本文主要是介绍0基础学习PyFlink——用户自定义函数之UDAF,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大纲
- UDAF
- 入参并非表中一行(Row)的集合
- 计算每个人考了几门课
- 计算每门课有几个人考试
- 计算每个人的平均分
- 计算每课的平均分
- 计算每个人的最高分和最低分
- 入参是表中一行(Row)的集合
- 计算每个人的最高分、最低分以及所属的课程
- 计算每课的最高分数、最低分数以及所属人
- 完整代码
- 入参并非表中一行(Row)的集合
- 入参是表中一行(Row)的集合
在前面几篇文章中,我们学习了非聚合类的用户自定义函数。这节我们将介绍最简单的聚合函数UDAF。
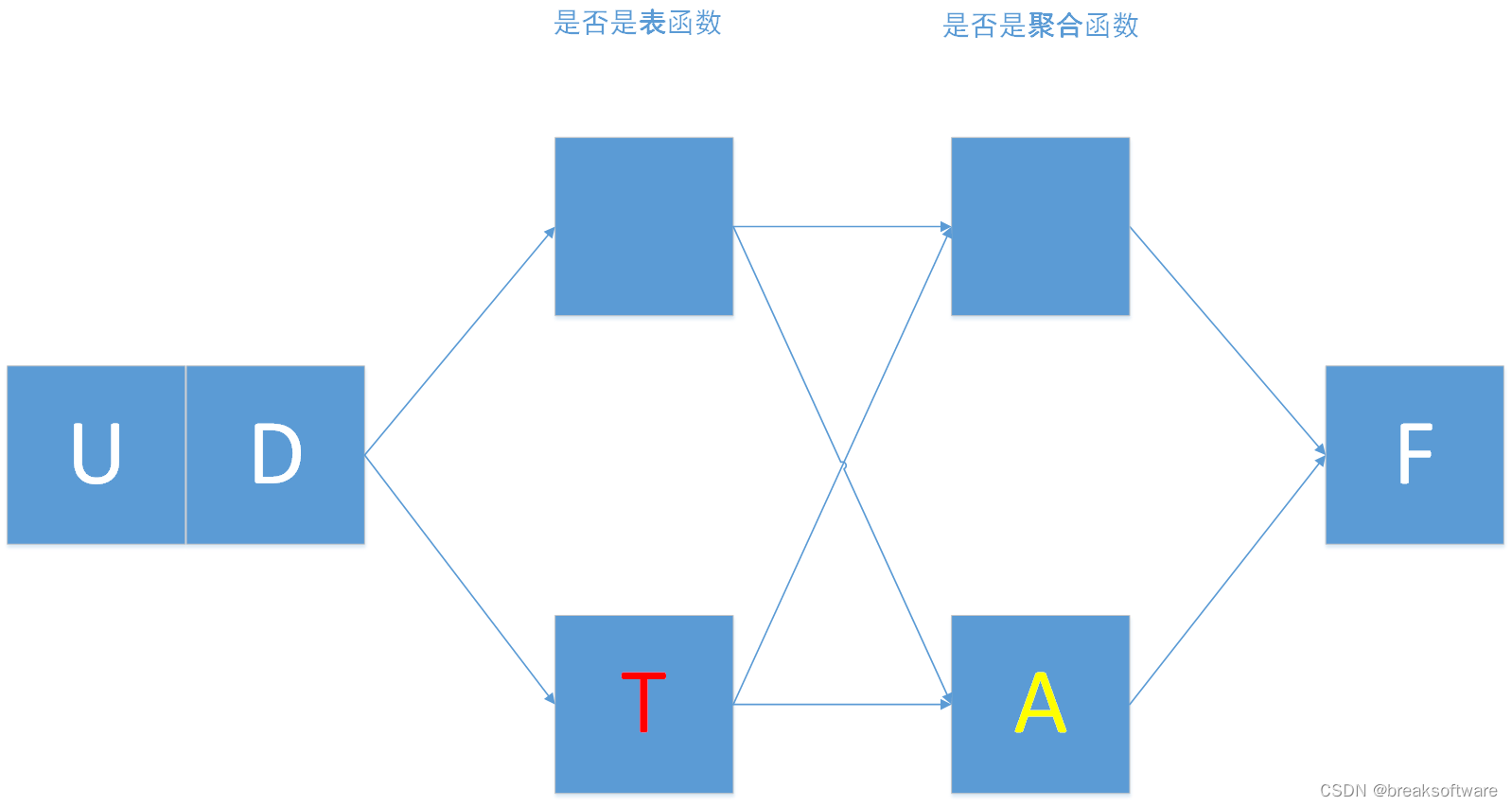
UDAF
我们对比下UDAF和UDF的定义
def udaf(f: Union[Callable, AggregateFunction, Type] = None,input_types: Union[List[DataType], DataType, str, List[str]] = None,result_type: Union[DataType, str] = None, accumulator_type: Union[DataType, str] = None,deterministic: bool = None, name: str = None,func_type: str = "general") -> Union[UserDefinedAggregateFunctionWrapper, Callable]:
def udf(f: Union[Callable, ScalarFunction, Type] = None,input_types: Union[List[DataType], DataType, str, List[str]] = None,result_type: Union[DataType, str] = None,deterministic: bool = None, name: str = None, func_type: str = "general",udf_type: str = None) -> Union[UserDefinedScalarFunctionWrapper, Callable]:
可以发现:
- udaf比udf多了一个参数accumulator_type
- udaf比udf少了一个参数udf_type
accumulator中文是“累加器”。我们可以将其看成聚合过后(比如GroupBy)的成批数据,每批都要走一次函数。
举一个例子:我们对图中左侧的成绩单,使用人名(name)进行聚类,然后计算出最高分数。即算出每个人考出的最高分数是多少。
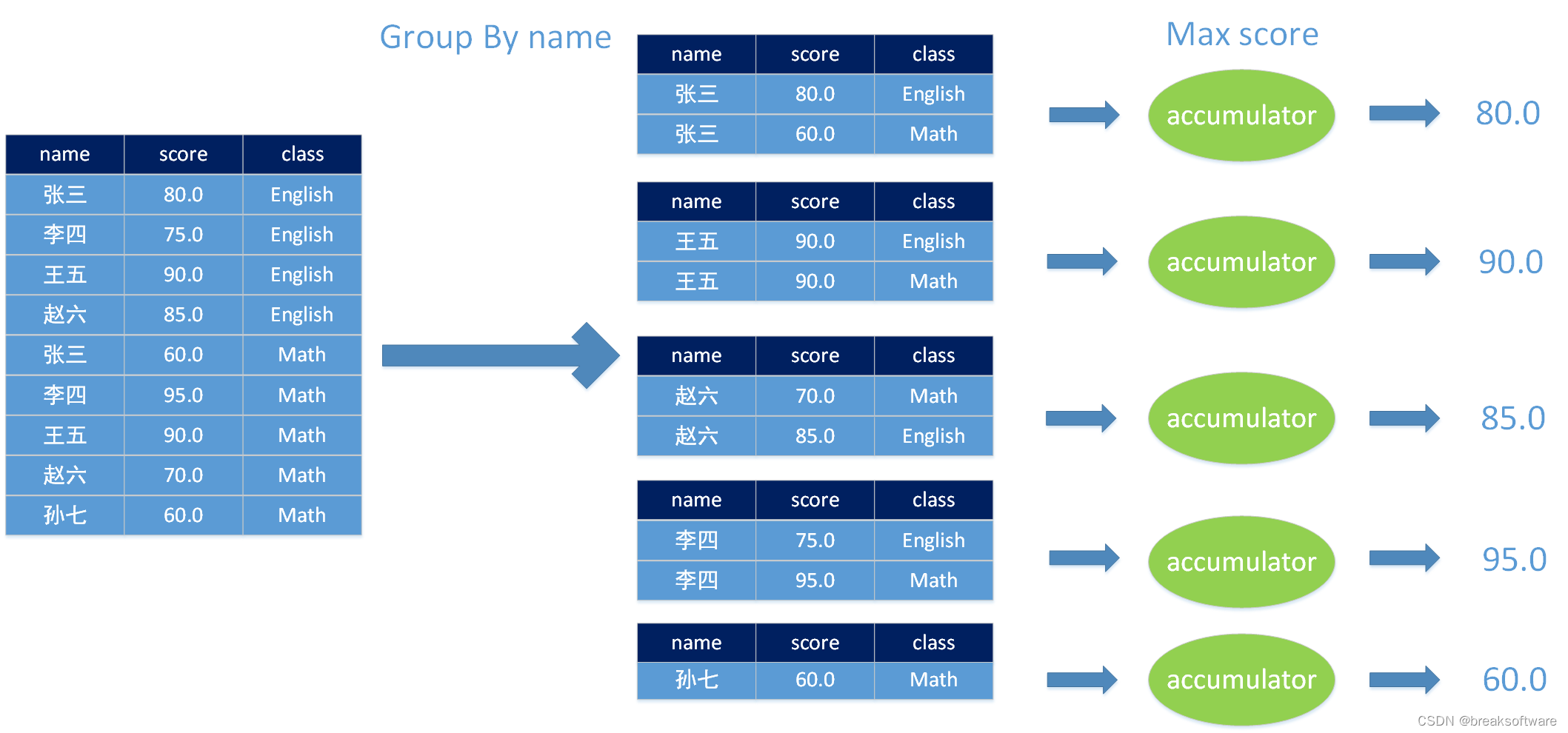
如图所示,聚合后的数据每个都会经过accumulator计算。计算出来的值的类型就是accumulator_type。这个类型的数据是中间态,它并不是最终UDAF返回的数据类型——result_type。具体这块的知识我们会在后面讲解。
为了方便讲解,我们就以上面例子来讲解其使用。先贴出准备的代码:
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf
import pandas as pd
from pyflink.table.udf import UserDefinedFunctiondef calc():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('name', DataTypes.STRING()), DataTypes.FIELD('score', DataTypes.FLOAT()), DataTypes.FIELD('class', DataTypes.STRING())])students_score = [("张三", 80.0, "English"),("李四", 75.0, "English"),("王五", 90.0, "English"),("赵六", 85.0, "English"),("张三", 60.0, "Math"),("李四", 95.0, "Math"),("王五", 90.0, "Math"),("赵六", 70.0, "Math"),("孙七", 60.0, "Math"),]tab_source = t_env.from_elements(students_score, row_type_tab_source )
我们在tab_source表中录入了学生的成绩信息,其中包括姓名(name)、成绩(score)和科目(class)。
入参并非表中一行(Row)的集合
计算每个人考了几门课
- 按姓名(name)聚类
- UDTF统计聚类后集合的个数并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("count", DataTypes.BIGINT())]), func_type="pandas")def exam_count(pandas_df: pd.DataFrame):return Row(pandas_df.count())tab_student_exam_count = tab_source.group_by(col('name')) \.aggregate(exam_count(col('name')).alias("count")) \.select(col('name'), col('count')) tab_student_exam_count.execute().print()
