本文主要是介绍不要头大!基于PostgreSQL的全文搜索干货!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于PostgreSQL的全文搜索
上周公司内部搞了一个极客擂台赛,leader给出的比赛的题目是PgSQL的全文搜索,想了想这个全文搜索还没弄过,挺感兴趣的,然后就报名了。记录了一下这周的研究成果。
直入正题
什么叫全文搜索?

wiki百科上的介绍,我理解了一下,全文搜索最核心的点就是“文档”的概念,pgsql的官方文档描述是这样的: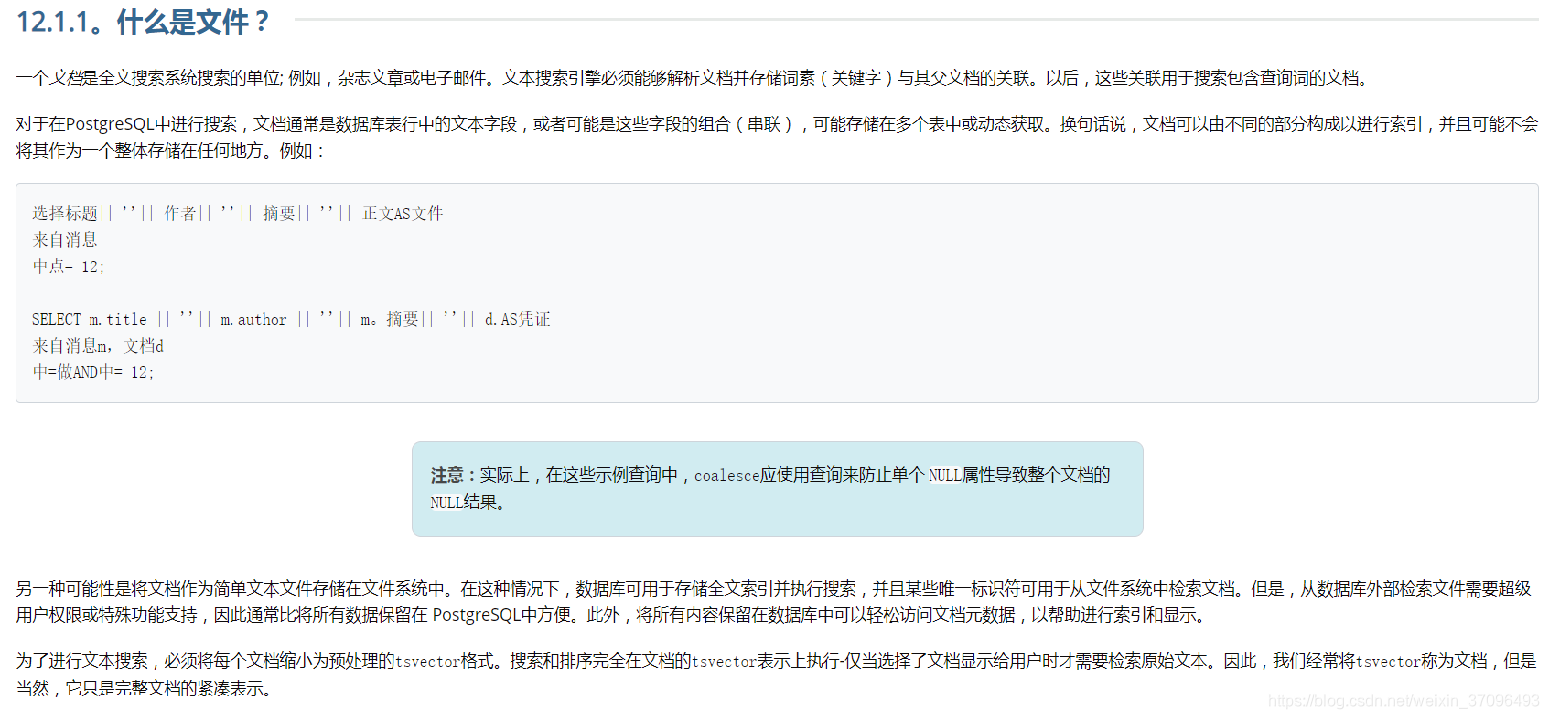 实际上,pgsql全文搜索的核心就是俩个函数:to_tsvector()和to_tsquery()
实际上,pgsql全文搜索的核心就是俩个函数:to_tsvector()和to_tsquery()
to_tsvector()是什么?我们上个sql解释一下
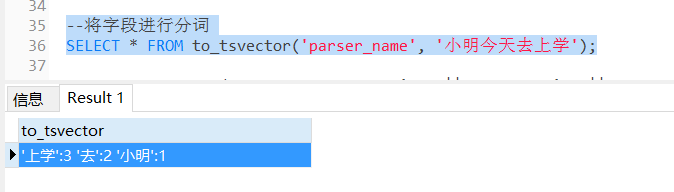 我们可以看到,to_tsvector实际上把语句转换成了tsvector(文档格式-包含文档值和角标),“上学”对应位置3,“小明”对应语句的位置1,我们记住这种格式就行,后续会用到。
