本文主要是介绍【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相关博客
【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
【自然语言处理】【大模型】MPT模型结构源码解析(单机版)
【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版)
【自然语言处理】【大模型】BLOOM模型结构源码解析(单机版)
【自然语言处理】【大模型】极低资源微调大模型方法LoRA以及BLOOM-LORA实现代码
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
近日,RMT的作者放出的评测报告中声称其可以将Transformer能够处理的最大长度放宽到超过100万个tokens。让我们来看看RMT的原理及其实验细节。
一、RMT
论文地址:https://arxiv.org/pdf/2207.06881.pdf
1. 背景
自注意力机制为Transformer的核心组件之一,赋予模型针对单个token聚合上下文tokens的能力。因此,每个token在编码结束后,都能够获得丰富的上下文表示。但是,这种方式会造成全局信息和局部信息都被存储在单个表示中。全局特征被分别存储在所有的token表示上,导致全局特征“模糊”且难以访问。此外,自注意力机制的计算复杂度是输入长度的平方,这也造成模型难以应用在长文本输入上。
RMT(Recurrent Memory Transformer)是一种片段级、记忆增强的Transformer,用于解决Transformer在长文本上的问题。RMT使用一种附加在输入序列上的特定记忆token
来实现记忆机制。这些"记忆token"为模型提供了额外的存储容量,便于模型处理那些没有直接表达至任何token的信息。
2. 方法
2.1 Transformer-XL
Transformer-XL基于片段级循环和相对位置编码,实现了一种state重用的缓存机制。对于每个transformer层 n n n,前一个片段 M n M^n Mn计算出的hidden state会被缓存。第 n n n层的输入的组成:(1) 前 m m m个缓存的内容;(2) 前一个Transformer层针对当前片段 τ \tau τ的输出;即
H ~ τ n − 1 = [ S G ( M − m : n − 1 ) ∘ H τ n − 1 ] \tilde{H}_{\tau}^{n-1}=[SG(M_{-m:}^{n-1})\circ H_{\tau}^{n-1}] \\ H~τn−1=[SG(M−m:n−1)∘Hτn−1]