+--------------------------------+----------------------+
| name | count |
+--------------------------------+----------------------+
| 孙七 | 1 |
| 张三 | 2 |
| 李四 | 2 |
| 王五 | 2 |
| 赵六 | 2 |
+--------------------------------+----------------------+
5 rows in set
计算每门课有几个人考试
- 按姓名(class)聚类
- UDTF统计聚类后集合的个数并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("count", DataTypes.BIGINT())]), func_type="pandas")def exam_count(pandas_df: pd.DataFrame):return Row(pandas_df.count())tab_class_exam_count = tab_source.group_by(col('class')) \.aggregate(exam_count(col('class')).alias("count")) \.select(col('class'), col('count')) tab_class_exam_count.execute().print()
+--------------------------------+----------------------+
| class | count |
+--------------------------------+----------------------+
| English | 4 |
| Math | 5 |
+--------------------------------+----------------------+
2 rows in set
计算每个人的平均分
- 按姓名(name)聚类
- UDTF统计聚类后集合的均值并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("avg", DataTypes.FLOAT())]), func_type="pandas")def avg_score(pandas_df: pd.DataFrame):return Row(pandas_df.mean())tab_student_avg_score = tab_source.group_by(col('name')) \.aggregate(avg_score(col('score')).alias("avg")) \.select(col('name'), col('avg')) tab_student_avg_score.execute().print()
+--------------------------------+--------------------------------+
| name | avg |
+--------------------------------+--------------------------------+
| 孙七 | 60.0 |
| 张三 | 70.0 |
| 李四 | 85.0 |
| 王五 | 90.0 |
| 赵六 | 77.5 |
+--------------------------------+--------------------------------+
5 rows in set
计算每课的平均分
- 按姓名(class)聚类
- UDTF统计聚类后集合的均值并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("avg", DataTypes.FLOAT())]), func_type="pandas")def avg_score(pandas_df: pd.DataFrame):return Row(pandas_df.mean())tab_class_avg_score = tab_source.group_by(col('class')) \.aggregate(avg_score(col('score')).alias("avg")) \.select(col('class'), col('avg')) tab_class_avg_score.execute().print()
+--------------------------------+--------------------------------+
| class | avg |
+--------------------------------+--------------------------------+
| English | 82.5 |
| Math | 75.0 |
+--------------------------------+--------------------------------+
2 rows in set
计算每个人的最高分和最低分
- 按姓名(name)聚类
