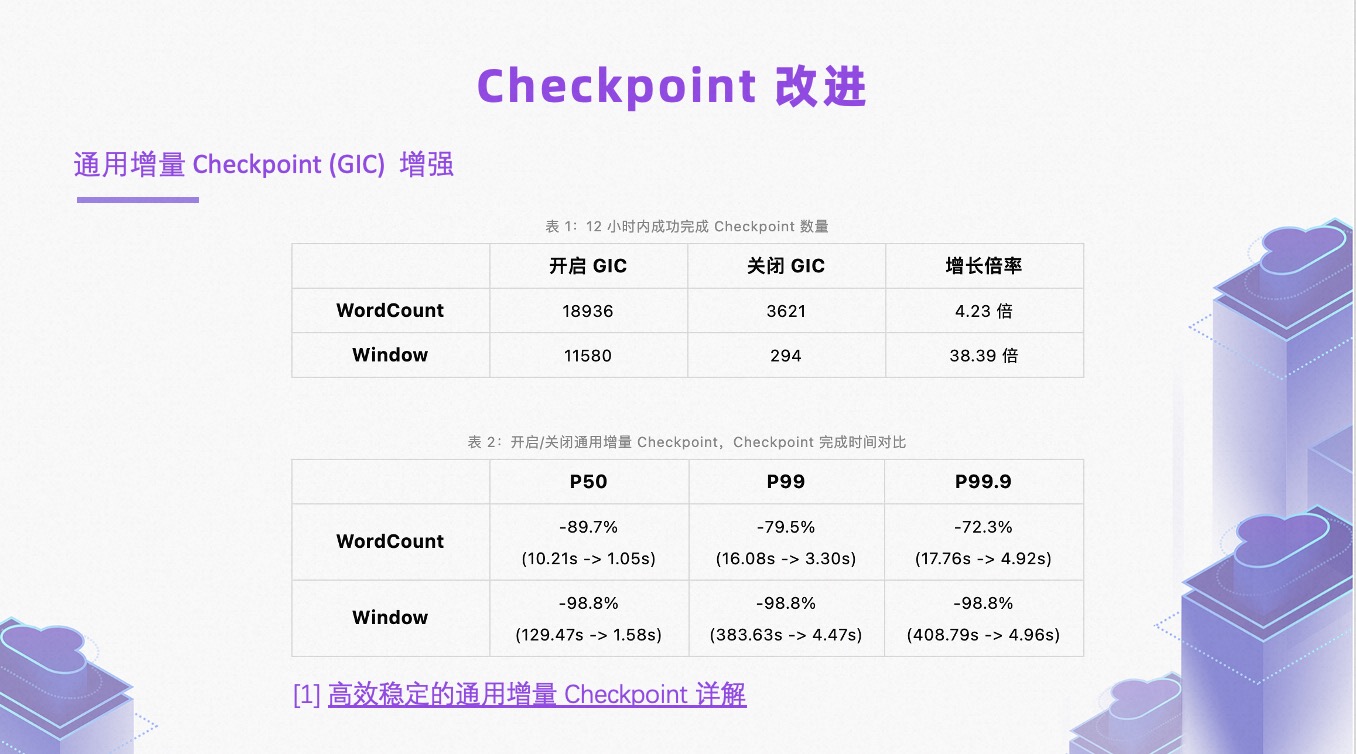
比如通用增量 Checkpoint(GIC)速度方面有了很大提升,在开启通用增量 Checkpoint 后,WordCount 与 Window 作业性能提升了 4.23 倍与 38.39 倍,WordCount 完成时间有接近 90%的减少,Window 作业的 Checkpoint 耗时从 130s 降至 1.58s。
对于流作业而言,开启通用增量 Checkpoint 后,速度和稳定性都得到了质的提升。
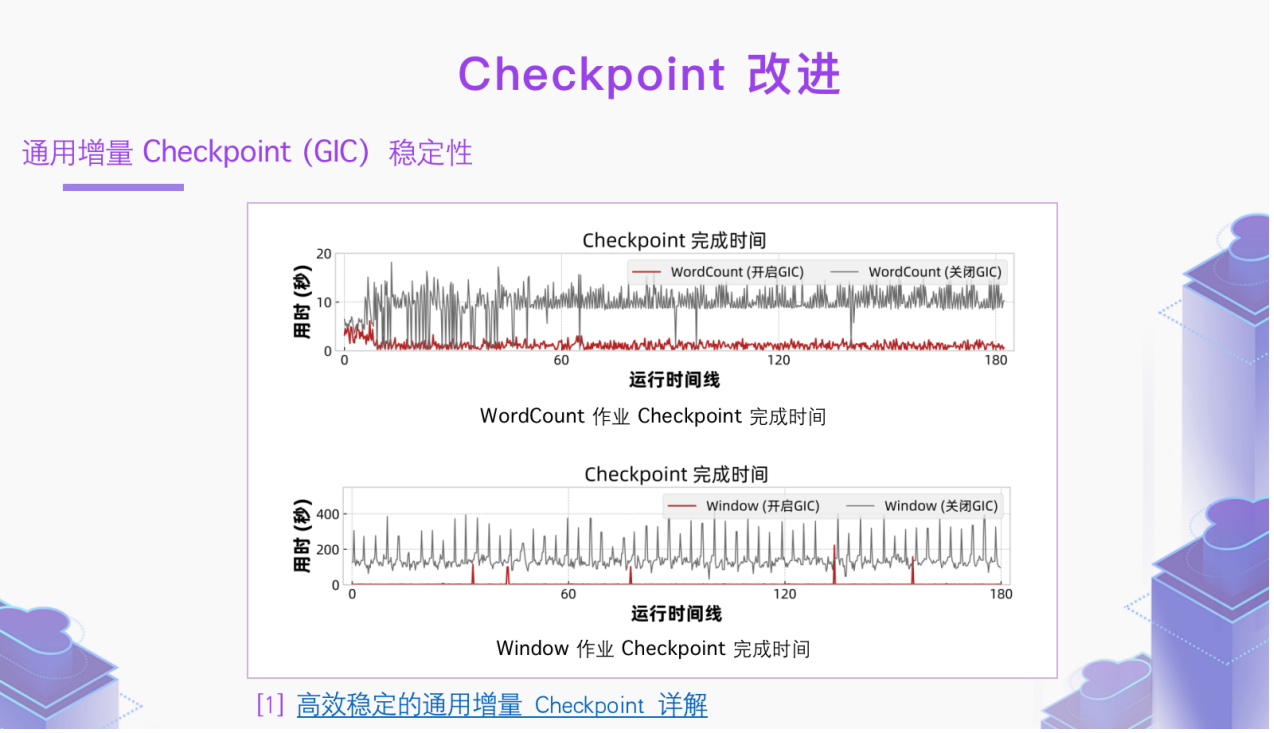
另外,我们对GIC的稳定性也做了提升。如上图所示,红线代表开启了通用增量 Checkpoint 的耗时,耗时更短,毛刺更少,这说明 WordCount 与 Window 作业的稳定性均有显著提升。而如果不开启通用增量 Checkpoint,Window 的作业耗时可高达 400s,且极不稳定。

用户写了一个 SQL Query 之后,可能在这个 Query 里有双流 Join,有聚合,有维表关联等等。那么,如何判断一个 Query 是否有问题呢?
