本文主要是介绍0基础学习PyFlink——用户自定义函数之UDTAF,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大纲
- UDTAF
- TableAggregateFunction的实现
- 累加器
- 定义
- 创建
- 累加
- 返回
- 类型
- 计算
- 完整代码
在前面几篇文章中,我们分别介绍了UDF、UDTF和UDAF这三种用户自定义函数。本节我们将介绍最后一种函数:UDTAF——用户自定义表值聚合函数。
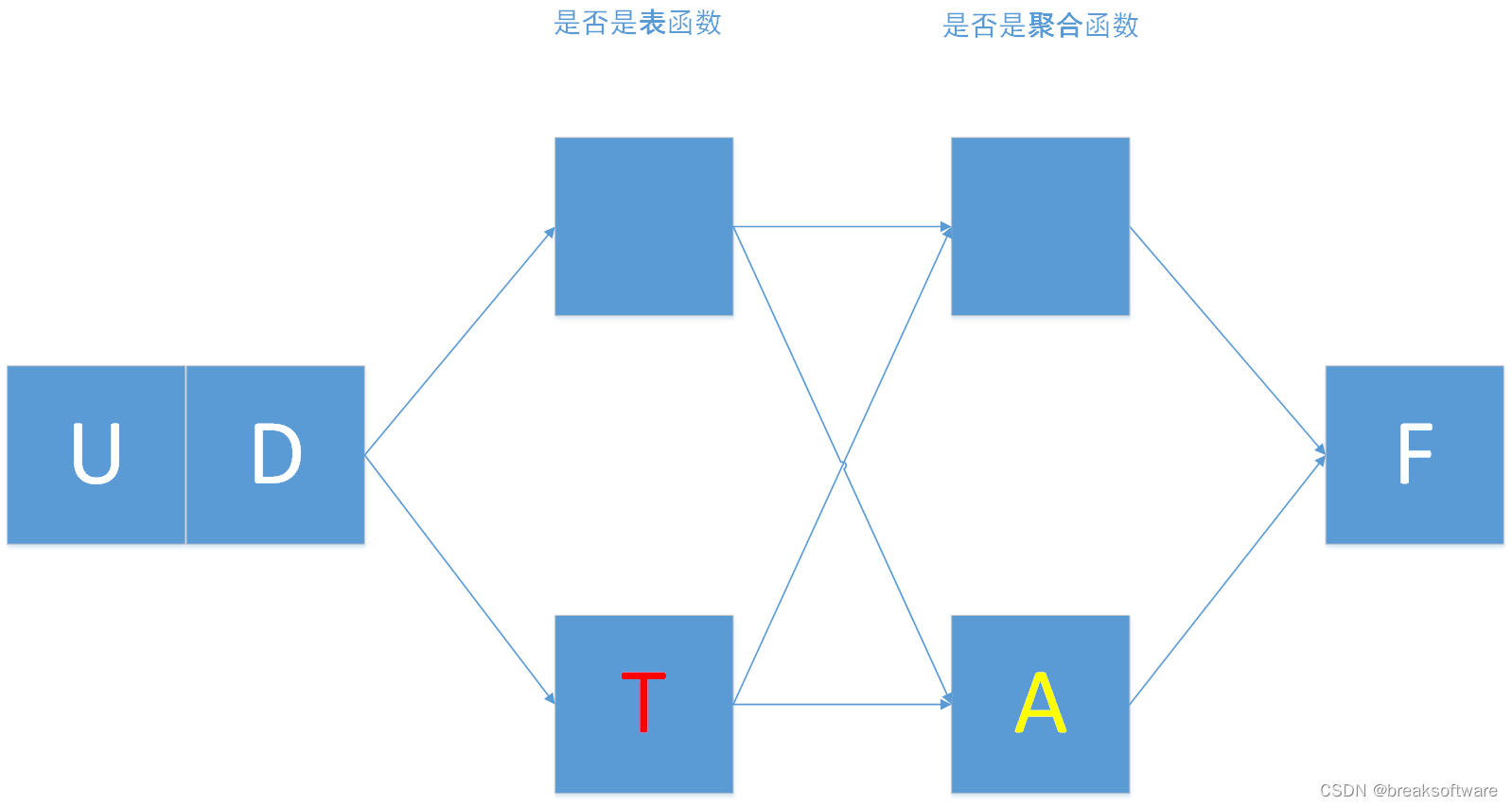
UDTAF
UDTAF函数即具备了UDTF的特点,也具备UDAF的特点。即它可以像《0基础学习PyFlink——用户自定义函数之UDTF》介绍的UDTF那样可以返回任意数量的行作为输,又可以像《0基础学习PyFlink——用户自定义函数之UDAF》介绍的UDAF那样通过聚合的数据(多组)计算出一个值。
举一个例子:我们拿到一个学生成绩表,每行包括:
- 学生姓名
- 英语成绩
- 数学成绩
- 年级
现在我们需要把这张表调整为:
- 学生姓名
- 成绩
- 科目
- 科目年级平均成绩
- 年级
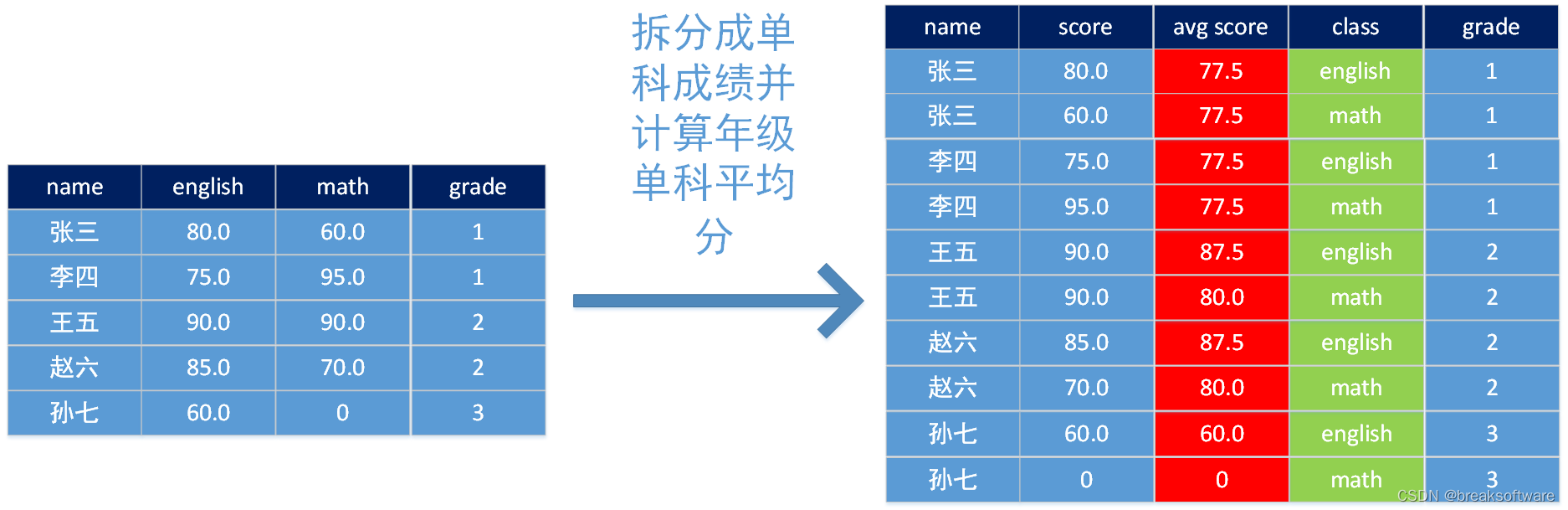
将一行中的“英语成绩”和“数学成绩”,拆成“成绩”和“科目”,相当于把一行数据拆解成多行,如上图左侧“张三”只有一行,而右侧有两行“张三”信息。这种拆解操作就需要T类型的用户自定义函数,比如UDTF和UDTAF。
而我们需要计算一个年级一科的平均成绩,比如1年级英语的平均成绩,则需要按年级聚合之后再做计算。这个就需要A类型的用户自定义函数,比如UDAF和UDTAF。
同时要满足上述两种技术方案的就是UDTAF。我们先看下主体代码,它和《0基础学习PyFlink——用户自定义函数之UDAF》中的很像。但是有两个重要区别: - 要设置成in_streaming_mode模式,否则会报错;
- udtaf要修饰一个对象,而非一个方法;
def calc():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_streaming_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('name', DataTypes.STRING()), DataTypes.FIELD('english', DataTypes.FLOAT()), DataTypes.FIELD('math', DataTypes.FLOAT()), DataTypes.FIELD('grade', DataTypes.STRING())])students_score = [("张三", 80.0, 60.0, "1"),("李四", 75.0, 95.0, "1"),("王五", 90.0, 90.0, "2"),("赵六", 85.0, 70.0, "2"),("孙七", 60.0, 0.0, "3"),]tab_source = t_env.from_elements(students_score, row_type_tab_source)split_class = udtaf(SplitClass())tab_source.group_by(col('grade')) \.flat_aggregate(split_class) \.select(col('*')) \.execute().print()