我们可以看到,to_tsvector实际上把语句转换成了tsvector(文档格式-包含文档值和角标),“上学”对应位置3,“小明”对应语句的位置1,我们记住这种格式就行,后续会用到。
to_tsquery()我们也拿个sql解释一下:
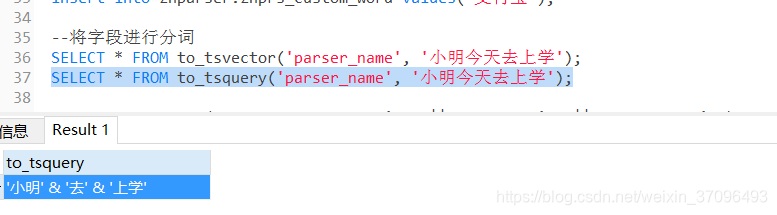 它实际上就是一个传递的参数格式,可以搭配中文分词规则,把一句话拆成多个词传递过去,这俩个函数一结合,就可以实现中文全文搜索了。
它实际上就是一个传递的参数格式,可以搭配中文分词规则,把一句话拆成多个词传递过去,这俩个函数一结合,就可以实现中文全文搜索了。
好了,开始撸全文搜索了
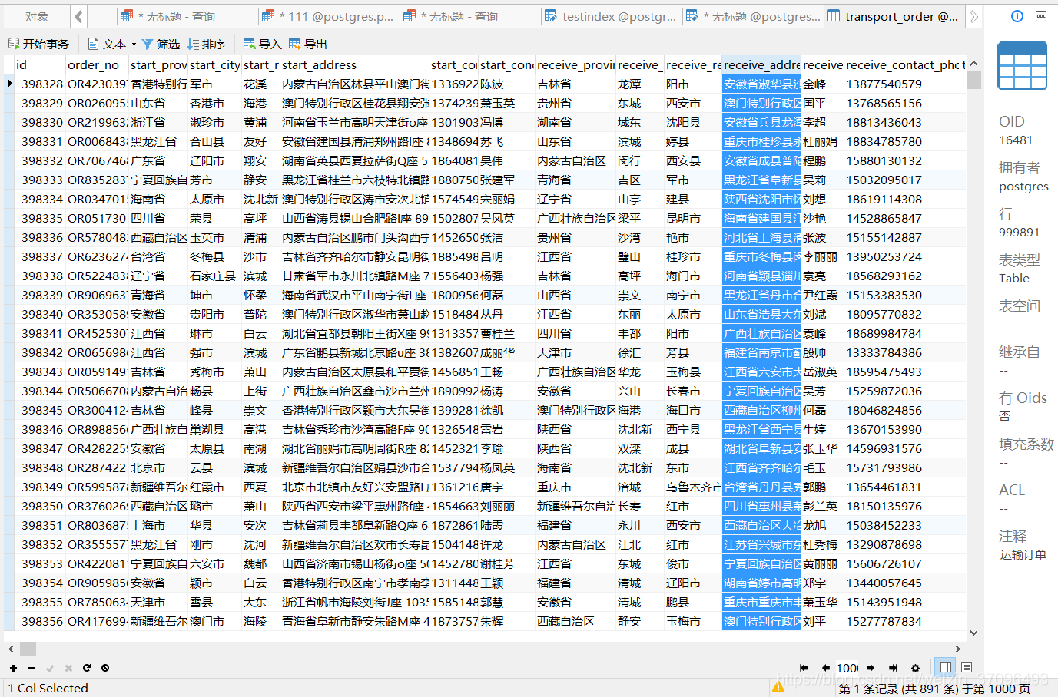 我们在这里弄了一个表,运输订单表,包括省市区-联系人-详细地址
我们在这里弄了一个表,运输订单表,包括省市区-联系人-详细地址
我们需要搜索起点地址信息和终点地址信息钟,包含"丹丹"这个关键字的记录。怎么搜?