这里, M − m : n − 1 M_{-m:}^{n-1} M−m:n−1是第 n − 1 n-1 n−1层的前 m m m个缓存内容, S G SG SG表示不需要梯度, ∘ \circ ∘表示拼接, H τ n − 1 H_{\tau}^{n-1} Hτn−1表示模型第 n − 1 n-1 n−1层的输出。
H ~ τ n − 1 \tilde{H}_{\tau}^{n-1} H~τn−1是片段 τ \tau τ针对模型第 n n n层(TL)的输入,产生输出的过程为
Q τ n = W q n H τ n − 1 K τ n = W k n H ~ τ n − 1 V τ n = W v n H ~ τ n − 1 H τ n = T L ( Q τ n , K τ n , V τ n ) \begin{align} Q_\tau^n&=W_q^n H_{\tau}^{n-1} \\ K_\tau^n&=W_k^n \tilde{H}_{\tau}^{n-1} \\ V_\tau^n&=W_v^n\tilde{H}_{\tau}^{n-1} \\ H_\tau^n&=TL(Q_\tau^n,K_\tau^n,V_\tau^n) \end{align} \\ QτnKτnVτnHτn=WqnHτn−1=WknH~τn−1=WvnH~τn−1=TL(Qτn,Kτn,Vτn)
其中, W q n , W k n , W v n W_q^n,W_k^n,W_v^n Wqn,Wkn,Wvn是注意力的投影矩阵。注意, K τ n K_{\tau}^n Kτn和 V τ n V_{\tau}^n Vτn在计算时使用的是包含了缓存内容的 H ~ τ n − 1 \tilde{H}_{\tau}^{n-1} H~τn−1,而 Q τ n Q_\tau^n Qτn则使用了 H τ n − 1 H_\tau^{n-1} Hτn−1。在Transformer-XL的自注意力层中使用了相似位置编码。
2.2 RMT
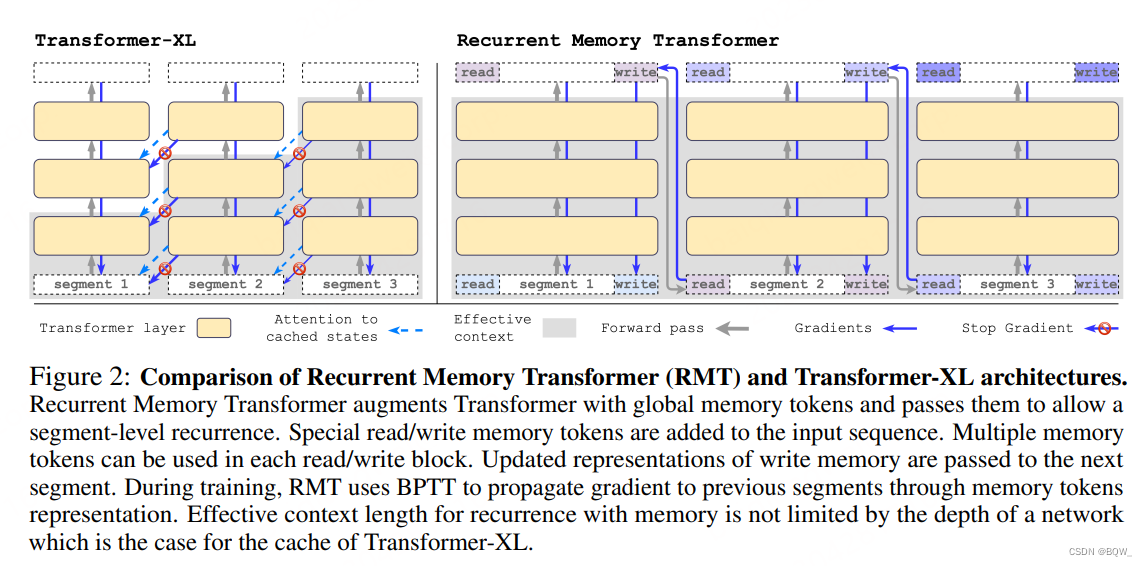
像GMAT、ETC、Memory Transformer等记忆增强的Transformer模型,通常会使用特殊的全局tokens来存储表示。通常,"记忆token"s会被添加至输入序列的开头位置。然而,decoder-only架构的causal attention mask使得在序列开始处的"记忆token"s无法收集到后续tokens的信息。若把"记忆token"放置在序列的末尾,前面的token就无法访问这些表示。为了解决这个问题,在序列样本处理时添加了一个循环。"记忆token"的表示放置在当前片段的末尾,然后作为下一个片段开始和末尾的记忆表示初始化。
RMT的输入是在标准方式基础上,添加了特殊tokens [ mem ] [\text{mem}] [mem]。每个"记忆token"都是一个实值向量。 m m m个"记忆token"分别被拼接至当前片段表示 H r 0 \text{H}_r^0 Hr0的开始和末尾:
H ~ τ 0 = [ H τ m e m ∘ H τ 0 ∘ H τ m e m ] H ˉ τ N = Transformer ( H ~ τ 0 ) [ H τ r e a d ∘ H τ N ∘ H τ w r i t e ] : = H ˉ τ N \begin{align} &\tilde{H}_{\tau}^0=[H_{\tau}^{mem}\circ H_{\tau}^0\circ H_{\tau}^{mem}] \\ &\bar{H}_\tau^N=\text{Transformer}(\tilde{H}_{\tau}^0) \\ &[H_\tau^{read}\circ H_\tau^{N}\circ H_{\tau}^{write}]:=\bar{H}_\tau^N \end{align} \\ H~τ0=[Hτmem∘Hτ0∘Hτmem]HˉτN=Transformer(H~τ0)[Hτread∘HτN∘Hτwrite]:=HˉτN
其中, N N N的模型的层数。总的来说,就是前一片段的"记忆token"拼接当前片段,然后进行前向传播。传播的结果中包含了当前层的表现以及"记忆token"的表示。
序列开始处的一组"记忆token"被称为"读记忆",其允许后续的tokens能够读取前一个片段的信息。末尾处的一组"记忆token"则称为"写记忆",其能够更新“记忆”的表示。因此, H τ w r i t e H_{\tau}^{write} Hτwrite包含了片段 τ \tau τ的更新后"记忆token"s。
输入序列中的片段会被顺序处理。为了使片段间能够循环链接,将当前片段输出的"记忆token"传递给下一个片段的输入:
H τ + 1 m e m : = H τ w r i t e H ~ τ + 1 0 = [ H τ + 1 m e m ∘ H τ + 1 0 ∘ H τ + 1 m e m ] \begin{align} & H_{\tau+1}^{mem}:= H_{\tau}^{write} \\ & \tilde{H}_{\tau+1}^0 = [H_{\tau+1}^{mem}\circ H_{\tau+1}^0\circ H_{\tau+1}^{mem}] \end{align} \\ Hτ+1mem:=HτwriteH~τ+10=[Hτ+1mem∘Hτ+10∘Hτ+1mem]
RMT是基于全局"记忆token"实现的,其能够保证骨干Transformer不变的情况下,增强任意Transformer类模型的能力。“记忆token”仅在模型的输入和输出上进行操作。
2.3 两者的区别
(1) RMT为每个片段存储 m m m个记忆向量,而Transformer-XL则为每个片段存储 m × N m\times N m×N向量。
(2) RMT会将前一个片段的记忆表示与当前片段的tokens一起送入Transformer层进行处理。
