本文主要是介绍IGNITE 关联并置(Affinity Colocation)和分布式关联(Distributed Joins),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、并置关联(Affinity Colocation)
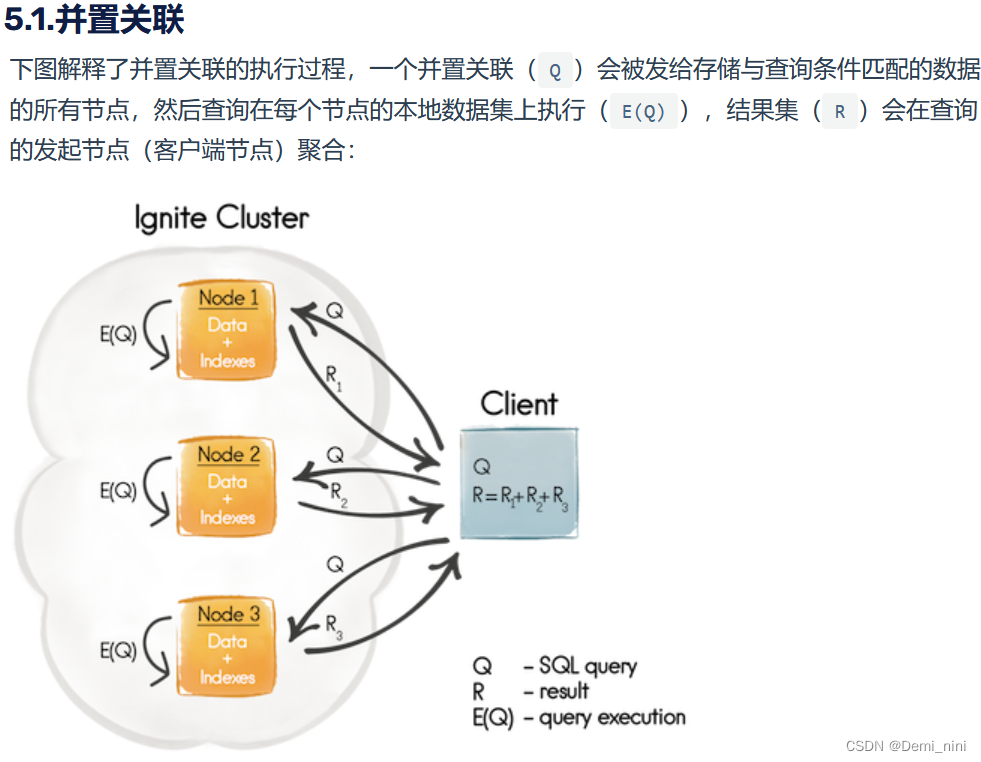
在许多情况下,如果不同的条目经常一起访问,则将它们并置在一起就很有用,即在一个节点(存储对象的节点)上就可以执行多条目查询,这个概念称为关联并置。
关联函数将条目分配给分区,具有相同关联键的对象将进入相同的分区,这样就可以设计将相关条目存储在一起的数据模型,这里的“相关”是指处于父子关系的对象或经常一起查询的对象。
我的理解:如果是分区模式partition,那么关联函数会确定键/主键对应的partition编号,会将大的数据拆分为多个小块,分别存储到不同index的partition中。如果分别存储在不同键中的数据经常一起查询(类似于SQL的多表联合查询),那么就最好使用并置关联。
使用方式见官网资料,主要就是affinity_key关键字。数据建模 | Apache Ignite - 分布式内存数据库
2、分布式关联(Distributed Joins)
分布式关联是指SQL语句中通过关联子句组合了两个或者更多的分区表,如果这些表关联在分区列(关联键)上,该关联称为并置关联,否则称为非并置关联。
Ignite默认将每个关联查询都视为并置关联,并按照并置的模式执行
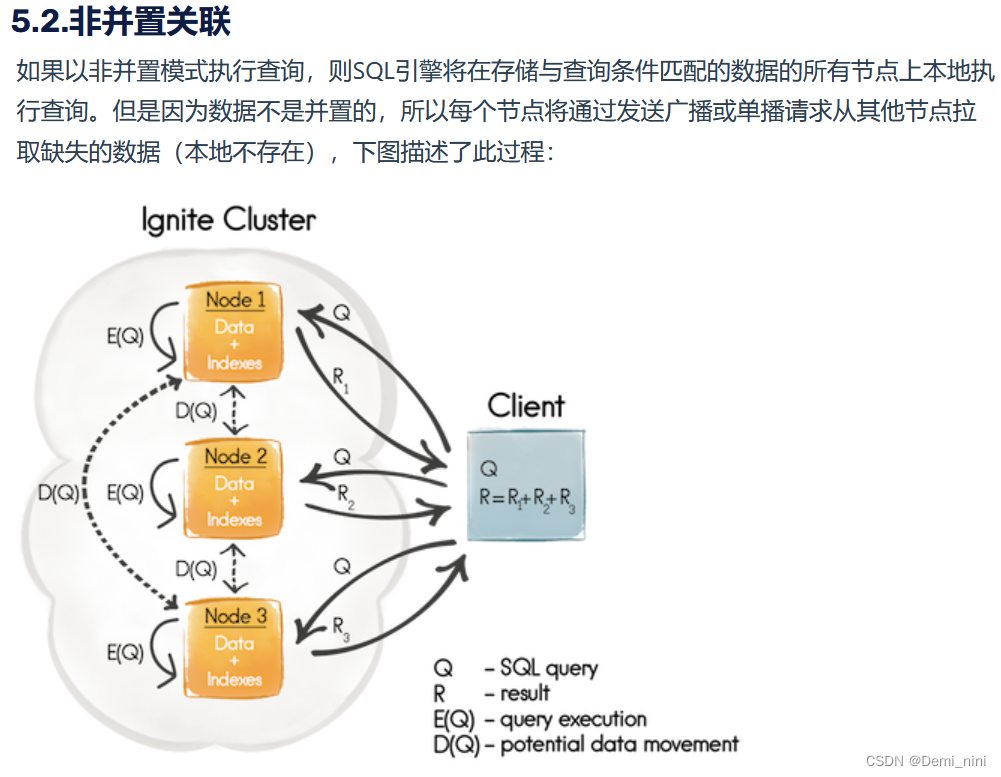
