本文主要是介绍HarmonyOS原生分析能力,即开即用助力精细化运营,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据分析产品对开发者的价值呈现在两个层面,第一个是产品的层面,可以通过数据去洞察用户的行为,从而找到产品的优化点。另外一个就是运营层面,可以基于数据去驱动,来实现私域和公域的精细化运营。
在鸿蒙生态上,华为会融合多端多源数据,包括HarmonyOS的系统级数据、华为自有的应用数据以及华为用户画像数据和应用内的数据,借助于这些多源的数据融合,构建用户全生命周期的分析能力,帮助实现精细化的运营和产品的优化,从而实现用户的增长。
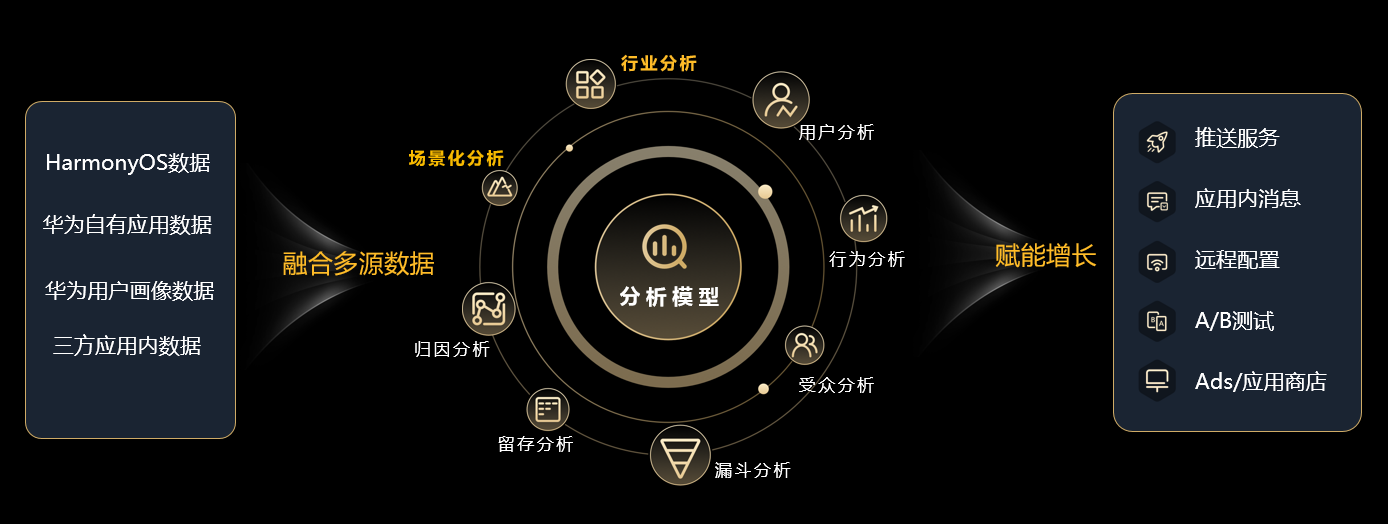
未来,华为分析服务也会给开发者提供新的接入的体验,开通即用、免SDK集成。原先,开发者看到基础的运营指标,需要经历以下步骤:开通服务、配置SDK、集成SDK、写代码、初始化等。经过新的升级,开发者只需要开通服务,就可以看到基础的运营报表。
