本文主要是介绍python、talib选股:自动工具介绍以及倒锤头形态搜索并可视化显示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1 前言
2 工具介绍
1.1 界面
3 测试搜索倒锤头形态
1 前言
本来想研究金融,可是看到代码就烦,难道还要特意去学习python编程?那样岂不浪费好多发cai的时间?估计很多股友跟我的经历很相似。想从网上找个好的python工具,但是在网上找来找去都没找到特别中意的,全都是一堆代码,没法直接拿来主义。没办法还是边学习编程边炒gu养家吧。
2 工具介绍
这个工具的特点是,一是不用安装,直接运行;二是后台集成了python,功能强大;三是扩展性强,后面需要什么功能模块直接安装就行;四是不用敲代码,一行代码都不用敲,点几下鼠标就出结果了;五是后面会不断扩充功能,因为我要用它炒gu挣钱养家糊口,功能不强大不行;六是增加了功能我会马上发布新程序来。股友们拿来主义随便用;七是。。。。。。
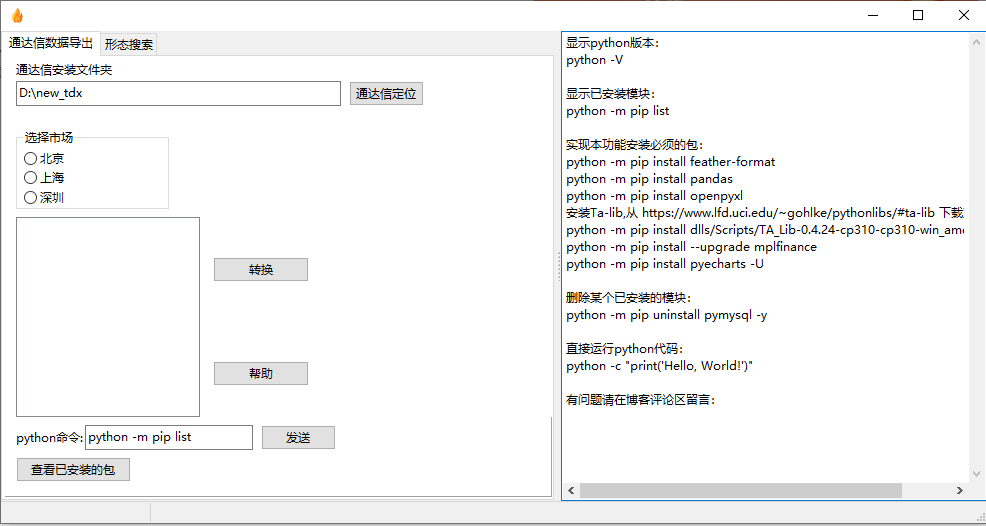
1.1 界面
刚开始界面有点简陋啊,将就吧。
3 测试搜索倒锤头形态
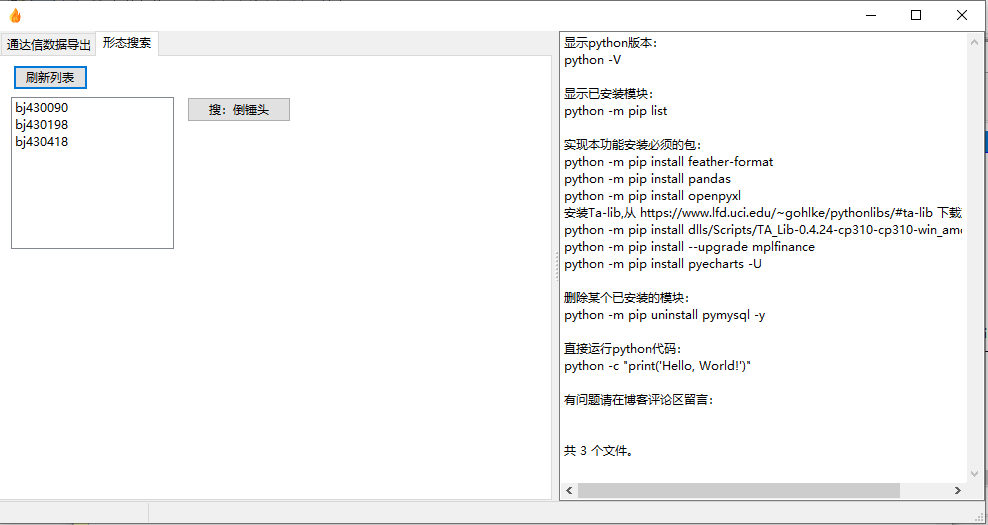
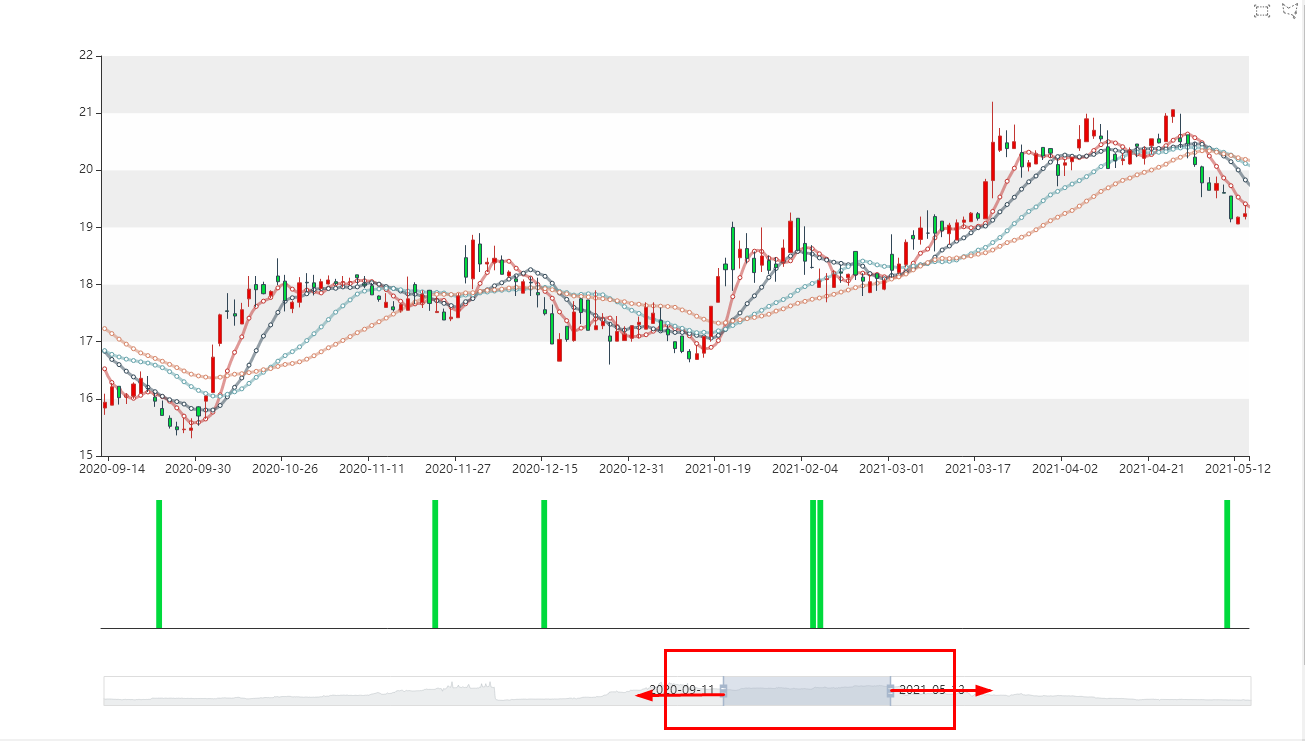
选中一个已经导出的代码,然后点击“搜:倒锤头”,几秒钟后浏览器显示结果。下面的滑块可以左右平移、放大缩小。
记录一下实际使用的python代码:
from typing import List, Union
import talib
from pyecharts import options as opts
from pyecharts.charts import Kline, Line, Bar, Grid
import os
import pandas as pd'''
def net_split_data(data):category_data = []values = []volumes = []for i, tick in enumerate(data):category_data.append(tick[0])values.append(tick)volumes.append([i, tick[4], 1 if tick[1] > tick[2] else -1])return {"categoryData": category_data, "values": values, "volumes": volumes}def net_get_data():response = requests.get(url="https://echarts.apache.org/examples/data/asset/data/stock-DJI.json")json_response = response.json()# 解析数据return net_split_data(data=json_response)
'''def split_data(data):category_data = []values = []volumes = []# flags = []for i, tick in enumerate(data.values.tolist()):category_data.append(tick[0])values.append(tick)volumes.append([i, tick[5], 1 if tick[1] > tick[2] else -1])# flags.append([i, 0])open_p = pd.DataFrame(values)[1]close_p = pd.DataFrame(values)[2]low_p = pd.DataFrame(values)[3]high_p = pd.DataFrame(values)[4]array_cdl2c = talib.CDLINVERTEDHAMMER(open_p, high_p, low_p, close_p) # 倒锤头# l_array_cdl2c = array_cdl2c.values.tolist()# 由于不知道如何在k线图中叠加标记,使用这种变通方法,即替换成交量图中# 的成交量为乌鸦标记# 即:用 array_cdl2c 的值替换 df_volumes 中的成交量# 列表转化为DataFrame方便列操作df_volumes = pd.DataFrame(volumes)df_volumes[1] = array_cdl2cdf_volumes[2] = 1 # 2只乌鸦标志颜色统一设置为绿色volumes = df_volumes.values.tolist()return {"categoryData": category_data, "values": values, "volumes": volumes}def get_data(code):# df_tdx = pd.read_feather(r'./dataout/tdx/'+code+r'.day.feather')# df_tdx.index=pd.to_datetime(df_tdx.Date, format = '%Y%m%d')# df_tdx_b=df_tdx.truncate(before=start_date, after = end_date)# df_tdx_b['Openinterest']=0# df_tdx_b.rename(columns={'vol':'volume'}, inplace = True)# df_tdx_b=df_tdx_b[['Open','High','Low','Close','Volume','Openinterest']]# return split_data(data=df_tdx_b)df_tdx = pd.read_feather(r'./data/tdx/'+code+r'.day.feather')df_tdx.drop('Amout', axis=1, inplace=True)df_tdx.Date=pd.to_datetime(df_tdx.Date, format = '%Y%m%d')df_tdx.Date=df_tdx.Date.map(lambda x:x.strftime('%Y-%m-%d'))# df_tdx.index=pd.to_datetime(df_tdx.Date, format = '%Y%m%d')# 调整列顺序df_tdx = df_tdx.loc[:,['Date', 'Open', 'Close', 'Low', 'High', 'Volume']]# df_tdx_b=df_tdx.truncate(before=start, after = end)# df_tdx_b['Openinterest']=0# df_tdx.rename(columns={'vol':'Volume'}, inplace = True)# df_tdx_b=df_tdx_b[['Open','High','Low','Close','Volume','Openinterest']]return split_data(data=df_tdx)def calculate_ma(day_count: int, data):result: List[Union[float, str]] = []for i in range(len(data["values"])):if i < day_count:result.append("-")continuesum_total = 0.0for j in range(day_count):sum_total += float(data["values"][i - j][1])result.append(abs(float("%.3f" % (sum_total / day_count))))return resultdef draw_charts():kline_data = [data[1:-1] for data in chart_data["values"]]kline = (Kline().add_xaxis(xaxis_data=chart_data["categoryData"]).add_yaxis(series_name="stock index",y_axis=kline_data,itemstyle_opts=opts.ItemStyleOpts(color="#ec0000", color0="#00da3c"),).set_global_opts(legend_opts=opts.LegendOpts(is_show=False, pos_bottom=10, pos_left="center"),datazoom_opts=[opts.DataZoomOpts(is_show=False,type_="inside",xaxis_index=[0, 1],range_start=98,range_end=100,),opts.DataZoomOpts(is_show=True,xaxis_index=[0, 1],type_="slider",pos_top="85%",range_start=98,range_end=100,),],yaxis_opts=opts.AxisOpts(is_scale=True,splitarea_opts=opts.SplitAreaOpts(is_show=True, areastyle_opts=opts.AreaStyleOpts(opacity=1)),),tooltip_opts=opts.TooltipOpts(trigger="axis",axis_pointer_type="cross",background_color="rgba(245, 245, 245, 0.8)",border_width=1,border_color="#ccc",textstyle_opts=opts.TextStyleOpts(color="#000"),),visualmap_opts=opts.VisualMapOpts(is_show=False,dimension=2,series_index=5,is_piecewise=True,pieces=[{"value": 