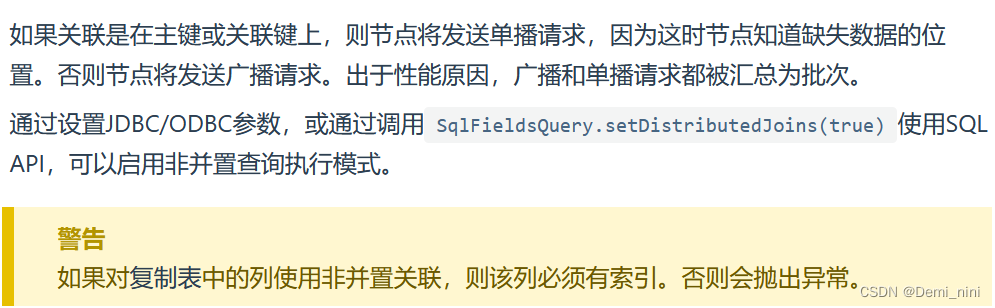
我的理解:多表联合查询时候,关联键是分区列(默认主键或者通过affinity_key声明的列),那么就是并置关联,否则就是非并置关联。默认情况下视为并置关联(distributdJoins=false),如果要采用非并置关联,需要设置distributdJoins=true
3、一些尝试
环境:ignite-2.14.0,ignite single server
3.1两表联查
- 未使用并置关联:
CREATE TABLE IF NOT EXISTS PERSON (ID INT,NAME VARCHAR,EMAIL VARCHAR,COMPANY_ID VARCHAR,PRIMARY KEY (ID)
) WITH "TEMPLATE=PARTITIONED";CREATE TABLE IF NOT EXISTS COMPANY (ID INT,NAME VARCHAR,PRIMARY KEY (ID)
) WITH "TEMPLATE=PARTITIONED";INSERT INTO PERSON (ID, NAME, EMAIL, COMPANY_ID) VALUES(10001, 'TOM', 'TOM@123.COM',1);
INSERT INTO PERSON (ID, NAME, EMAIL, COMPANY_ID) VALUES(10002, 'LILY', 'LILY@123.COM',1);
INSERT INTO PERSON (ID, NAME, EMAIL, COMPANY_ID) VALUES(10003, 'SHERRY', 'SHERRY@123.COM',2);