传统做法是用like匹配,而且全模糊是用不到索引的。问题来了,pgsql是不支持中文分词的,怎么弄呢,这里废话不多说,我直接说我做的俩种方案:
1、在linux环境下,装zhparser插件,配合pgsql的函数实现全文搜索
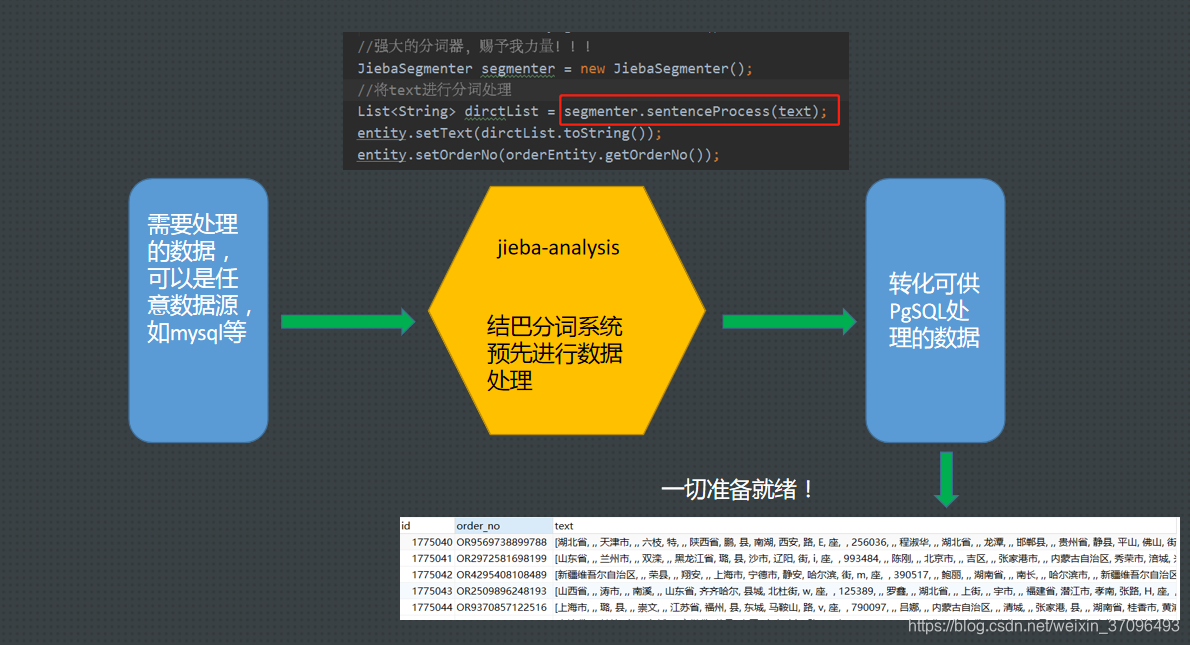
2、windows环境下,通过 jieba-analysis 【结巴分词java版】,通过搭建springboot项目搭建一个中文分词系统,通过这个第三方分词系统,进行分词转成pgsql能识别的格式,然后把数据导入到pgsql里面。
第一个方案,我看网上大多数都有教程了,就这么几步:
1、装scws字典
2、装zhparser插件
3、启动zhparser的extension
4、创建zhparser的分词规则
5、使用zhparser的规则创建gin索引
6、使用索引进行全文查询
我主要讲我第二个方案的骚操作。。。
 如图所示
如图所示
我这个方案是这样的,比如一个text字段的内容是:“南京市长江大桥”,在没装zhparser插件的时候,我直接在pgsql是处理不了的,我给这个text字段创建gin索引的时候(因为创建gin索引必须指定分词规则,这里就拿english做做样子了,english规则是根据符号和空格去分词):
