本文主要是介绍[1] Flink大数据流式处理利剑: 简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. Flink介绍
Flink是Apache基金会下的一个顶级项目,其是一个有状态计算的框架;既能处理无边界的数据流,也能处理有边界的数据流;同时Flink提供不同层次的API,从而满足不同的大数据业务处理场景。
那什么是流,任何类型的数据都可以形成一种事件流,比如,信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
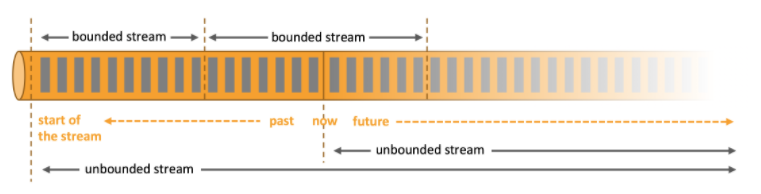
那么什么是有边界,什么是无边界;官方网站给了一张图和解释:
-
无界流
有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。 -
有界流
有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
2. Flink的前世今生
Flink的官方代码地址: https://github.com/apache/flink/releases, 目前其在github上有17800 颗点赞!
其版本演化历史如下:
- 2008:柏林理工大学的一个研究性项目Stratosphere
- 2014-04:Stratosphere贡献给Apache基金会,成为Apache的孵化项目
- 2014-12:成为Apache顶级项目
- 2016-03:Flink 1.0.0
- 2019年1月8日,阿里巴巴以9000万欧元收购该公司!
- 2021年4月:最新的版本为Flink 1.13.0
- 2021年09月29日 最新的版本为Flink 1.14.0
- 2021年12月22日,发布了Apache Flink StateFun Log4j 紧急修复版本
3. Flink特点和应用架构
- 支持Scala和Java API