INSERT INTO PERSON (ID, NAME, EMAIL, COMPANY_ID) VALUES(10004, 'PETTER', 'PETTER@123.COM',2);
INSERT INTO PERSON (ID, NAME, EMAIL, COMPANY_ID) VALUES(10005, 'LIVIA', 'LIVIA@123.COM',3); INSERT INTO COMPANY (ID, NAME) VALUES(1, 'A-COMPANY');
INSERT INTO COMPANY (ID, NAME) VALUES(2, 'B-COMPANY');
INSERT INTO COMPANY (ID, NAME) VALUES(3, 'C-COMPANY'); 这里partition的index大致结果是id%1024(因为默认1024个分区),但是这并不是简单的哈希映射,起码节点宕机,未受影响的节点partition index并不会发生变化。
这里partition的index大致结果是id%1024(因为默认1024个分区),但是这并不是简单的哈希映射,起码节点宕机,未受影响的节点partition index并不会发生变化。
1.使用默认并置关联查询:当关联时用主表的列当查询条件,副表的列信息未查询出来。可以用ignite2.7.5再试试
./sqlline.sh --verbose=true -u "jdbc:ignite:thin://127.0.0.1:10800;user=ignite;password=ignite"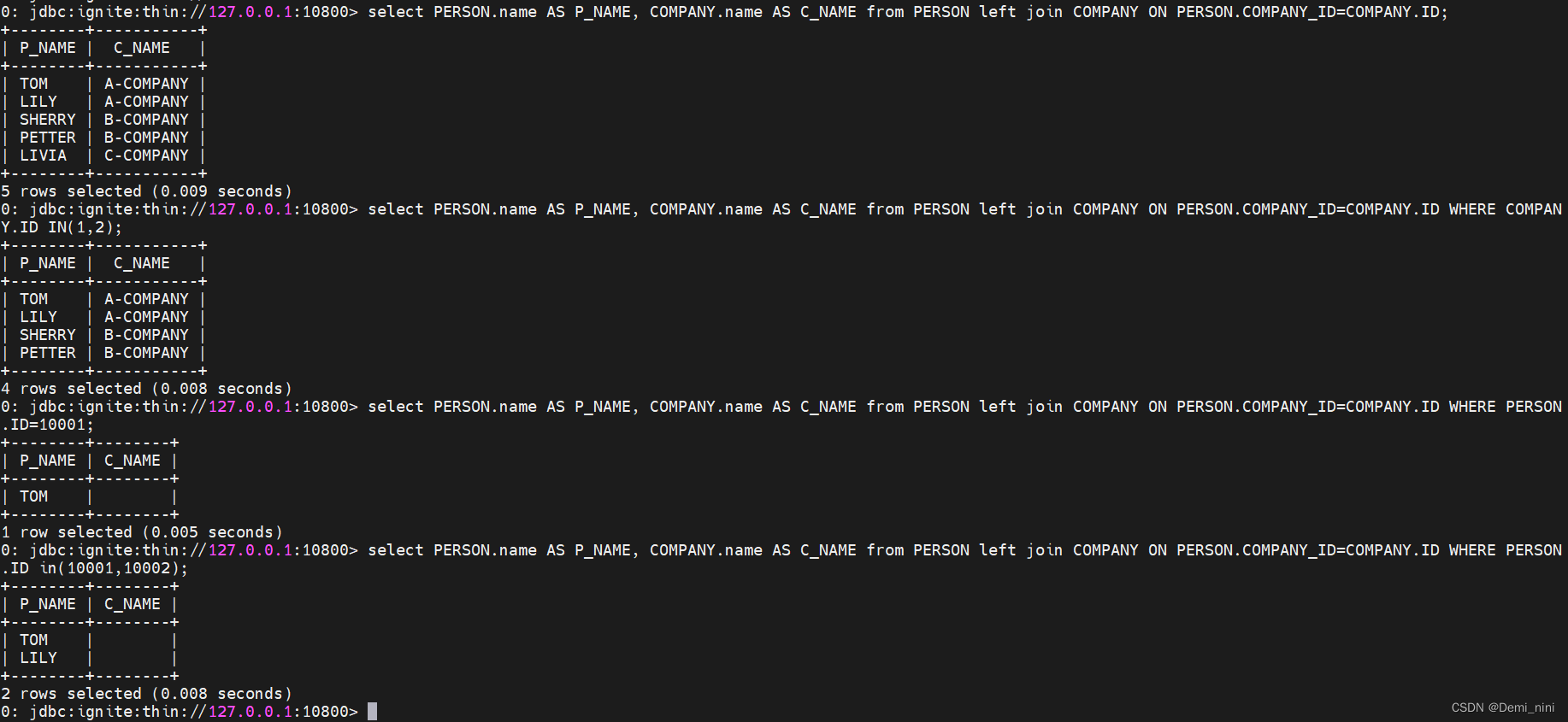
2.使用非并置查询:查询结果没问题