create index search_idx on test_index using gin(to_tsvector(‘english’,text))
创完之后,他实际上是拿整个字段去存索引的,分不了词没有意义。
这里我先通过外部结巴分词系统,拉取数据进行处理,补一下结巴分词的git地址: ## https://github.com/huaban/jieba-analysis
通过结巴分词的JiebaSegmenter将这句话分词为“南京市"、"长江大桥”、"市长"三个词,然后再存到pgsql里面指定新增的一个列(专门用来存这种已经分好词的字符串)
然后就变成这个样子了:【这种数据格式,刚好也符合english规则】
 注意,这种格式是会被to_tsvector()函数给识别并成功分词的,效果如下
注意,这种格式是会被to_tsvector()函数给识别并成功分词的,效果如下
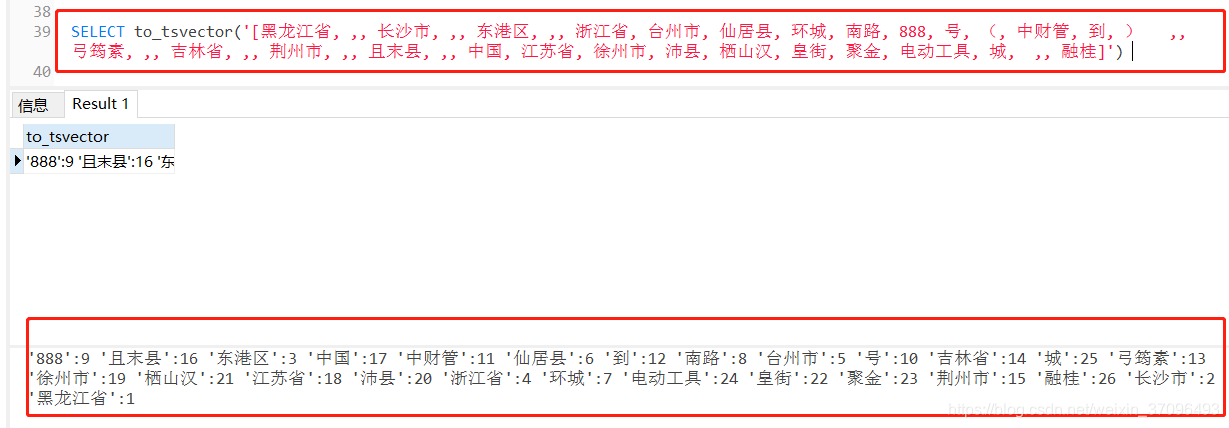 到这里,中文的全文搜索就已经实现了!
到这里,中文的全文搜索就已经实现了!