- UDTF统计聚类后集合的最大值和最小值,并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("min", DataTypes.FLOAT())]), func_type="pandas")def max_min_score(pandas_df: pd.DataFrame):return Row(pandas_df.max(), pandas_df.min())tab_student_max_min_score = tab_source.group_by(col('name')) \.aggregate(max_min_score(col('score')).alias("max", "min")) \.select(col('name'), col('max'), col('min')) tab_student_max_min_score.execute().print()
+--------------------------------+--------------------------------+--------------------------------+
| name | max | min |
+--------------------------------+--------------------------------+--------------------------------+
| 孙七 | 60.0 | 60.0 |
| 张三 | 80.0 | 60.0 |
| 李四 | 95.0 | 75.0 |
| 王五 | 90.0 | 90.0 |
| 赵六 | 85.0 | 70.0 |
+--------------------------------+--------------------------------+--------------------------------+
5 rows in set
入参是表中一行(Row)的集合
计算每个人的最高分、最低分以及所属的课程
- 按姓名(name)聚类
- UDTF统计聚类后集合中分数最大值、最小值;分数最大值所在行的课程名,和分数最小值所在行的课程名,并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("max tag", DataTypes.STRING()), DataTypes.FIELD("min", DataTypes.FLOAT()), DataTypes.FIELD("min tag", DataTypes.STRING())]), func_type="pandas")def max_min_score_with_class(pandas_df: pd.DataFrame):return Row(pandas_df["score"].max(), pandas_df.loc[pandas_df["score"].idxmax(), "class"], pandas_df["score"].min(), pandas_df.loc[pandas_df["score"].idxmin(), "class"])tab_student_max_min_score = tab_source.group_by(col('name')) \.aggregate(max_min_score_with_class.alias("max", "class(max)", "min", "class(min)")) \.select(col('name'), col('max'), col('class(max)'), col('min'), col('class(min)')) tab_student_max_min_score.execute().print()
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| name | max | class(max) | min | class(min) |
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| 孙七 | 60.0 | Math | 60.0 | Math |
| 张三 | 80.0 | English | 60.0 | Math |
| 李四 | 95.0 | Math | 75.0 | English |
| 王五 | 90.0 | English | 90.0 | English |
| 赵六 | 85.0 | English | 70.0 | Math |
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
5 rows in set
计算每课的最高分数、最低分数以及所属人
- 按姓名(class)聚类
- UDTF统计聚类后集合中分数最大值、最小值;分数最大值所在行的人名,和分数最小值所在行的人名,并返回
- 别名UDTF返回的列名
- select出数据
@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("max tag", DataTypes.STRING()), DataTypes.FIELD("min", DataTypes.FLOAT()), DataTypes.FIELD("min tag", DataTypes.STRING())]), func_type="pandas")def max_min_score_with_name(pandas_df: pd.DataFrame):return Row(pandas_df["score"].max(), pandas_df.loc[pandas_df["score"].idxmax(), "name"], pandas_df["score"].min(), pandas_df.loc[pandas_df["score"].idxmin(), "name"])tab_class_max_min_score = tab_source.group_by(col('class')) \.aggregate(max_min_score_with_name.alias("max", "name(max)", "min", "name(min)")) \.select(col('class'), col('max'), col('name(max)'), col('min'), col('name(min)')) tab_class_max_min_score.execute().print()