为此,我们提供了 PLAN ADVICE 功能,在执行 Explain 语句时候支持 PLAN_ADVICE 选项。比如,在执行 Query 之前可以先做一次 Explain,得到一些建议。
如上图,告警信息提示 current_timestamp 是一个非确定性函数,源表的数据是 Changelog 流,因为源表和结果表的主键不一致,会生成一个 SinkUpsertMaterializer 算子来在 state 中物化输入并输出正确的结果给 Sink,但 SinkUpsertMaterializer 节点要求输入不能有非确定性更新,用户使用 PLAN_ADVIC 就会获得对应的建议,避免这类正确性问题。此外,社区也在计划让 SinkUpsertMaterializer 支持 upsertKey 模式,在后续的版本中可以在框架侧解决这个问题。
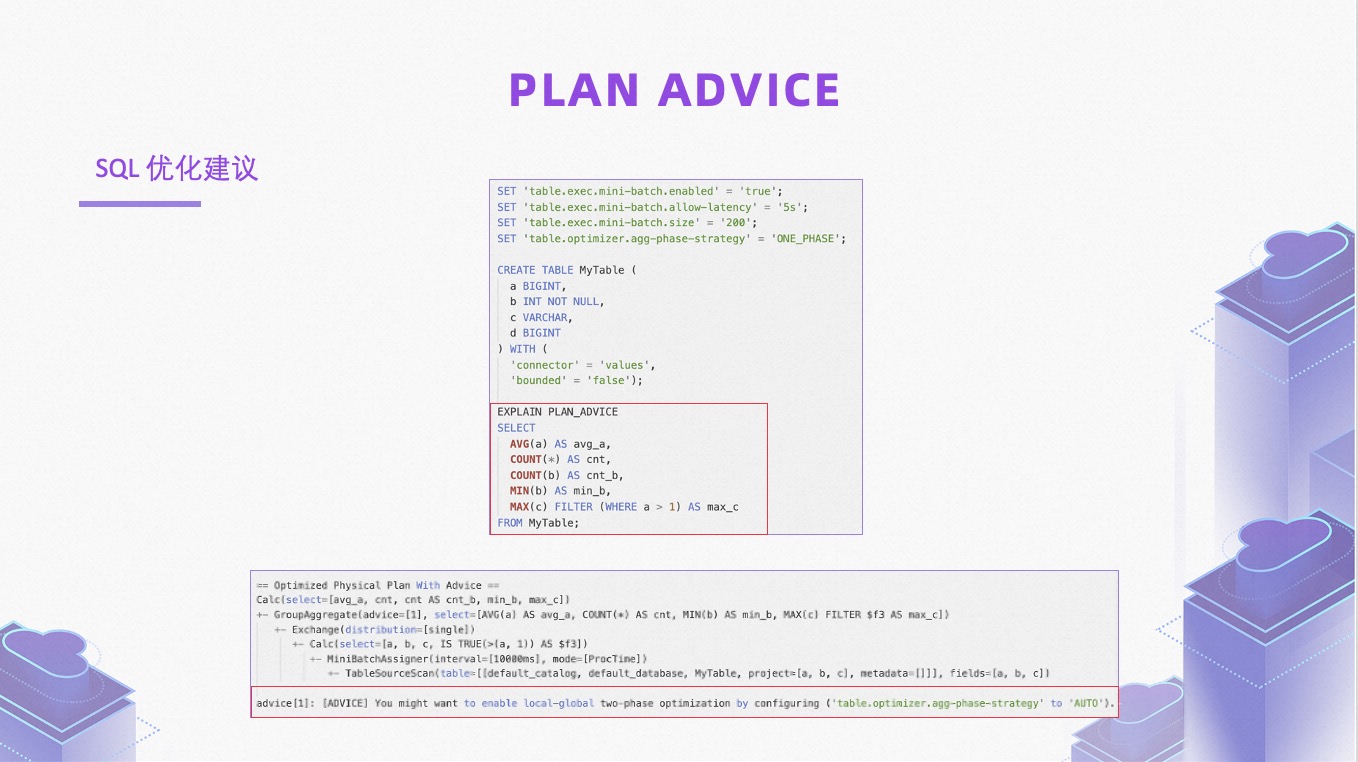
除了 PLAN 正确性建议,PLAN_ADVIC 也会提供 SQL 优化建议。 如上图所示,PLAN_ADVIC 建议开启 local global 两阶段聚合来提升 SQL 的性能。
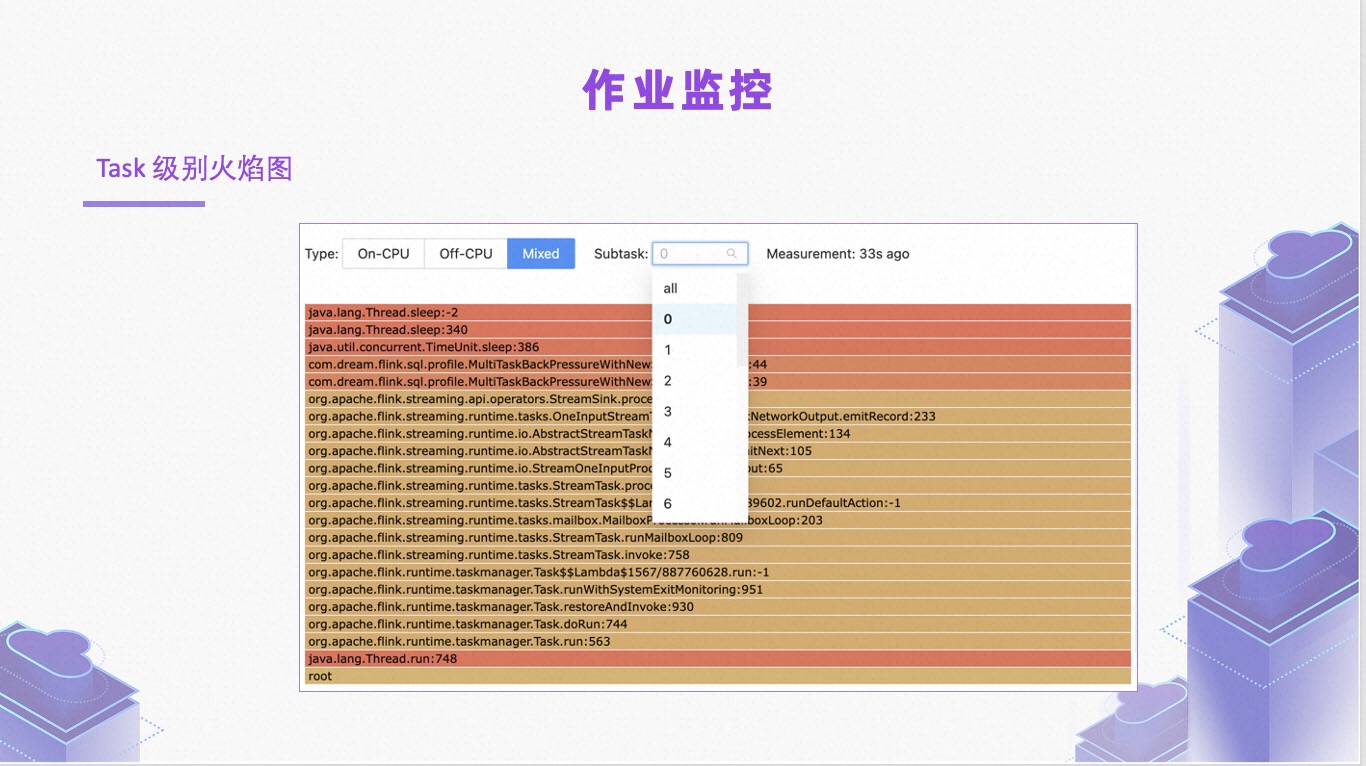
作业监控方面,Flink 1.17 将火焰图细化至 Task 级别,这对线上作业调优、问题定位提供了更多帮助,比如可以查看每个 Task 线程的耗时分布明细等。