./sqlline.sh --verbose=true -u "jdbc:ignite:thin://127.0.0.1:10800;user=ignite;password=ignite;distributedJoins=true"
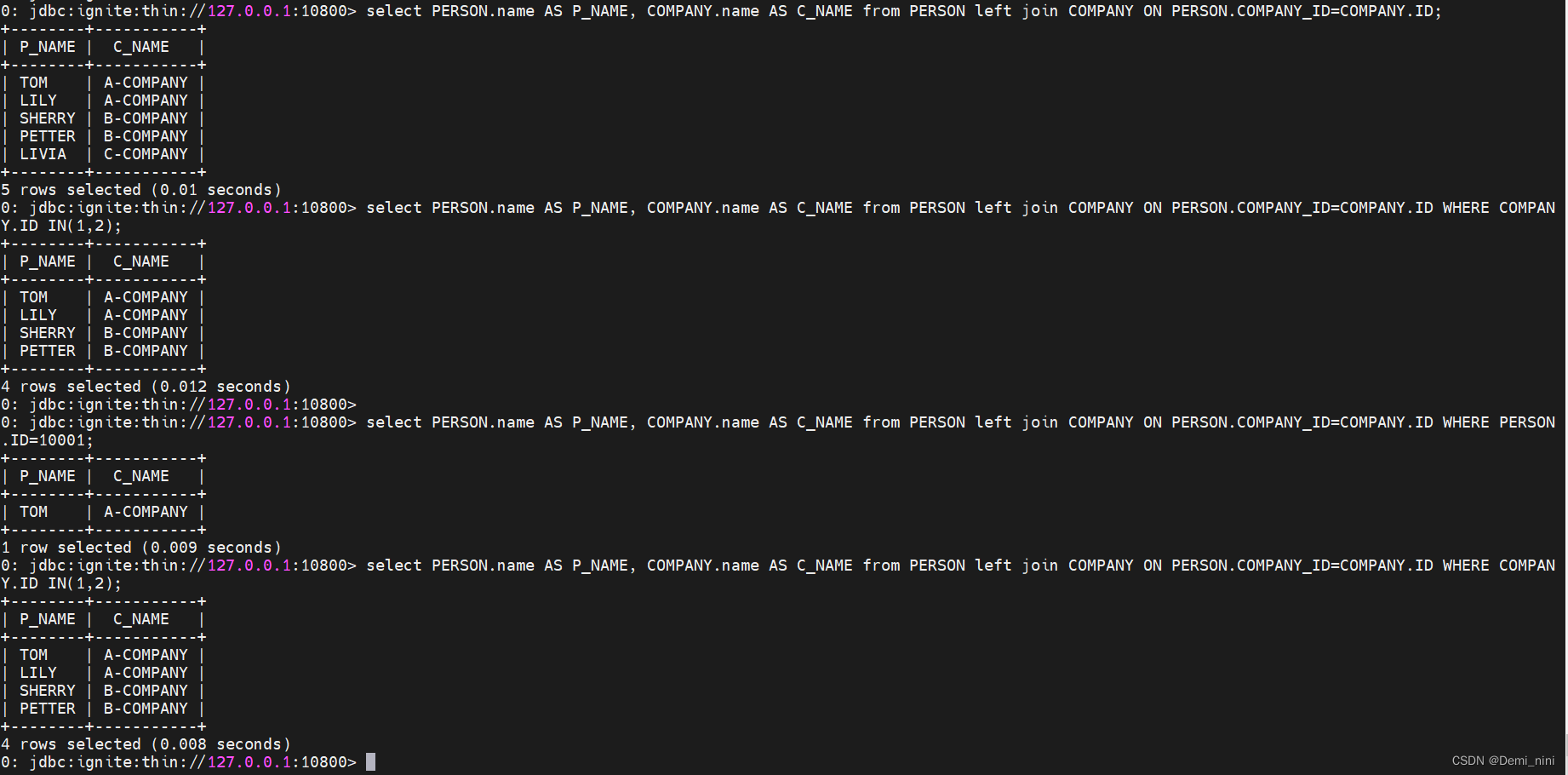
- 使用并置关联
CREATE TABLE IF NOT EXISTS PERSON (ID INT,NAME VARCHAR,EMAIL VARCHAR,COMPANY_ID VARCHAR,PRIMARY KEY (ID, COMPANY_ID)
) WITH "TEMPLATE=PARTITIONED,AFFINITY_KEY=COMPANY_ID";CREATE TABLE IF NOT EXISTS COMPANY (ID INT,NAME VARCHAR,PRIMARY KEY (ID)
) WITH "TEMPLATE=PARTITIONED";INSERT INTO PERSON (ID, NAME, EMAIL, COMPANY_ID) VALUES(10001, 'TOM', 'TOM@123.COM',1);
INSERT INTO PERSON (ID, NAME, EMAIL, COMPANY_ID) VALUES(10002, 'LILY', 'LILY@123.COM',1);
INSERT INTO PERSON (ID, NAME, EMAIL, COMPANY_ID) VALUES(10003, 'SHERRY', 'SHERRY@123.COM',2);
