本文主要是介绍基于 gma 的栅格运算思路与应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
整体思路
gma 有限度的提供栅格读取、处理等操作过程,并提供标准化的栅格处理思路,方便自主进行栅格数据运算等操作。基于 gma 的栅格运算标准思路和流程如下图:
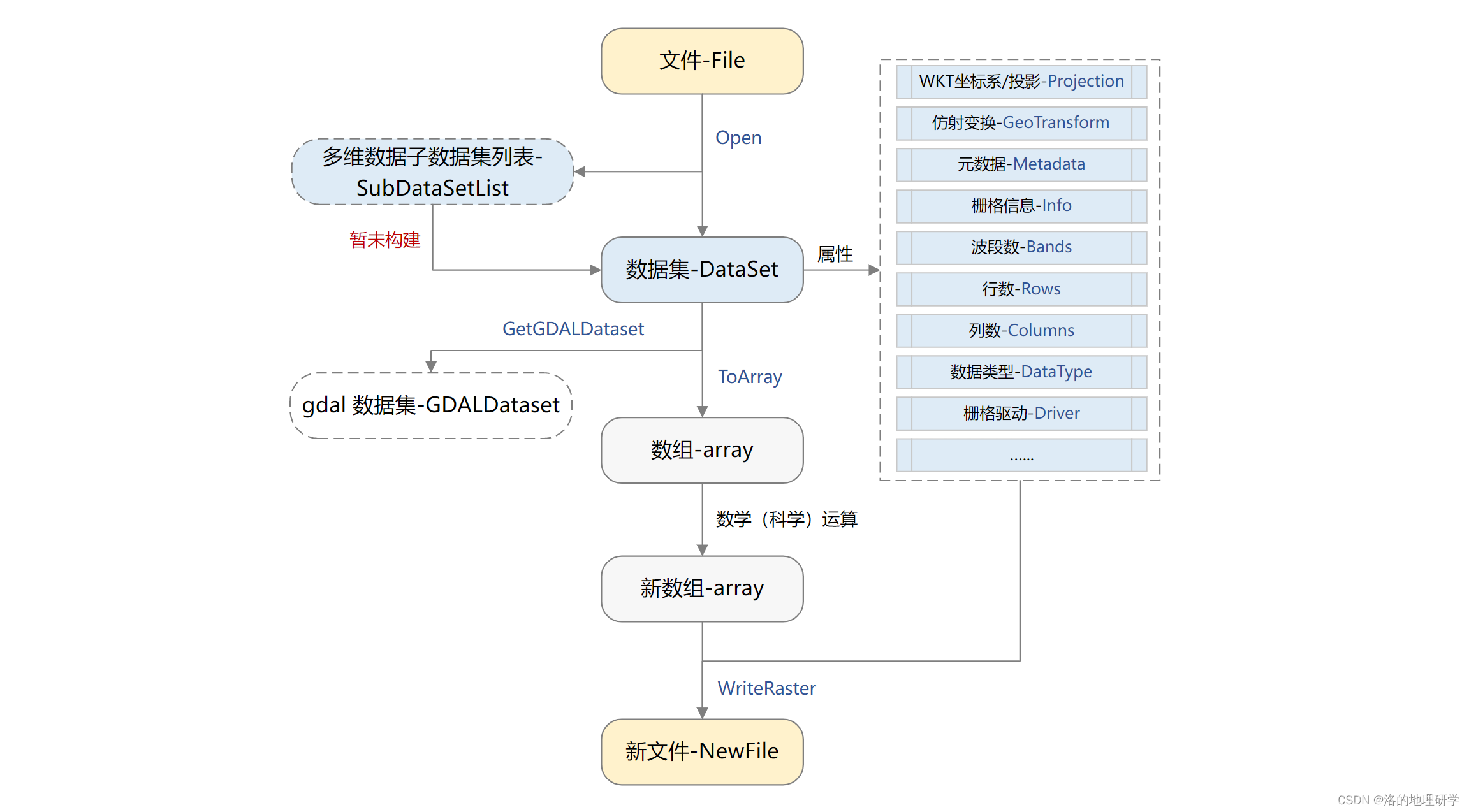
栅格运算
基于 整体思路,这里简单实现栅格运算 (以 GEBCO 2020 年海洋与陆地中国范围内地形 GTiff 格式数据为例)。
import gma
InFile = 'ELE_China_GEBCO_2020.tif'
打开文件
DataSet = gma.Open(InFile)
获取属性
为方便运算后结果生成 GTiff 时添加属性,这里记录一下原始数据属性。可获取的属性参考 Open:RasterOpen。
这里记录 坐标系/投影(Projection)、仿射变换(GeoTransform)、驱动格式(Driver)以及无数据标记值(NoData)。
Proj = DataSet.Projection
Geot = DataSet.GeoTransform
Driver = DataSet.Driver
NoData = DataSet.NoData
读取数据为数组
返回 array,方便结合 numpy、scipy、sklearn、pytorch 等其他库进行分析运算。
Data = DataSet.ToArray()
*简单归一化运算
这里对整个 array 进行一个简单的归一化运算,归一化方法如下:
N D D a t a = D a t a − D a t a m i n D a t a m a x − D a t a m i n NDData = \frac{Data - Data_{min}}{Data_{max} - Data_{min}} NDData=Datamax−DataminData−Datamin
# 记录有效数据位置
DLOC = Data != NoData DMax = Data[DLOC].max()
DMin = Data[DLOC].min()
NDData = (Data - DMin) / (DMax - DMin)# 将无数据区域重新标记为 NoData
NDData[Data == NoData] = NoData
若输入数据包含 NoData,则此处运算时一定要忽略 NoData。因为此值作为填充值,不为有效数据,仅作占位使用!
输出结果到新文件
gma.rasp.WriteRaster('./ELE_China_GEBCO_2020_ND.tif', NDData,Projection = Proj, Transform = Geot,Format = Driver,DataType = 'Float32', NoData = NoData )

反馈与学习
请联系:Luo_Suppe(微信号)。
这篇关于基于 gma 的栅格运算思路与应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