- 支持批流一体
- 同时支持高吞吐、低延迟、高性能
- 支持事件时间和处理时间语义,基于事件时间语义能够针对无序事件提供精确、一致的结果;基于处理时间语义能够用在具有极低延迟需求的应用中
- 支持不同时间语义下的窗口编程
- 支持有状态计算
- 支持具有Backpressure功能的持续流模型
- 提供精确一次(exactly once)的状态一致性保障
- Flink在JVM内部实现了自己的内存管理
- 基于轻量级的分布式快照CheckPoint的容错
- 支持SavePoint机制,手工触发,适用于升级
- 支持高可用性配置(无单点失效),与k8s、Yarn、Apache Mesos紧密集成。
- 提供常见存储系统的连接器:Kafka,Elasticsearch等
- 提供详细、可自由定制的系统及应用指标(metrics)集合,用于提前定位和响应问题
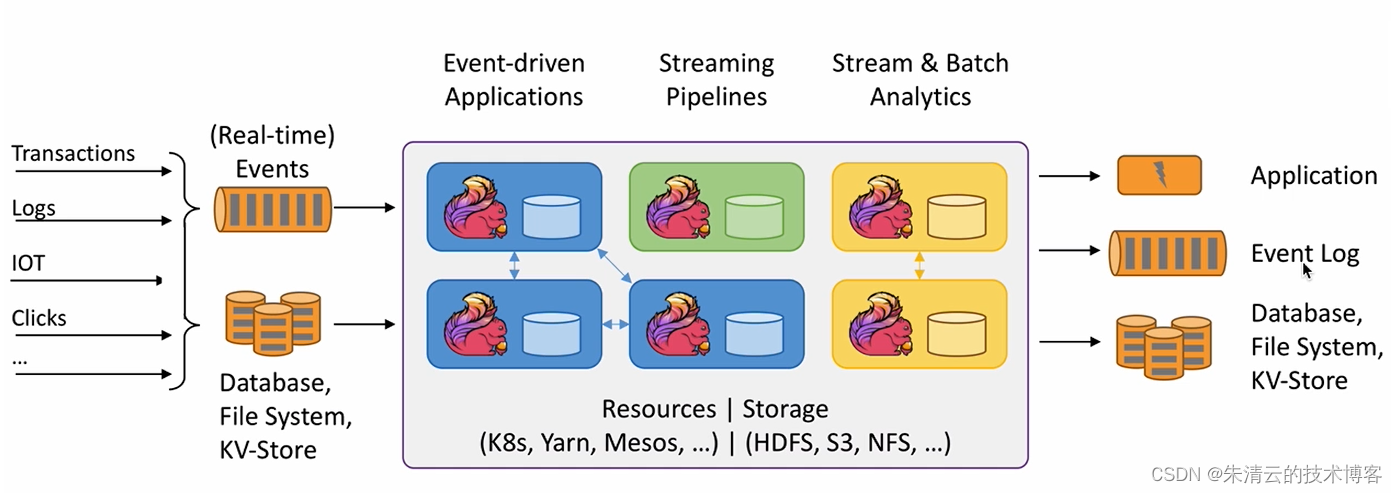
下面是其一个基本的应用架构例子。
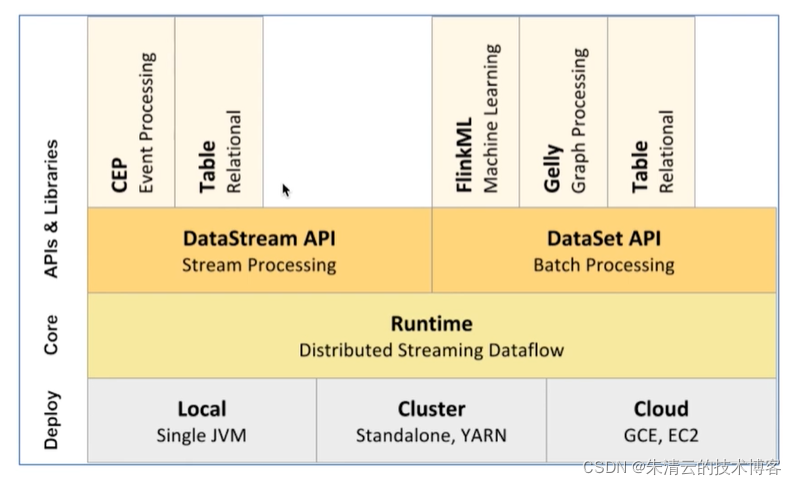
Flink整个组件的层级如下:
4. 不同框架比较
下图是其与当前业界大数据主流流式计算框架的比较
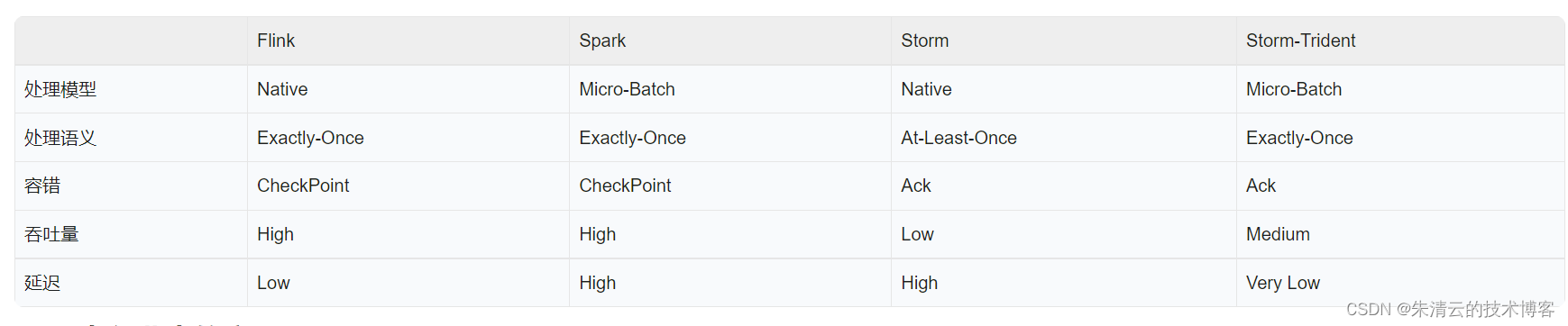
5. 案例
-
阿里巴巴如何利用Flink(Blink)
-
Saiki使用Flink而不用Spark
-
Flink在美团的使用
-
Flink在滴滴的使用
-
Flink在快手的使用
参考文献
https://github.com/apache/flink
https://flink.apache.org/usecases.html
https://flink.apache.org/flink-architecture.html
这篇关于[1] Flink大数据流式处理利剑: 简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