我们先不加索引,进行全文搜素试试
EXPLAIN ANALYZE SELECT * FROM test_index WHERE to_tsvector(text) @@ to_tsquery(‘丹丹’)
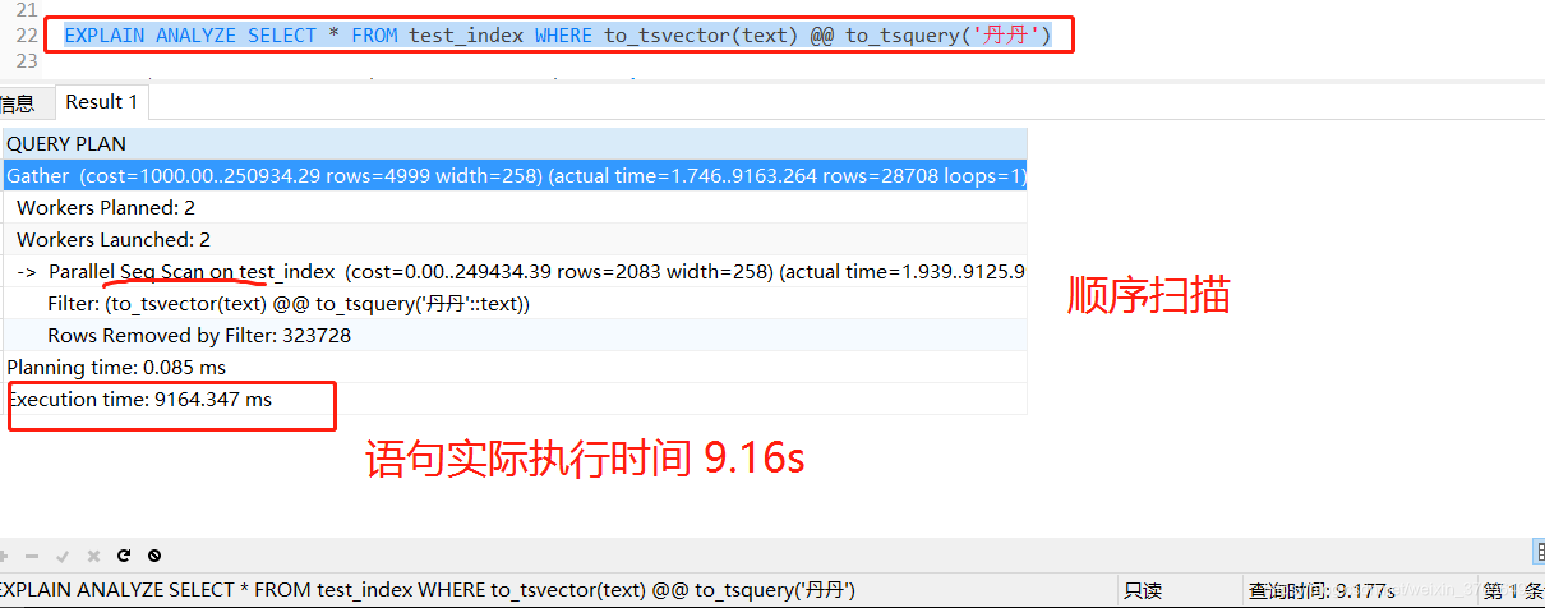 可以看到,不加索引的情况下,一百万的数据花了九秒多,究极慢!看来全文搜索还是挺耗性能的。
可以看到,不加索引的情况下,一百万的数据花了九秒多,究极慢!看来全文搜索还是挺耗性能的。
接下来我们给这个text字段创建gin索引来加速全文搜索:
create index 索引名 on 表名 using gin(to_tsvector(‘english’,text))