TableAggregateFunction的实现
用于计算的类要继承于TableAggregateFunction,即UDTAF中的TAF。
class SplitClass(TableAggregateFunction):_class_keys = ["english", "math"]
我们需要通过get_result_type告诉框架,UDTAF函数返回的是什么类型的数据。一般我们都是构造一个行类型——ROW,然后定义其每个字段的值和类型:
- name:string类型,用户姓名;
- score:float类型,考分;
- avg score:float类型,科目年级平均分数;
- class:sting类型,科目名称;
累加器
accumulator(累加器)是用于参与计算的中间数据。比如这个案例中,我们会向让accumulator保存拆解后的数据(即一行拆解成多行后的数据),然后再计算各年级每科的平均成绩。
定义
def get_accumulator_type(self):return DataTypes.ARRAY(DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("score", DataTypes.FLOAT()), DataTypes.FIELD("class", DataTypes.STRING())]))
因为只是为了保存展开的数据,于是我们只用定义均值计算之前的字段:
- name:string类型,姓名;
- score:float类型,分数;
- class:string类型,科目名称;
创建
刚开始时,我们让其是一个空数组,对应上定义中的ARRAY类型。
def create_accumulator(self):return []
累加
我们对科目进行遍历,进行行的拆分。即将(“张三”, 80.0, 60.0, “1”)拆解成(“张三”, 80.0, “english”)和(“张三”, 60.0, “math”)这样的两组数据。
def accumulate(self, accumulator, row):for i in self._class_keys:accumulator.append(Row(row["name"], row[i], i))
返回
类型
def get_result_type(self):return DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("score", DataTypes.FLOAT()), DataTypes.FIELD("avg score", DataTypes.FLOAT()), DataTypes.FIELD("class", DataTypes.STRING())])
可以看到result_type(返回类型)和accumulator_type(累加器类型)是不一样的(也可以一样,主要看怎么计算规则)。前者比后者多了“学科年级平均分”(avg score),这就更加接近我们希望获得的最终结果。
这些字段和我们目标字段只差一个grade(年级)。因为原始表中有grade,且我们会通过grade聚类,所以最终我们可以获得这个信息,而不用在这儿定义。
需要注意的是,虽然表值类型函数返回的是一组数据(若干Row),但是这儿只是返回Row的具体定义,而不是ARRAY[Row]。
计算