INSERT INTO PERSON (ID, NAME, EMAIL, COMPANY_ID) VALUES(10004, 'PETTER', 'PETTER@123.COM',2);
INSERT INTO PERSON (ID, NAME, EMAIL, COMPANY_ID) VALUES(10005, 'LIVIA', 'LIVIA@123.COM',3); INSERT INTO COMPANY (ID, NAME) VALUES(1, 'A-COMPANY');
INSERT INTO COMPANY (ID, NAME) VALUES(2, 'B-COMPANY');
INSERT INTO COMPANY (ID, NAME) VALUES(3, 'C-COMPANY');
这里person的partition index发生了变化,不清楚计算规则。
1.使用默认并置关联查询:查询无误
./sqlline.sh --verbose=true -u "jdbc:ignite:thin://127.0.0.1:10800;user=ignite;password=ignite"
2.使用非并置查询:查询结果没问题。但是感觉多此一举。
./sqlline.sh --verbose=true -u "jdbc:ignite:thin://127.0.0.1:10800;user=ignite;password=ignite;distributedJoins=true"
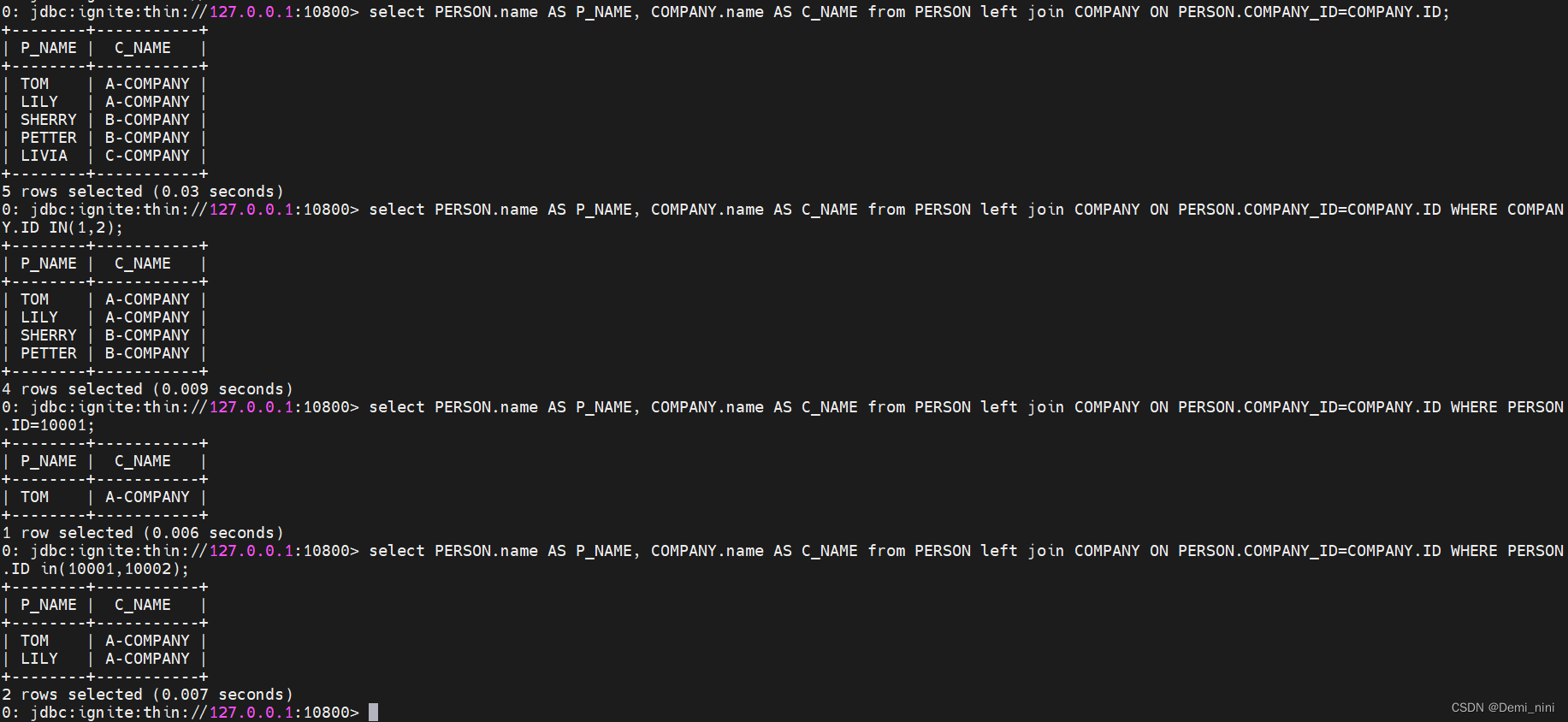
3.2 三表联查