同时,华为将提供系统级的采集API,把数据的采集和上报的能力做到底层化。这样应用的包体不会增加,应用也无需要随着SDK的升级重新去打包、发布、上架,不会受到用户升级的影响,真正做到无感升级。在埋点这块,将24个API,减少到8个API,降低开发者埋点的复杂度。

在鸿蒙生态上华为融合HarmonyOS的数据,由应用内的分析向外拓展特色场景化分析,在原有分析能力的基础上新增了一些关键的场景化的分析能力,包含来源分析、加桌分析、分享裂变、流失分析等,做到不丢失用户旅程中每一个关键的分析。

场景
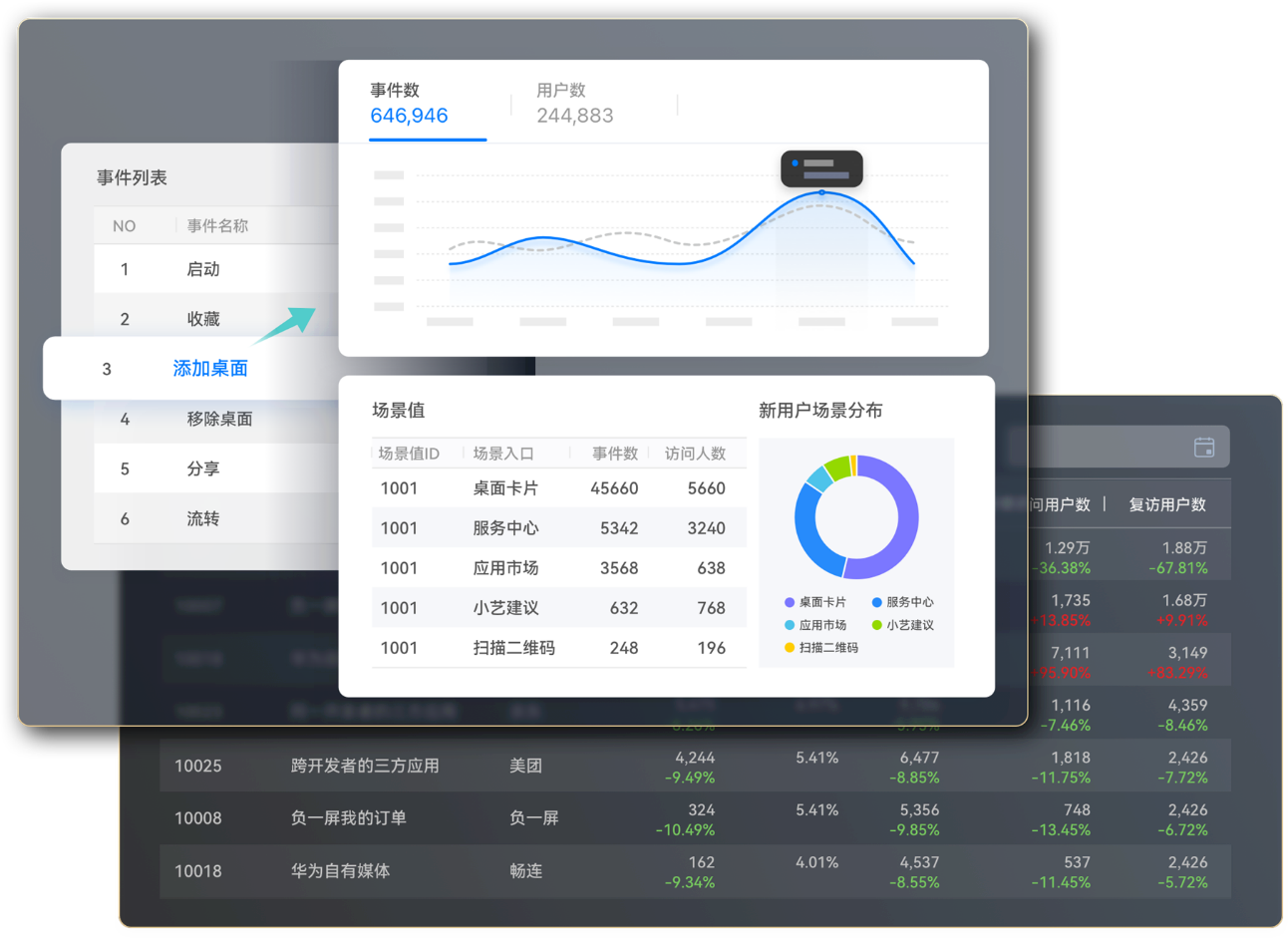
1. 用户来源场景