(3) "读/写记忆"块能够访问当前块的所有tokens,causal attention mask仅应用在输入序列上。
(4) 不同于Transformer-XL,RMT反向传播时不会去掉"记忆"部分的梯度。(本文实验的片段间梯度传播范围从0到4)
3. 原论文实验
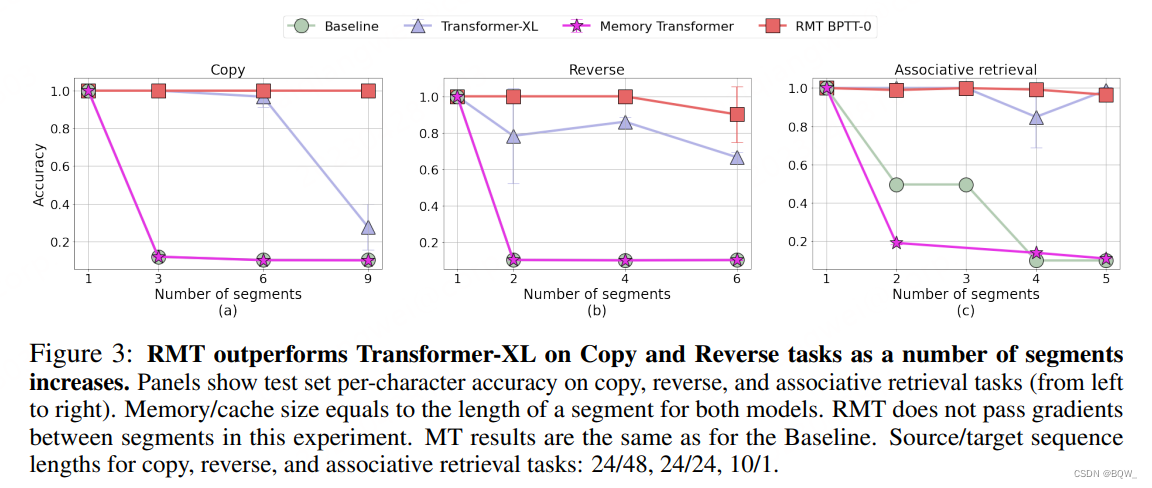
上图是RMT在三个需要长文本处理能力的任务Copy、Reverse和Associative retrieval上的实验结果。图的横坐标是切分的片段数,纵坐标是准确率。可以看到,RMT的效果都更好。
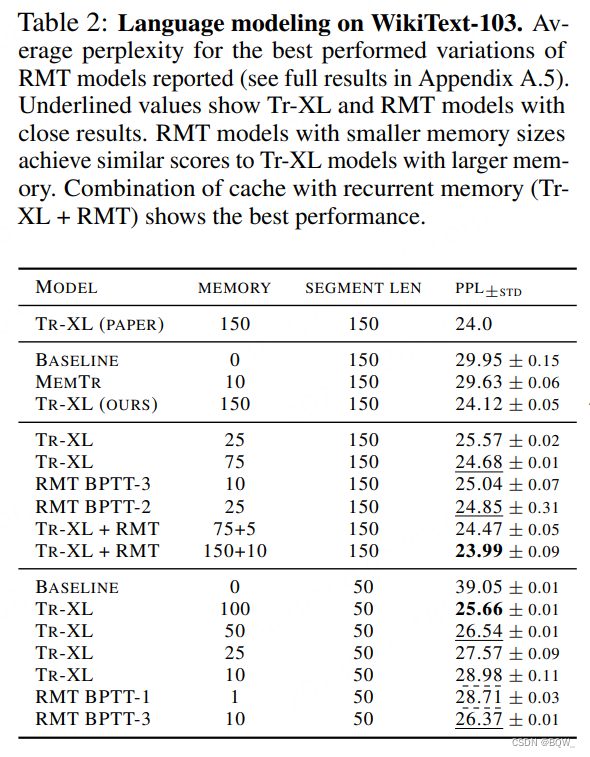
上表是语言建模任务的困惑度指标。显然,Transformer-XL和RMT的效果要好于baseline模型和Memory Transformer。
二、扩展至100万tokens
论文地址:https://arxiv.org/pdf/2304.11062.pdf
1. RMT Encoder版
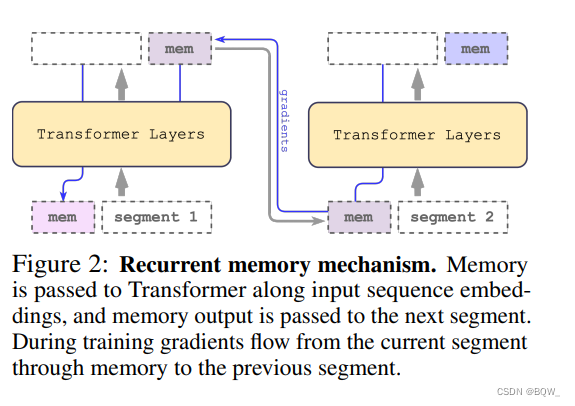
输入样本被分割为 m m m个片段,"记忆token"被添加到片段的开始,并与片段的其余tokens一起处理。对于BERT这样的encoder-only结构,"记忆token"仅被添加到片段的开始,而不像decoder-only那样分别添加read和write。对于时间步 τ \tau τ和片段 H τ 0 H_{\tau}^0 Hτ0,执行步骤为:
H ~ τ 0 = [ H τ m e m ∘ H τ 0 ] H ˉ τ N = Transformer ( H ~ τ 0 ) [ H ˉ τ m e m ∘ H τ N ] : = H ˉ τ N \begin{align} &\tilde{H}_{\tau}^0=[H_{\tau}^{mem}\circ H_{\tau}^0] \\ &\bar{H}_{\tau}^N=\text{Transformer}(\tilde{H}_{\tau}^0) \\ &[\bar{H}_{\tau}^{mem}\circ H_{\tau}^N]:=\bar{H}_{\tau}^N \end{align} H~τ0=[Hτmem∘Hτ0]HˉτN=Transformer(H~τ0)[Hˉτmem∘HτN]:=HˉτN
其中, N N N是Transformer的层数。
在前向传播后, H ˉ τ m e m \bar{H}_{\tau}^{mem} Hˉτmem片段 τ \tau τ的记忆token。输入序列的片段会按顺序逐个被处理。为了确保能够实现递归的连接,将当前片段的"记忆token"传递为下一个片段的输入:
H τ + 1 m e m : = H ˉ τ m e m H ~ τ + 1 0 = [ H τ + 1 m e m ∘ H τ + 1 0 ] \begin{align} & H_{\tau+1}^{mem}:=\bar{H}_{\tau}^{mem} \\ & \tilde{H}_{\tau+1}^0=[H_{\tau+1}^{mem}\circ H_{\tau+1}^0] \end{align} \\ Hτ+1mem:=HˉτmemH~τ+10=[Hτ+1mem∘Hτ+10]
2. 记忆任务
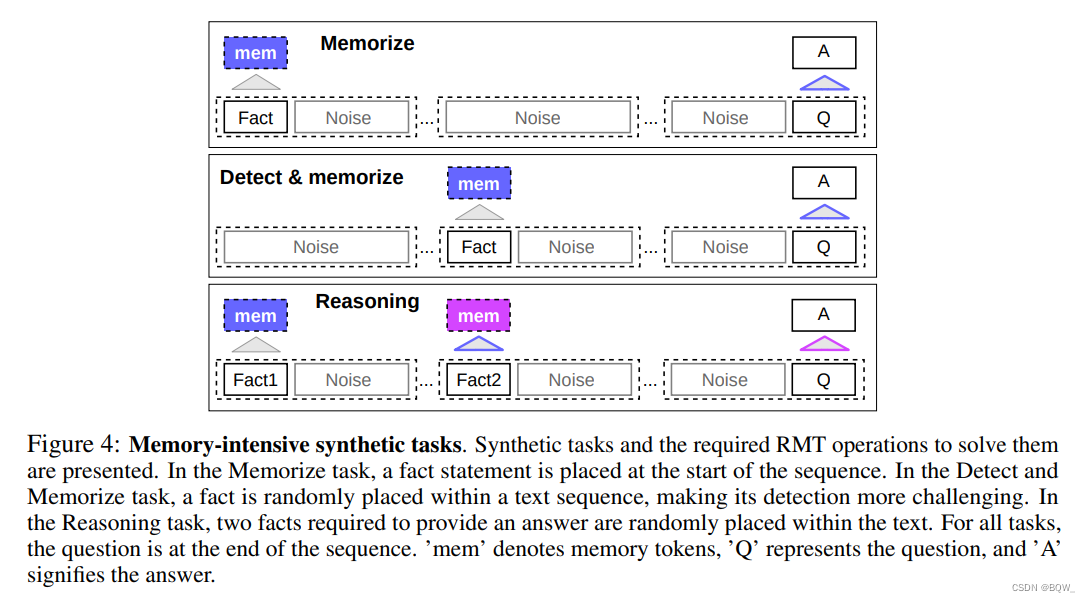
为了测试记忆能力,构建了需要记忆简单事实和基本推理的合成数据集。任务的输入是若干个事实和一个需要通过这些事实才能回答的问题。任务的形式为6分类,每个类别表示一个独立的答案选项。
-
事实记忆
该任务是测试RMT长时间存储信息的能力。在最简单的例子中,事实总是位于输入的开始,而问题在输入的末尾。问题和答案之间插入不相关的文本,完整的输入无法放入单个模型中。
-
事实检测和记忆
该任务增加了难度,将事实移动到随机的位置。需要模型从不相关文本中区分出事实,写入到记忆中,随后用来回答问题。
-
用记忆的事实进行推理
两个事实被添加至输入的随机位置上,问题放置在输入的末尾,该问题需要所有的事实才能回答。
3. 实验
实验使用bert-base-cased作为backbone。所有模型都是用尺寸为10的memory来增强,并使用AdamW优化器进行优化。
3.1 课程学习
使用训练schedule能够极大的改善准确率和稳定性。初始,RMT在较短的任务上进行训练,在训练收敛之后,再继续增加长度。
3.2 外推能力
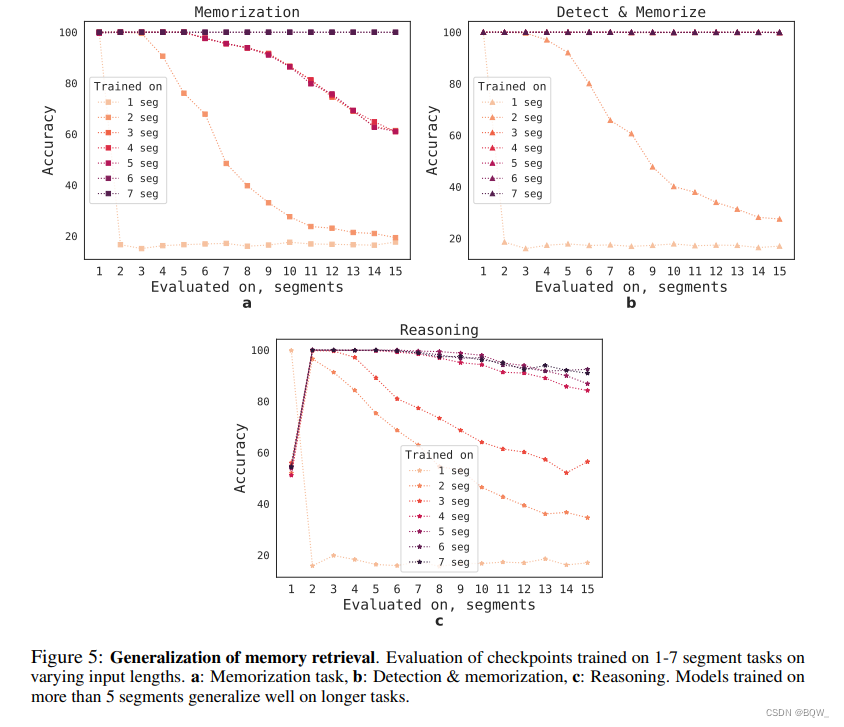
为了评估RMT泛化到不同序列长度的能力,评估了在不同长度上训练的模型,结果如上图。模型在较短的任务上效果更好。唯一的例外是单片段推理任务,模型一旦在更长序列上训练,那么效果就会变差。
随着训练片段数量的增加,RMT也能够泛化到更长的序列上。在5个或者更长的片段上进行训练后,RMT几乎可以完美的泛化到两倍的长度。

为了能够测试泛化的极限,将验证任务的尺寸从4096增加至2043904,RMT在如此长的序列上也能够有很好的效果。
三、总结
- 总的来说,RMT的思路简单。相比Transformer-XL来说,片段间传递的参数会少很多。
- RMT采用递归的方式传递信息,那么训练时梯度也需要回传,这导致训练时不太能并行。
- 原始论文中采用decoder-only架构,但是在扩展至百万tokens的实验中采用了encoder-only架构,是decoder-only的效果不够好吗?
- 评测的任务总体比较简单,迁移至当前的LLM上效果怎么样还比较难以确定。
这篇关于【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




