本文主要是介绍小驴不开心要学java -- MySQL入门篇5,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言:这个章节的内容主要会介绍在使用SQL语句查询中的仅剩一些不多的查询方法,比如分组查询,子查询;还有在SQL语句中除了查询方法之外的DML数据操作语言,主要包括增加数据(insert)、删除数据(delete)、修改数据(update)。
今日的主题内容
分组函数
什么是分组函数?
分组函数是将数据集合中的数据按照某一个条件进行分组并可以得到一个结果,这个结果可以有一个共同的特点,比如部门编号是20的全体职员,那么分组的依据就是部门编号20。
分组函数有五个常用的函数:
- min 返回的是每组数据中的最小值;
- max 返回的是每组数据中的最大值;
- sum 返回的是每组数据的总和;
- avg 返回的是每组数据的平均值;
- count 返回的是每组数据中的满足条件的个数;
1. 分组函数 -- 将若干行数据 给出一个结果
2. 五个分组函数 求个数 最大值 最小值 求和 平均值
范例:
-- 场景:计算emp表中员工的个数 薪资的最大值最小值 平均值 和
SELECT count(sal), max(sal), min(sal), sum(sal), avg(sal) FROM emp ;
数据分组 group by
范例:
-- 场景:按照部门编号分组,查询出每一组中薪资最高的
-- tables? emp
-- columns? max(sal)
-- conditions? null
-- group by deptno
SELECT max(sal), deptno FROM emp GROUP BY deptno;
注意:在数据分组中,select中只能出现分组函数和group by后面的字段
也可以进行多列分组操作
范例:
-- 场景:查询出每个部门每个岗位的工资总和
-- 既需要按照部门分组也需要按照岗位分组
SELECT sum(sal), deptno, job FROM emp GROUP BY deptno, job;

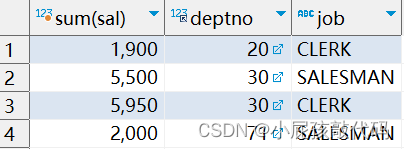
练习
1. 查询出部门20的员工,每个月的工资总和及平均工资。
2. 查询工作在CHICAGO的员工人数,最高工资及最低工资。
3. 查询员工表中一共几种岗位类型。
4. 查询每个部门的部门编号,部门名称,部门人数,最高工资,最低工资,工资总和,平均工资。
5. 查询每个部门,每个岗位的部门编号,部门名称,岗位名称,部门人数,最高薪资,最低薪资,薪资总和,平均薪资。子查询
子查询可以在哪里使用、出现?
- 可以在where中出现
- 可以在having中出现
- 可以在from中出现 子查询的结果可以当成是一个虚拟的表使用
- 可以在select中出现
为什么要使用子查询?
有时候在查询一个指定的数据的时候所给的条件并不是单一的,而是需要多个嵌套条件,单个查询语句没有办法达到获取到指定的数据的目的,所以就需要使用子查询来限定条件达到获取到目标数据。
子查询
范例1:
-- 场景:查询出比20部门的平均工资要高的员工的信息
-- tables? emp
-- columns? 所有信息
-- conditions? 比20部门的平均工资高
-- 20部门的平均工资 不在表中,需要自己计算
SELECT FROM emp WHERE sal > ?如何查询20部门的平均工资?
SELECT avg(sal) FROM emp WHERE deptno = 20;这样来看,单个的查询语句完成不了,需要多个查询语句组合完成 --> 子查询
SELECT empno, ename, sal, job, mgr, hiredate, comm, deptno FROM emp WHERE sal > (SELECT avg(sal) FROM emp WHERE deptno = 20);
如果在from 后面使用子查询,需要给子查询一个表别名,如果子查询的字段中出现函数/关键字 给列别名
SELECT e.empno, e.ename, e.sal, e.job, e.mgr, e.hiredate, e.comm, e.deptno FROM emp e, (SELECT deptno, avg(sal) AS deptsal -- 字段的别名 FROM emp GROUP BY deptno) salAVG -- 表别名 WHERE e.deptno = salAVG.deptno AND e.sal > salAVG.deptsal;
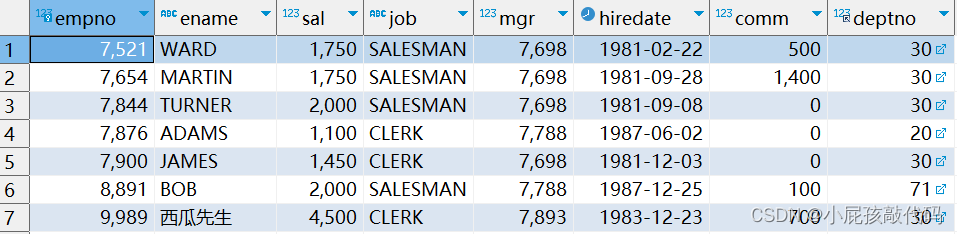