这里我们还是拿英文标准创索引,上文说了,其实我们现在这个格式符合english规则,它会根据空格和标点去分词。
这里创建索引的时候,我这边一百万的数据创建索引花了大概一分钟的时间
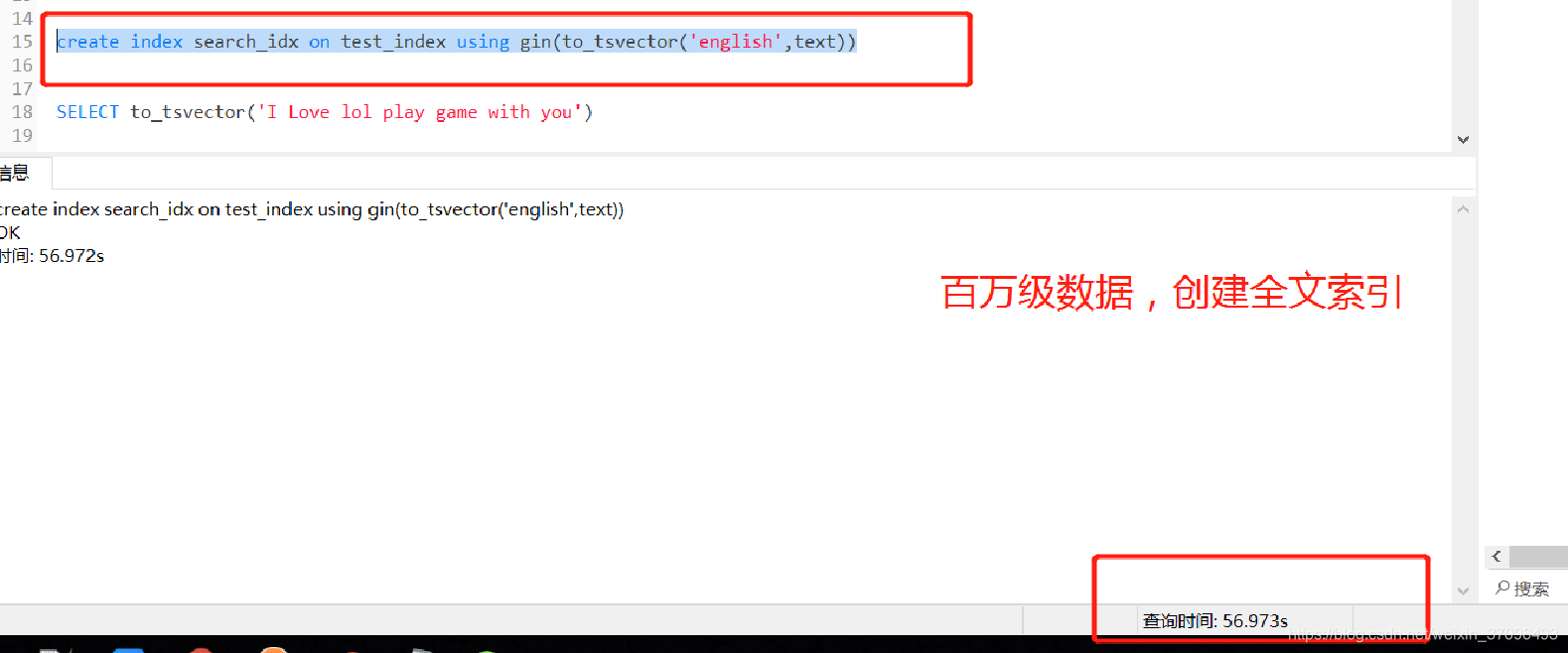 现在用索引搜索:
现在用索引搜索:
EXPLAIN ANALYZE SELECT * FROM test_index WHERE to_tsvector(‘english’,text) @@ to_tsquery(‘丹丹’)
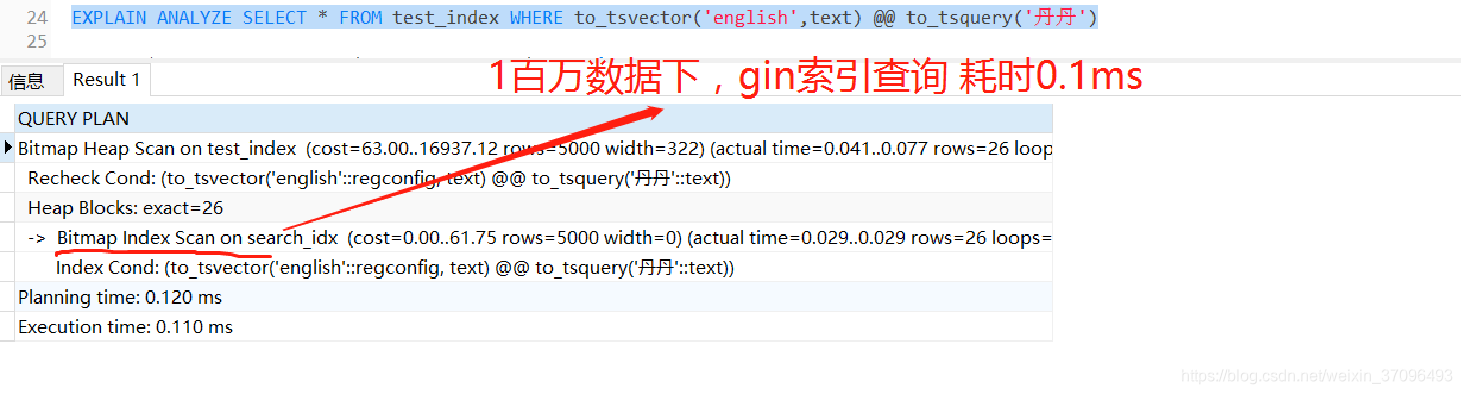 可以看到,加了gin索引之后,速度提升了n倍!