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| class | max | name(max) | min | name(min) |
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| English | 90.0 | 王五 | 75.0 | 李四 |
| Math | 95.0 | 李四 | 60.0 | 张三 |
+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
2 rows in set
完整代码
入参并非表中一行(Row)的集合
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf
import pandas as pd
from pyflink.table.udf import UserDefinedFunctiondef calc():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('name', DataTypes.STRING()), DataTypes.FIELD('score', DataTypes.FLOAT()), DataTypes.FIELD('class', DataTypes.STRING())])students_score = [("张三", 80.0, "English"),("李四", 75.0, "English"),("王五", 90.0, "English"),("赵六", 85.0, "English"),("张三", 60.0, "Math"),("李四", 95.0, "Math"),("王五", 90.0, "Math"),("赵六", 70.0, "Math"),("孙七", 60.0, "Math"),]tab_source = t_env.from_elements(students_score, row_type_tab_source )@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("count", DataTypes.BIGINT())]), func_type="pandas")def exam_count(pandas_df: pd.DataFrame):return Row(pandas_df.count())tab_student_exam_count = tab_source.group_by(col('name')) \.aggregate(exam_count(col('name')).alias("count")) \.select(col('name'), col('count')) tab_student_exam_count.execute().print()tab_class_exam_count = tab_source.group_by(col('class')) \.aggregate(exam_count(col('class')).alias("count")) \.select(col('class'), col('count')) tab_class_exam_count.execute().print()@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("avg", DataTypes.FLOAT())]), func_type="pandas")def avg_score(pandas_df: pd.DataFrame):return Row(pandas_df.mean())tab_student_avg_score = tab_source.group_by(col('name')) \.aggregate(avg_score(col('score')).alias("avg")) \.select(col('name'), col('avg')) tab_student_avg_score.execute().print()tab_class_avg_score = tab_source.group_by(col('class')) \.aggregate(avg_score(col('score')).alias("avg")) \.select(col('class'), col('avg')) tab_class_avg_score.execute().print()@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("min", DataTypes.FLOAT())]), func_type="pandas")def max_min_score(pandas_df: pd.DataFrame):return Row(pandas_df.max(), pandas_df.min())tab_student_max_min_score = tab_source.group_by(col('name')) \.aggregate(max_min_score(col('score')).alias("max", "min")) \.select(col('name'), col('max'), col('min')) tab_student_max_min_score.execute().print()if __name__ == '__main__':calc()