四、Summary

总体来说,Flink 1.17 的工作主要包含以下五个方面:
-
为了更好地迈向 Streaming Warehouse,陆续提出了相关 Streaming Warehouse API。
-
对 Batch 重点优化了性能以及提升稳定性。
-
对 Streaming SQL 的语义做了增强与完善。
-
Checkpoint 的速度与稳定性都有了进一步提升。
-
对 SQL Client 以及 Gateway 工具做了进一步扩展。

Flink 1.18 的工作已经开启,Feature Freeze 预计在 7 月 11 号,Release 预计在 9 月底。用户可以点击此处,关注具体的 Feature 与 FLIP 进展。
Flink 1.18 的重点工作将会从以下四个方向展开:
-
Streaming Warehouse API 补齐。
-
Batch 性能的优化以及生态的扩展。
-
Streaming SQL 的语义以及易用性改进。
-
存算分离的 Checkpoint 的架构演进。
Q&A
Q:Flink CDC 支持 Delta Lake 吗?
A:Flink CDC 主要是 Source,Delta Lake 是 Sink 写入,CDC 捕获的数据可以写入到 Flink 支持的下游,Delta Lake 也是可以的。
Q:新版本在批处理性能上的优化,场景应用上可以有哪些提升?
A:都是普适的性能优化,能够提升 Batch 作业的性能和稳定性。
Q:实时大宽表实现有方法吗?比如十个流的 Join,无时间窗口。
A:可以做多流 Join 配合各个流的更新策略配置不同的 State TTL。
Q:Flink 支持 es 跟 clickhouse 嘛?
A:支持这两种数据源的。
Q:事实表 Left Join 多个维度表的时候,有没有什么有效的优化可以减少 State 大小和降低 Latency?
A:SQL 优化比如过滤前移,设置算子级别的 State TTL(1.18 会支持)。
Q:codegen 都用在哪些场景的优化上了?
A:一些 SQL 算子,UDF,SQL 表达式都用到了 codegen 技术
Q:Flink 资源动态扩缩可以用嘛?比如高峰多用资源,低峰自动把资源还 yarn。
A:可以了解下 Flink 的 K8s operator。
查看直播回放
这篇关于深入解读 Flink 1.17的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