有两张主表STUDENT和COURSE,以及一张中间表STUDENT_COURSE,如果要按照并置处理,那么中间表的两个字段STUDENT_ID和COURSE_ID都应该并置关联处理,但是affinity_Key只支持一个。所以这里只能用非并置处理。
CREATE TABLE STUDENT(ID BIGINT PRIMARY KEY,NAME VARCHAR,EMAIL VARCHAR,
) WITH "TEMPLATE=PARTITIONED,ATOMICITY=TRANSACTIONAL_SNAPSHOT";INSERT INTO STUDENT (ID, NAME, EMAIL) VALUES(10001, 'Tom', 'tom@123.com');
INSERT INTO STUDENT (ID, NAME, EMAIL) VALUES(10002, 'Lily', 'lily@123.com');
INSERT INTO STUDENT (ID, NAME, EMAIL) VALUES(10003, 'Sherry', 'sherry@123.com');
INSERT INTO STUDENT (ID, NAME, EMAIL) VALUES(10004, 'Petter', 'petter@123.com');
INSERT INTO STUDENT (ID, NAME, EMAIL) VALUES(10005, 'Livia', 'livia@123.com');CREATE TABLE STUDENT_COURSE(ID BIGINT PRIMARY KEY,STUDENT_ID BIGINT NOT NULL,COURSE_ID BIGINT NOT NULL