def emit_value(self, accumulator):rows = []for i in self._class_keys: total = 0.0student_count = 0for y in accumulator:# y[2] y[]"class"]if i == y[2]:# y[1] y["score"]total = total + y[1]student_count = student_count + 1avg_score = total / student_countfor y in accumulator:if i == y[2]:rows.append(Row(y[0], y[1], avg_score, y[2]))for x in rows: yield x
这个函数会在最后执行,它会通过累加器中的数据计算“学科年级平均分”,然后构造和“返回类型”一直的Row到rows数组中。最后通过yeild关键字返回一个生成器,我们可以将其看成还是一组Row,即拆解后的结果。
最后我们看下结果
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | grade | name | score | avg score | class |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 1 | 张三 | 80.0 | 77.5 | english |
| +I | 1 | 李四 | 75.0 | 77.5 | english |
| +I | 1 | 张三 | 60.0 | 77.5 | math |
| +I | 1 | 李四 | 95.0 | 77.5 | math |
| +I | 2 | 王五 | 90.0 | 87.5 | english |
| +I | 2 | 赵六 | 85.0 | 87.5 | english |
| +I | 2 | 王五 | 90.0 | 80.0 | math |
| +I | 2 | 赵六 | 70.0 | 80.0 | math |
| +I | 3 | 孙七 | 60.0 | 60.0 | english |
| +I | 3 | 孙七 | 0.0 | 0.0 | math |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
10 rows in set
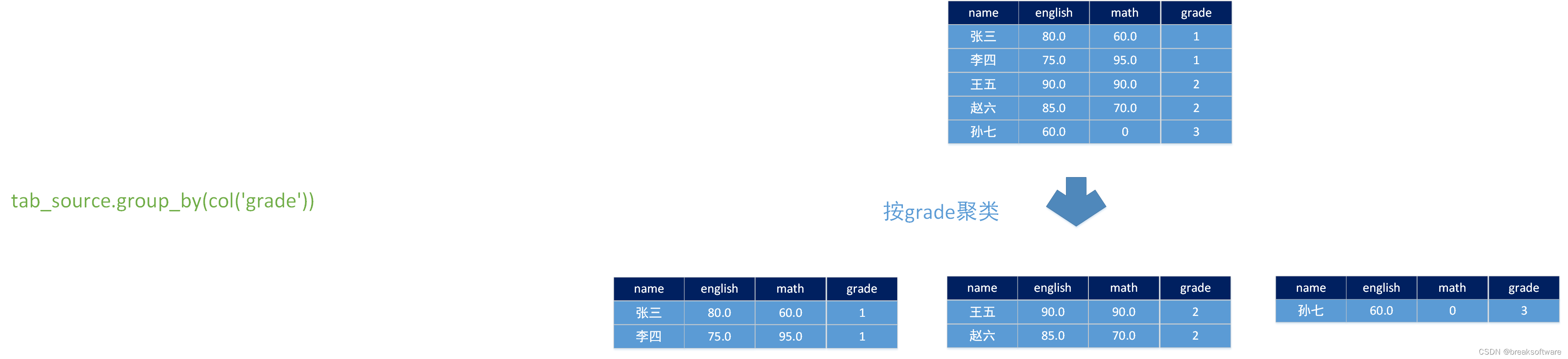
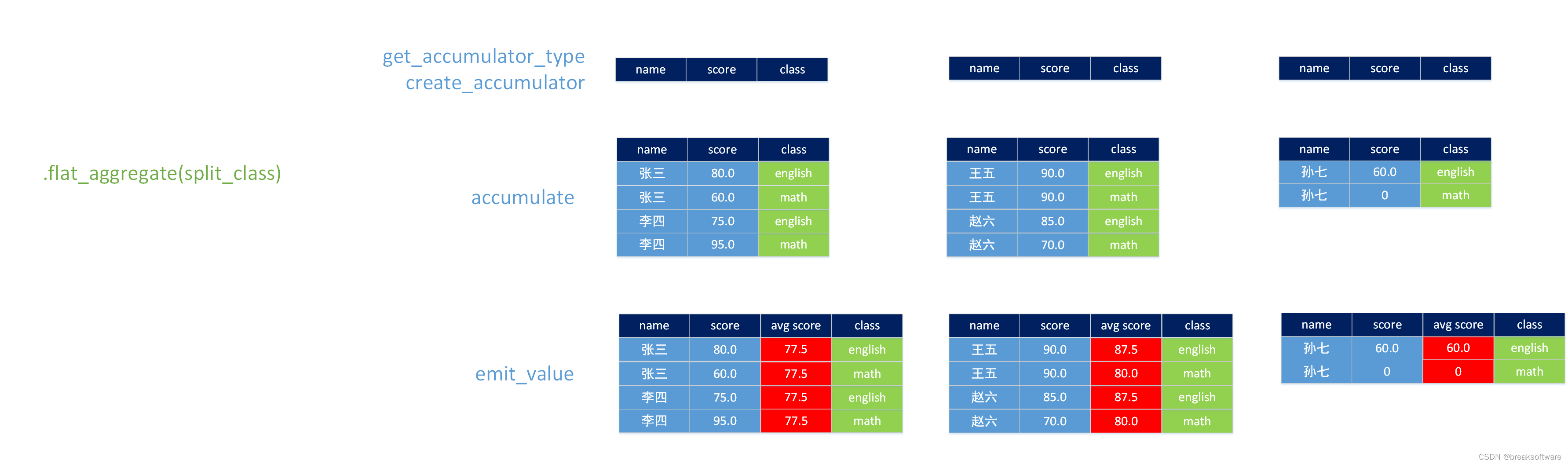

完整代码
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf,TableAggregateFunction
import pandas as pd
from pyflink.table.udf import UserDefinedFunction