可以看到,加了gin索引之后,速度提升了n倍!
这里我要提一点,官方文档有说明:
 上面说的意思就是,你创建索引的时候用的什么分词规则,搜索的时候就要带上这个规则,否则索引会失效。比如用to_tsvector(‘english’,body)建立的索引,比如查询包含xxx的记录,查询的时候就要带上WHERE to_tsvector(‘english’,body) @@ xxx,如果不带上"english",如:WHERE to_tsvector(body) @@ xxx,这个时候索引是会失效的。
上面说的意思就是,你创建索引的时候用的什么分词规则,搜索的时候就要带上这个规则,否则索引会失效。比如用to_tsvector(‘english’,body)建立的索引,比如查询包含xxx的记录,查询的时候就要带上WHERE to_tsvector(‘english’,body) @@ xxx,如果不带上"english",如:WHERE to_tsvector(body) @@ xxx,这个时候索引是会失效的。
提一下这个规则是可以自定义的,比如中文规则,装完zhparser插件的话可以通过:
–添加配置,PARSER使用zhparser
CREATE TEXT SEARCH CONFIGURATION parser_name (PARSER = zhparser);
–设置分词规则 (n 名词 v 动词等,详情阅读下面的文档)
ALTER TEXT SEARCH CONFIGURATION parser_name ADD MAPPING FOR n,v,a,i,e,l,j WITH simple;
然后一个新的分词规则parser_name 就出来了,拿他创建索引
create index search_idx on testindex using gin(to_tsvector(‘parser_name’,txt))
然后后续步骤都一样。
最后讲一个中文搜索的缺点,也是最大的一个bug
比如:
 我text字段里面有一个“香港特别行政区”,我通过中文分词插件对这个字段创建gin索引
我text字段里面有一个“香港特别行政区”,我通过中文分词插件对这个字段创建gin索引
create index search_idx on testindex using gin(to_tsvector(‘parser_name’,txt))
建立完毕之后,开始全文搜索
 发现查不出来东西,结果一看,原来分词插件对“香港特别行政区”没有分词,还是原来的字,并没有把香港这个词单独拎出来
发现查不出来东西,结果一看,原来分词插件对“香港特别行政区”没有分词,还是原来的字,并没有把香港这个词单独拎出来
 导致查 香港 的时候查不出来,只能通过香港特别行政区去查才能查到。。
导致查 香港 的时候查不出来,只能通过香港特别行政区去查才能查到。。
 最后我们得出结论:中文分词的准确性问题会导致全文搜索的准确性问题
最后我们得出结论:中文分词的准确性问题会导致全文搜索的准确性问题
好了,到此,我对pgsql全文搜索的理解就讲完了,随心所想就写了,写的很乱不要见怪…
这篇关于不要头大!基于PostgreSQL的全文搜索干货!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