) WITH "TEMPLATE=PARTITIONED,ATOMICITY=TRANSACTIONAL_SNAPSHOT";INSERT INTO STUDENT_COURSE (ID, STUDENT_ID, COURSE_ID) VALUES(1, 10001, 1);
INSERT INTO STUDENT_COURSE (ID, STUDENT_ID, COURSE_ID) VALUES(2, 10002, 2);
INSERT INTO STUDENT_COURSE (ID, STUDENT_ID, COURSE_ID) VALUES(3, 10003, 3);
INSERT INTO STUDENT_COURSE (ID, STUDENT_ID, COURSE_ID) VALUES(4, 10004, 2);
INSERT INTO STUDENT_COURSE (ID, STUDENT_ID, COURSE_ID) VALUES(5, 10005, 3);CREATE TABLE COURSE(ID BIGINT PRIMARY KEY,NAME VARCHAR,CREDIT_RATING INT,
) WITH "TEMPLATE=PARTITIONED,ATOMICITY=TRANSACTIONAL_SNAPSHOT";INSERT INTO COURSE (ID, NAME, CREDIT_RATING) VALUES(1, 'Criminal Evidence', 20);
INSERT INTO COURSE (ID, NAME, CREDIT_RATING) VALUES(2, 'Employment Law', 10);