以前的分析能力不知道用户进入应用的路径,在鸿蒙生态下,华为会构建一个元服务的场景值ID,这个场景值就是描述用户进入元服务的路径,可以根据场景值去分析不同场景下的新增用户、活跃用户以及付费用户,从而优化引流的策略。
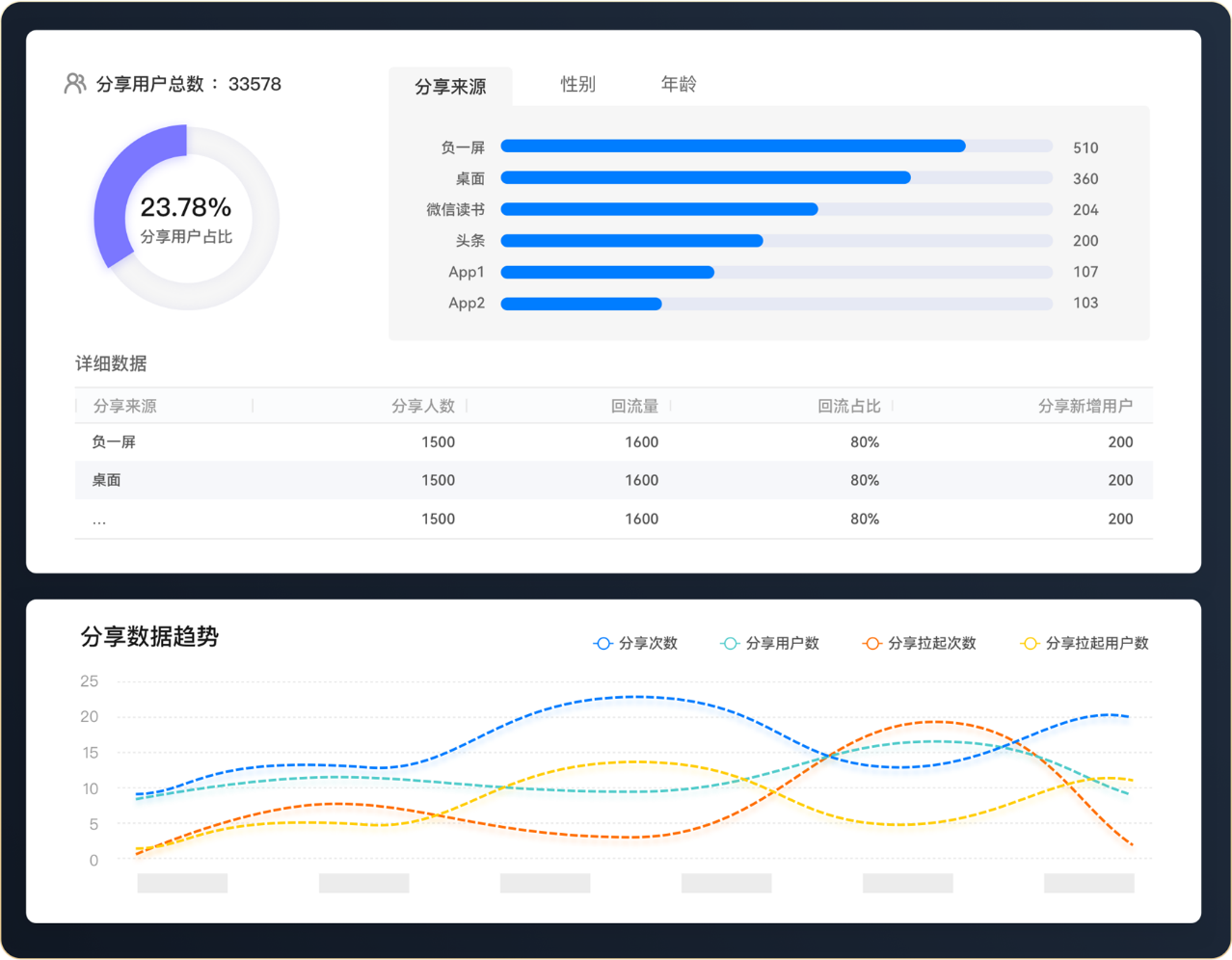
2. 分享场景
元服务具备免安装、即用即走、易于分享的轻量化特征,未来元服务的分享是拉新、促活和促转化的一个重要的渠道,若想提升传播效果,要借助于背后的数据洞察。华为分享的场景分析,提供了分享的次数、分享用户数、分享拉起的次数和分享拉起的用户数等能力,开发者可以根据分享的不同的内容、方式查看分享的效果,从而提升元服务的传播效果。
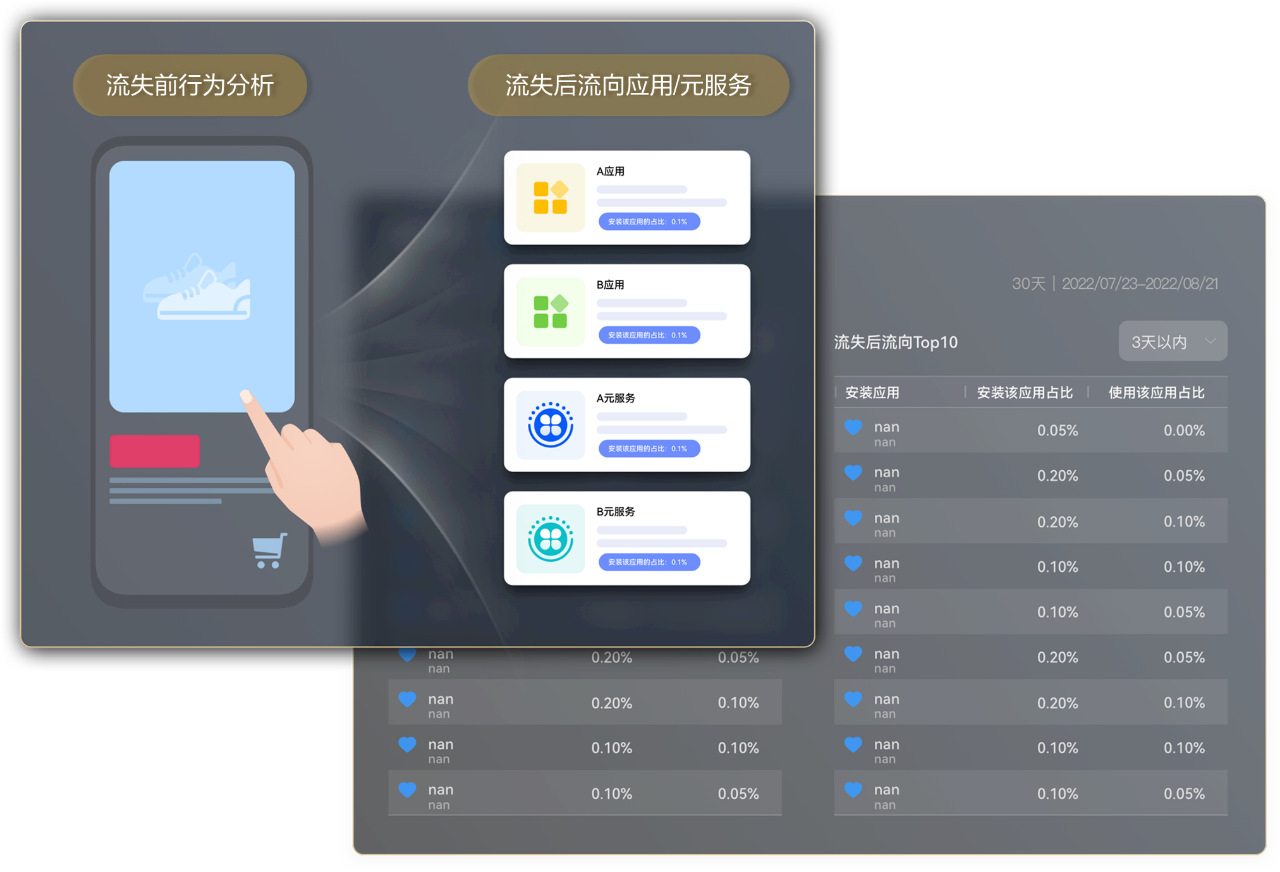
3. 流失场景
开发者在运营过程中,不仅要关注新增和活跃的情况,同时还要了解用户的流失趋势,考虑流失背后的原因。所以华为在鸿蒙生态下面提供了元服务移除桌面以及应用卸载的统计数据,可以分析用户流失前的行为,以及用户流失前后的流向是什么样的。借助于流失前的行为分析,就可以洞察是否是用户在应用内的某个触点,形成了用户流失的导火索。借助于流失的流向,可以分析用户在流失前后,流向了哪些同类型的应用或者元服务,结合这些分析我们可以洞察用户流失背后的原因。
合作案例
孩子王是华为优秀的合作伙伴之一,孩子王完成元服务的开发后,基于一些关键的核心指标去调整了运营策略,上线一个月,用户的规模已经达到了万级。

在新的生态下,华为分析服务也已经开启了新的征程,希望更多的开发者能够加入进来,一起碰撞出更多的火花,帮助构建更好的产品,为大家提供更好的服务。
了解更多详情>>
访问华为分析服务联盟官网
获取华为分析服务开发指导文档
这篇关于HarmonyOS原生分析能力,即开即用助力精细化运营的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