注意:子查询中的运算符
- 所有的where子句/having使用的子查询都必须给出的是一列的结果,子查询的select中只能有一个列名;
- 如果使用的是 > < = <> != >= <= 子查询中只能给出一个结果(一列一行);
- 如果子查询返回的是一列多行的结果,不能使用上述符号了,可以使用 多行运算符(in any all);
- from select中的子查询 没有列数的要求 关键字需要起别名;
练习:
1. 查询出比工作地点在芝加哥的部门中平均薪资要低的非部门的员工的信息。
2. 查询出比自己经理的薪资一半还低的员工的信息。
3. 查询出比7788入职时间更晚的非他对应部门的员工信息。
4. 查询当前部门入职日期最早的员工姓名,入职日期。
5. 查询工资比smith工资高并且工作地点在CHICAGO的员工姓名,工资,部门名称。合并查询
union 直接将两个查询的结果合并 并去除重复的数据;
union all 直接将两个查询结果合并 但是不进行去重的操作;
范例:
-- 查询出有奖金的人的信息和薪资大于两千的信息
SELECT * FROM emp WHERE comm IS NOT NULL UNION -- UNION ALL SELECT * FROM emp WHERE sal > 1500;
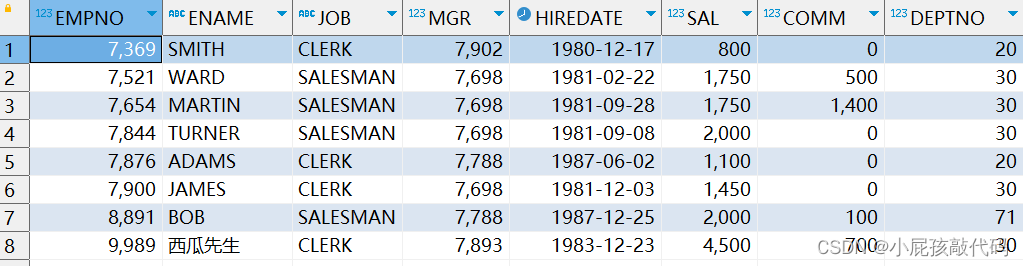
让人恼火的查询语句终于到此结束了
不要问为什么会让人恼火
只有你学过才知道

DML 数据操作语言
主要包括以下几种:
- 增加行数据:使用insert语句实现
- 修改行数据:使用update语句实现
- 删除行数据:使用delete语句实现
增加数据 insert语句
基本结构:
insert into 表名 values(值列表);
范例1:
-- 场景:向dept中添加一个新的部门
-- 部门编号:50
-- 部门名称:development
-- 部门地址:DEPROIT
INSERT INTO dept values(50, 'development', 'DEPROIT');注意:使用这种方式添加数据的时候,注意values小括号中的值的顺序必须和dept表中的字段顺序一致。
范例2:
-- 也可以在表名后面增加字段列表,这样values后面的值的顺序只要和字段列表的顺序一致即可
INSERT INTO dept(deptno, loc, dname) values(60, 'LA', 'TEST');注意:在进行添加数据的时候,不要违反约束的规定 主键唯一不重复
当然,添加数据除了逐句的添加,还可以批量添加 (重点)
第一种方式:增加若干个值列表
INSERT INTO dept(dname, loc) VALUES('人事', '上海'), ('财务', '广州'), ('销售', '北京');第二种方式:使用子查询的方式
INSERT INTO stuff(id, dname, loc) SELECT deptno, dname, ifnull(loc, '上海') FROM dept ;
数据的修改 update语句
基本结构:
UPDATE 表名 set 列名=值,列名=值... where condition;
范例1:
-- 修改 财务部门的地址
UPDATE dept SET loc = '南京' WHERE dname = '财务';注意:如果不添加where子句,会修改整张表的该字段的值。
删除数据 delete语句
基本结构:
DELETE FROM 表名 WHERE condition;
范例:
-- 场景:删除emp表中员工编号是8888。
DELETE FROM emp WHERE empno = 8888;注意:
- 如果没有where子句,删除的是整张表的数据。
- 删除操作的时候也不能违法完整性约束 外键约束
-- SQL 错误 [1451] [23000]: Cannot delete or update a parent row: a foreign key constraint fails (`mysqldb`.`emp`, CONSTRAINT `FK_DEPTNO` FOREIGN KEY (`DEPTNO`) REFERENCES `dept` (`DEPTNO`))
总结:历经五篇的文章,终于将SQL语句大部分(内容过多,也有一部分没有记录,只记录了必须要熟记掌握的内容)记录完毕,实在可喜可贺。喜欢内容的伙伴们可以点个赞,鼓个掌,谢谢(>_<)
最后,如果以上几篇文章内容出现错误或者有描述不清楚的地方,欢迎各位大大们评论区留言或者私信我。练习题需要答案的小伙伴也可以直接私信我,博主将在看到消息的第一时间回复。
下一章内容(今晚更新):JDBC的相关内容。
这篇关于小驴不开心要学java -- MySQL入门篇5的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