入参是表中一行(Row)的集合
from pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, col
from pyflink.common import Row
from pyflink.table.udf import udf,udtf,udaf,udtaf
import pandas as pd
from pyflink.table.udf import UserDefinedFunctiondef calc():config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)row_type_tab_source = DataTypes.ROW([DataTypes.FIELD('name', DataTypes.STRING()), DataTypes.FIELD('score', DataTypes.FLOAT()), DataTypes.FIELD('class', DataTypes.STRING())])students_score = [("张三", 80.0, "English"),("李四", 75.0, "English"),("王五", 90.0, "English"),("赵六", 85.0, "English"),("张三", 60.0, "Math"),("李四", 95.0, "Math"),("王五", 90.0, "Math"),("赵六", 70.0, "Math"),("孙七", 60.0, "Math"),]tab_source = t_env.from_elements(students_score, row_type_tab_source )@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("max tag", DataTypes.STRING()), DataTypes.FIELD("min", DataTypes.FLOAT()), DataTypes.FIELD("min tag", DataTypes.STRING())]), func_type="pandas")def max_min_score_with_class(pandas_df: pd.DataFrame):return Row(pandas_df["score"].max(), pandas_df.loc[pandas_df["score"].idxmax(), "class"], pandas_df["score"].min(), pandas_df.loc[pandas_df["score"].idxmin(), "class"])tab_student_max_min_score = tab_source.group_by(col('name')) \.aggregate(max_min_score_with_class.alias("max", "class(max)", "min", "class(min)")) \.select(col('name'), col('max'), col('class(max)'), col('min'), col('class(min)')) tab_student_max_min_score.execute().print()@udaf(result_type=DataTypes.ROW([DataTypes.FIELD("max", DataTypes.FLOAT()), DataTypes.FIELD("max tag", DataTypes.STRING()), DataTypes.FIELD("min", DataTypes.FLOAT()), DataTypes.FIELD("min tag", DataTypes.STRING())]), func_type="pandas")def max_min_score_with_name(pandas_df: pd.DataFrame):return Row(pandas_df["score"].max(), pandas_df.loc[pandas_df["score"].idxmax(), "name"], pandas_df["score"].min(), pandas_df.loc[pandas_df["score"].idxmin(), "name"])tab_class_max_min_score = tab_source.group_by(col('class')) \.aggregate(max_min_score_with_name.alias("max", "name(max)", "min", "name(min)")) \.select(col('class'), col('max'), col('name(max)'), col('min'), col('name(min)')) tab_class_max_min_score.execute().print()if __name__ == '__main__':calc()这篇关于0基础学习PyFlink——用户自定义函数之UDAF的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