1, "color": "#00da3c"},{"value": -1, "color": "#ec0000"},],),axispointer_opts=opts.AxisPointerOpts(is_show=True,link=[{"xAxisIndex": "all"}],label=opts.LabelOpts(background_color="#777"),),brush_opts=opts.BrushOpts(x_axis_index="all",brush_link="all",out_of_brush={"colorAlpha": 0.1},brush_type="lineX",),))line = (Line().add_xaxis(xaxis_data=chart_data["categoryData"]).add_yaxis(series_name="MA5",y_axis=calculate_ma(day_count=5, data=chart_data),is_smooth=True,is_hover_animation=False,linestyle_opts=opts.LineStyleOpts(width=3, opacity=0.5),label_opts=opts.LabelOpts(is_show=False),).add_yaxis(series_name="MA10",y_axis=calculate_ma(day_count=10, data=chart_data),is_smooth=True,is_hover_animation=False,linestyle_opts=opts.LineStyleOpts(width=3, opacity=0.5),label_opts=opts.LabelOpts(is_show=False),).add_yaxis(series_name="MA20",y_axis=calculate_ma(day_count=20, data=chart_data),is_smooth=True,is_hover_animation=False,linestyle_opts=opts.LineStyleOpts(width=3, opacity=0.5),label_opts=opts.LabelOpts(is_show=False),).add_yaxis(series_name="MA30",y_axis=calculate_ma(day_count=30, data=chart_data),is_smooth=True,is_hover_animation=False,linestyle_opts=opts.LineStyleOpts(width=3, opacity=0.5),label_opts=opts.LabelOpts(is_show=False),).set_global_opts(xaxis_opts=opts.AxisOpts(type_="category")))bar = (Bar().add_xaxis(xaxis_data=chart_data["categoryData"]).add_yaxis(series_name="Volume",y_axis=chart_data["volumes"],xaxis_index=1,yaxis_index=1,label_opts=opts.LabelOpts(is_show=False),).set_global_opts(xaxis_opts=opts.AxisOpts(type_="category",is_scale=True,grid_index=1,boundary_gap=False,axisline_opts=opts.AxisLineOpts(is_on_zero=False),axistick_opts=opts.AxisTickOpts(is_show=False),splitline_opts=opts.SplitLineOpts(is_show=False),axislabel_opts=opts.LabelOpts(is_show=False),split_number=20,min_="dataMin",max_="dataMax",),yaxis_opts=opts.AxisOpts(grid_index=1,is_scale=True,split_number=2,axislabel_opts=opts.LabelOpts(is_show=False),axisline_opts=opts.AxisLineOpts(is_show=False),axistick_opts=opts.AxisTickOpts(is_show=False),splitline_opts=opts.SplitLineOpts(is_show=False),),legend_opts=opts.LegendOpts(is_show=False),))# Kline And Lineoverlap_kline_line = kline.overlap(line)# Grid Overlap + Bargrid_chart = Grid(init_opts=opts.InitOpts(width="1400px",height="800px",animation_opts=opts.AnimationOpts(animation=False),))grid_chart.add(overlap_kline_line,grid_opts=opts.GridOpts(pos_left="10%", pos_right="8%", height="50%"),)grid_chart.add(bar,grid_opts=opts.GridOpts(pos_left="10%", pos_right="8%", pos_top="63%", height="16%"),)grid_chart.render("render.html")# 打开网页os.system("render.html")if __name__ == "__main__":'''df_tdx = pd.read_feather(r'./dataout/tdx/bj871396.day.feather')df_tdx.drop('Amout', axis=1, inplace=True)df_tdx.Date=pd.to_datetime(df_tdx.Date, format = '%Y%m%d')df_tdx.Date=df_tdx.Date.map(lambda x:x.strftime('%Y-%m-%d'))# df_tdx.index=pd.to_datetime(df_tdx.Date, format = '%Y%m%d')# df_tdx.Date = df_tdx.astype({'Date':'str'})# df_tdx.Date = df_tdx.Date.map(lamda x:)# df_tdx.rename(columns={'vol':'Volume'}, inplace = True)# df_tdx_b=df_tdx_b[['Open','High','Low','Close','Volume','Openinterest']]# print(df_tdx.dtypes)# print(list(df_tdx))df_tdx = df_tdx.loc[:,['Date', 'Open', 'Close', 'Low', 'High', 'Volume']]# print(list(df_tdx))d_category_data = []d_values = []d_volumes = []# d_flags = []for i, tick in enumerate(df_tdx.values.tolist()):d_category_data.append(tick[0])d_values.append(tick)d_volumes.append([i, tick[5], 1 if tick[1] > tick[2] else -1])# d_flags.append([i, 0])open_p = pd.DataFrame(d_values)[1]close_p = pd.DataFrame(d_values)[2]low_p = pd.DataFrame(d_values)[3]high_p = pd.DataFrame(d_values)[4]array_cdl2c = talib.CDLINVERTEDHAMMER(open_p, high_p, low_p, close_p)# array_cdl2c 与 d_volumes合并,# 然后用 array_cdl2c 的之替换 df_volumes 中的成交量# 列表转化为DataFrame方便列操作df_volumes = pd.DataFrame(d_volumes)df_volumes[1] = array_cdl2c# l_array_cdl2c = array_cdl2c.values.tolist()''''''response = requests.get(url="https://echarts.apache.org/examples/data/asset/data/stock-DJI.json")json_response = response.json()# 解析数据category_data = []values = []volumes = []for i, tick in enumerate(json_response):category_data.append(tick[0])values.append(tick)volumes.append([i, tick[4], 1 if tick[1] > tick[2] else -1])# return {"categoryData": category_data, "values": values, "volumes": volumes}'''# net_chart_data = net_get_data()chart_data = get_data('bj430198')# chart_data = net_get_data()draw_charts()
程序有点大,近90M:
![]()
谁想用用试试程序就在评论区留下邮箱吧,我直接发你邮箱。
有什么建议请在评论区留言,不接受其他交流方式,有合适的建议我就加到程序里。
这篇关于python、talib选股:自动工具介绍以及倒锤头形态搜索并可视化显示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