from typing import Listclass SplitClass(TableAggregateFunction):_class_keys = ["english", "math"]def emit_value(self, accumulator):rows = []for i in self._class_keys: total = 0.0student_count = 0for y in accumulator:if i == y[2]:total = total + y[1]student_count = student_count + 1avg_score = total / student_countfor y in accumulator:if i == y[2]:rows.append(Row(y[0], y[1], avg_score, y[2]))return rowsdef create_accumulator(self):return []def accumulate(self, accumulator, row):for i in self._class_keys:accumulator.append(Row(row["name"], row[i], i))def get_accumulator_type(self):return DataTypes.ARRAY(DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("score", DataTypes.FLOAT()), DataTypes.FIELD("class", DataTypes.STRING())])) def get_result_type(self):return DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("score", DataTypes.FLOAT()), DataTypes.FIELD("avg score", DataTypes.FLOAT()), DataTypes.FIELD("class", DataTypes.STRING())])def calc():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_streaming_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('name', DataTypes.STRING()), DataTypes.FIELD('english', DataTypes.FLOAT()), DataTypes.FIELD('math', DataTypes.FLOAT()), DataTypes.FIELD('grade', DataTypes.STRING())])students_score = [("张三", 80.0, 60.0, "1"),("李四", 75.0, 95.0, "1"),("王五", 90.0, 90.0, "2"),("赵六", 85.0, 70.0, "2"),("孙七", 60.0, 0.0, "3"),]tab_source = t_env.from_elements(students_score, row_type_tab_source)split_class = udtaf(SplitClass())tab_source.group_by(col('grade')) \.flat_aggregate(split_class) \.select(col('*')) \.execute().print()if __name__ == '__main__':calc()
这篇关于0基础学习PyFlink——用户自定义函数之UDTAF的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