INSERT INTO COURSE (ID, NAME, CREDIT_RATING) VALUES(3, 'Jurisprudence', 30);
- 使用并置查询。我们先使用并置查询试试,结果确实是某些列无法查出结果。奇怪的是在2.7.5版本的ignite,此现象并不会出现。
./sqlline.sh --verbose=true -u "jdbc:ignite:thin://127.0.0.1:10800;user=ignite;password=ignite"
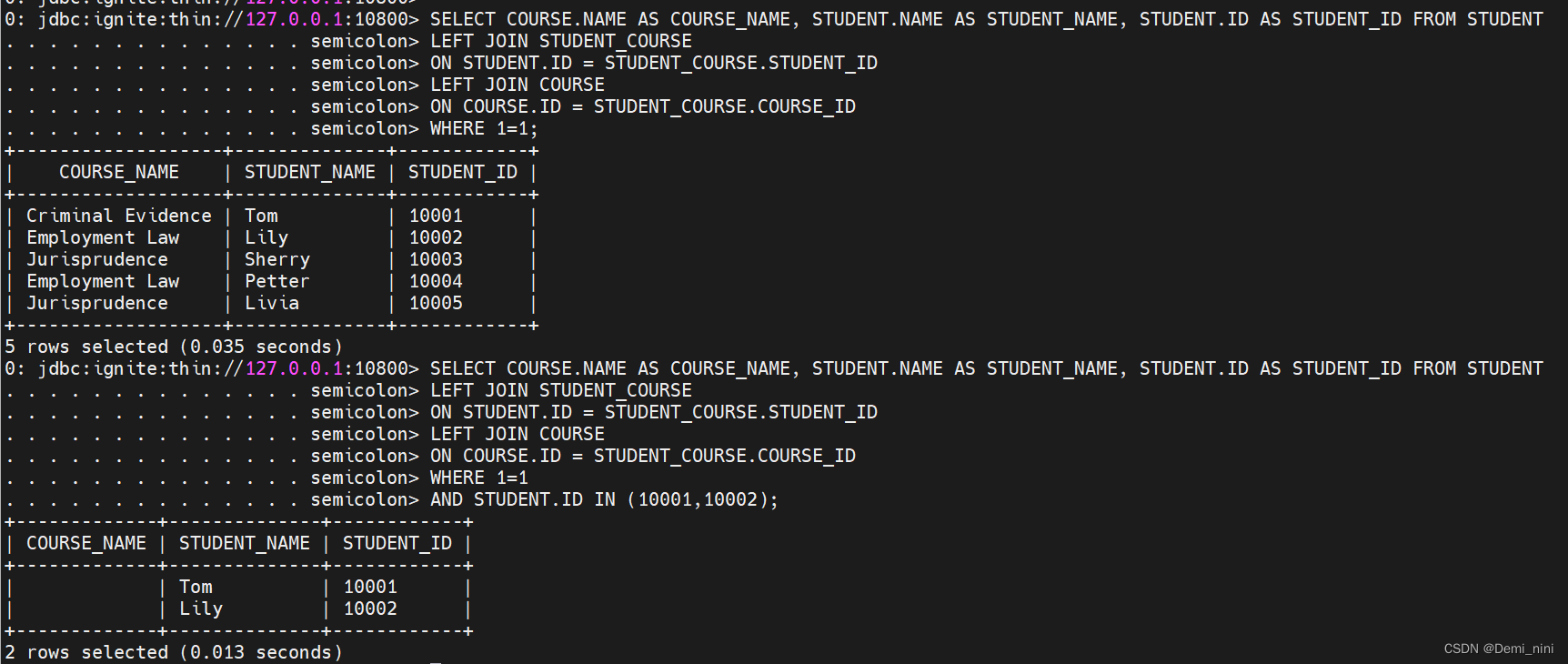
- 使用非并置查询:查询报错,提示分布式查询没有使用索引。
./sqlline.sh --verbose=true -u "jdbc:ignite:thin://127.0.0.1:10800;user=ignite;password=ignite;distributedJoins=true"

添加索引
CREATE INDEX IF NOT EXISTS STUDENT_COURSE_INDEX ON STUDENT_COURSE (STUDENT_ID,COURSE_ID);在查询,结果无误。
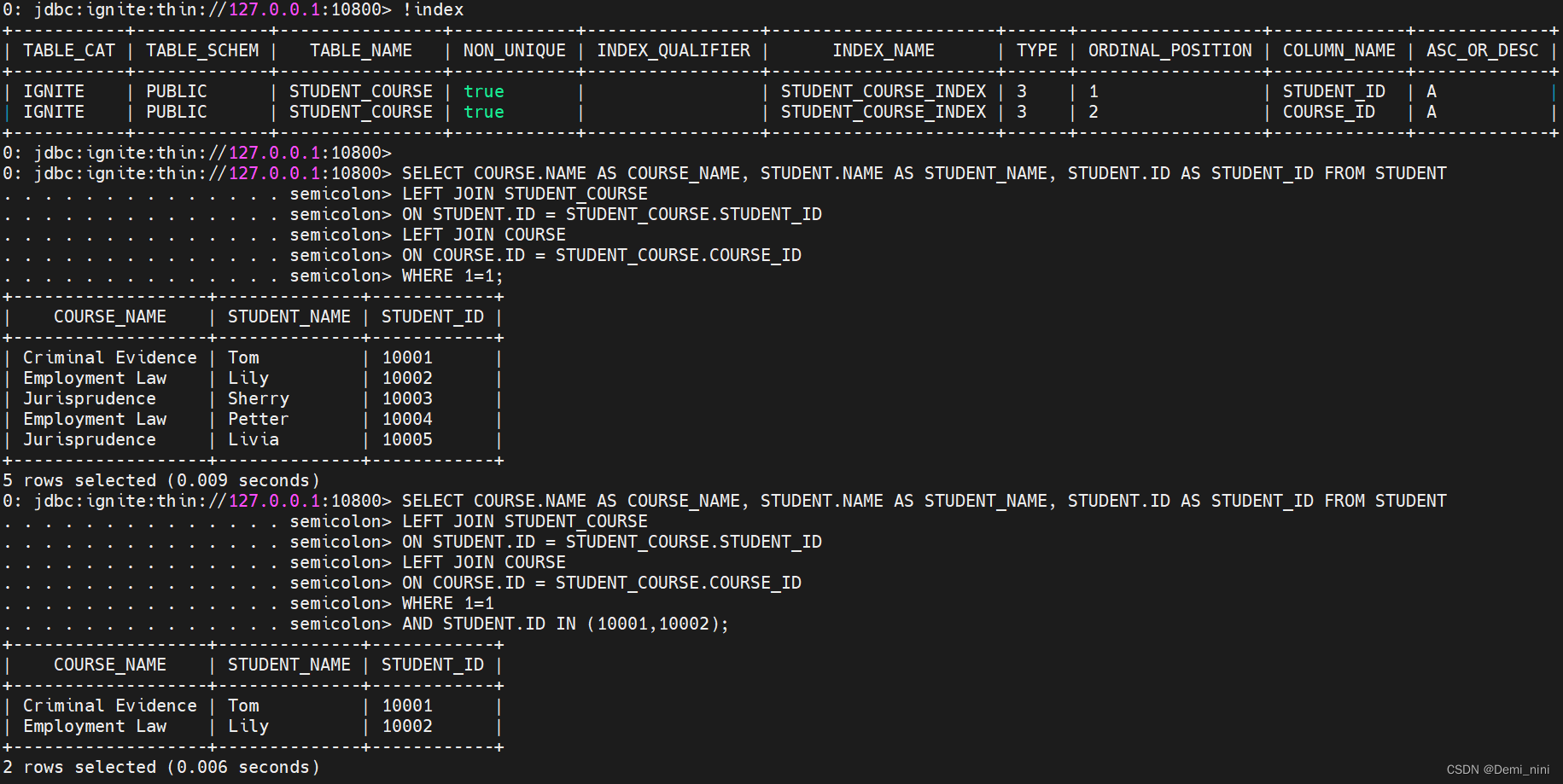
这个有个问题是:
官网描述是对于replicated模式,需要创建索引,否则异常,但是我的建表语句明确指明是partition模式,为何不建索引所以会出现异常?

这篇关于IGNITE 关联并置(Affinity Colocation)和分布式关联(Distributed Joins)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






