本文主要是介绍邮件附件标题中文乱码=UTF-8Q=E9=A2=84=E8=......8D-4.pdf=,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
邮件发送时,附件标题中文乱码,本来是一个中文,但是收到邮件的时候,就显示成了=UTF-8Q=E9=A2=84=E8=A7=88_=E5=90=8D-4.pdf= 。没有稳定复现,但是出现问题的邮件能复现该现象。
调用的编码java api为:MimeUtility.encodeText()。
经过排查,发现日志如下:
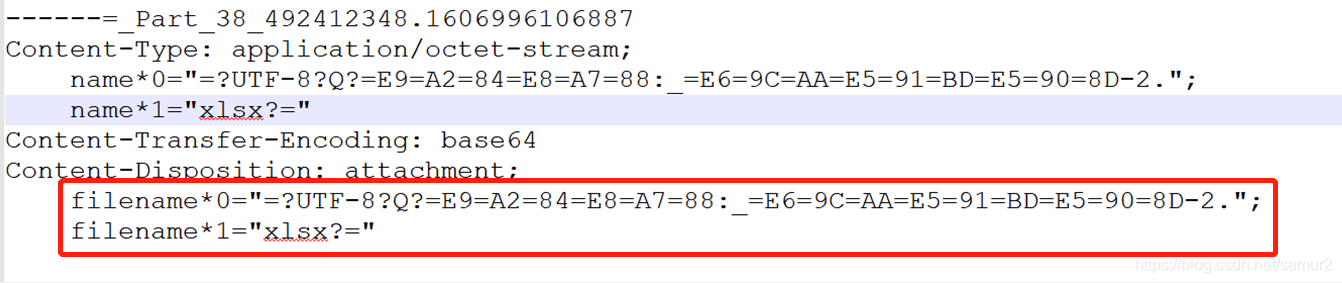
文件名编码后,在发送的过程中由于过长被截成两段了,导致解码失败。
解决方案:
System.setProperty(“mail.mime.splitlongparameters”, “false”);
这篇关于邮件附件标题中文乱码=UTF-8Q=E9=A2=84=E8=......8D-4.pdf=的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





