本文主要是介绍精美图片哪里找,保姆级教程爬取让你不再犹豫!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python爬虫:基于Scrapy爬取某牙星秀主播图片
- 一、项目准备
- 二、网页及代码分析
- 三、完整代码
一、项目准备
创建scrapy项目
scrapy startproject Huyacd Huya scrapy genspider huya "huya.com"
更改settings文件


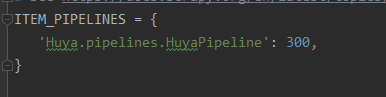
配置图片下载路径

创建start.py启动py文件
from scrapy import cmdlinecmdline.execute("scrapy crawl huya".split())
二、网页及代码分析
1.网页分析
进入虎牙星秀区域
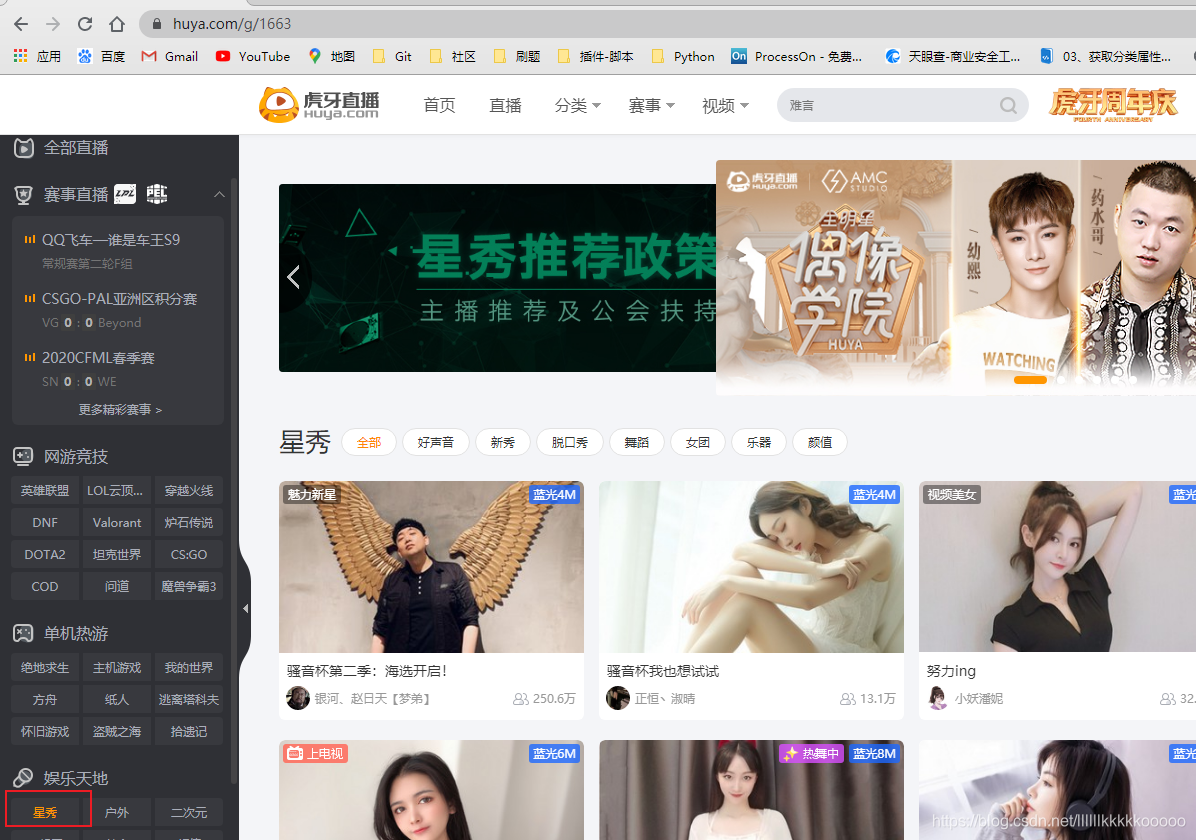
通过分析发现数据并不是动态加载的,来到第二页,发现下图Request URL请求得到json数据
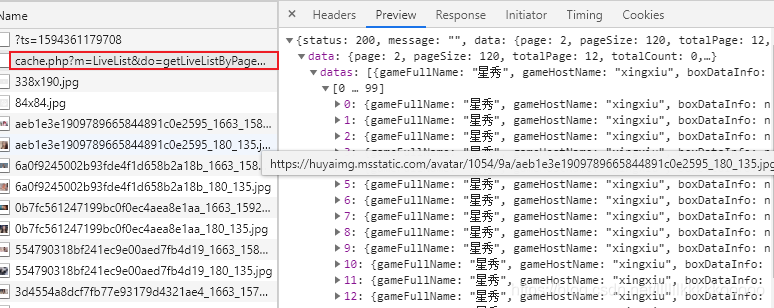
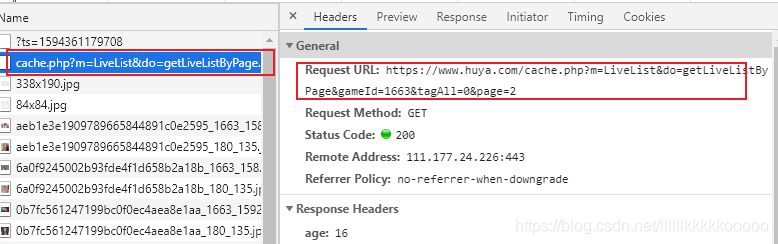
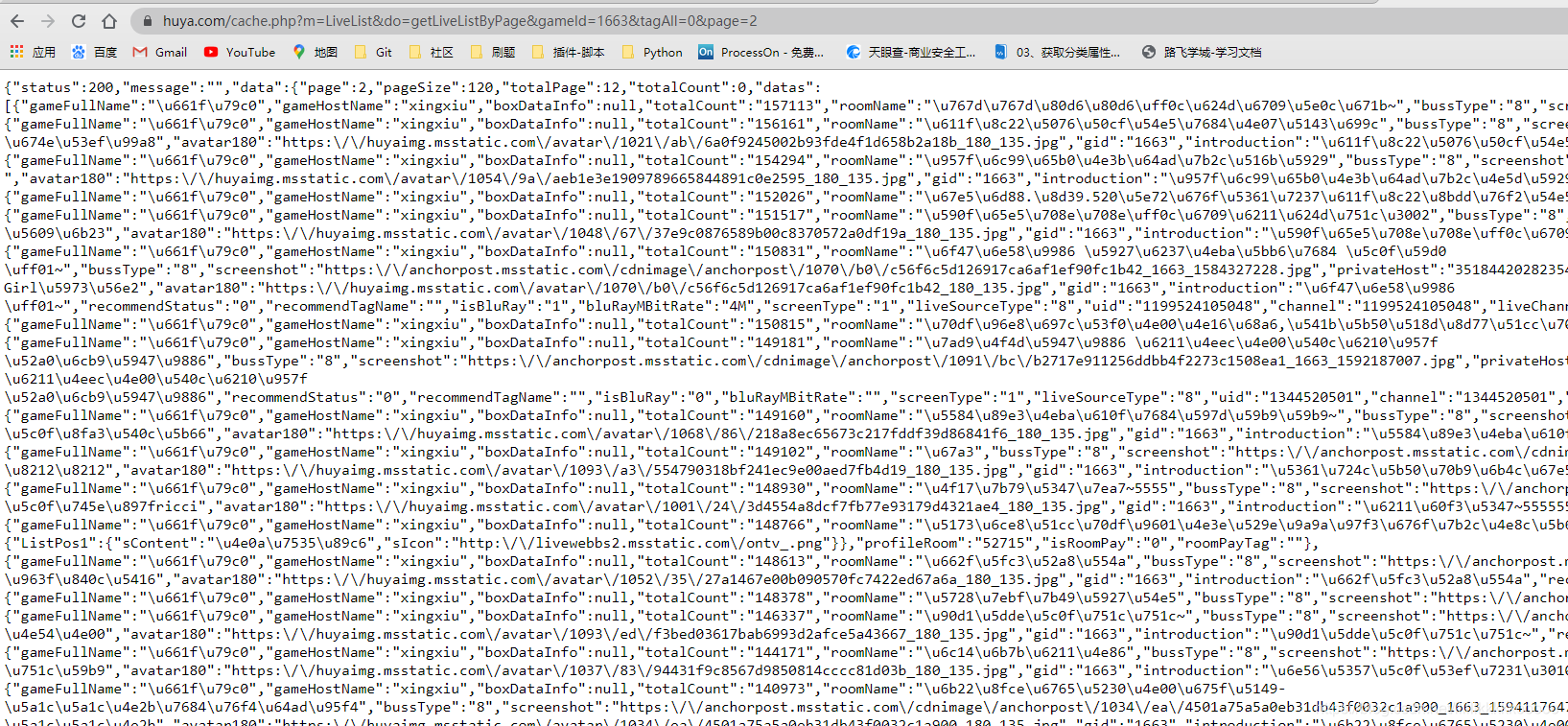
我们请求该链接,发现数据为Unicode编码,看到这不要慌,之后可以很轻易地解决。
复制json数据到在线json校验工具进行校验转码
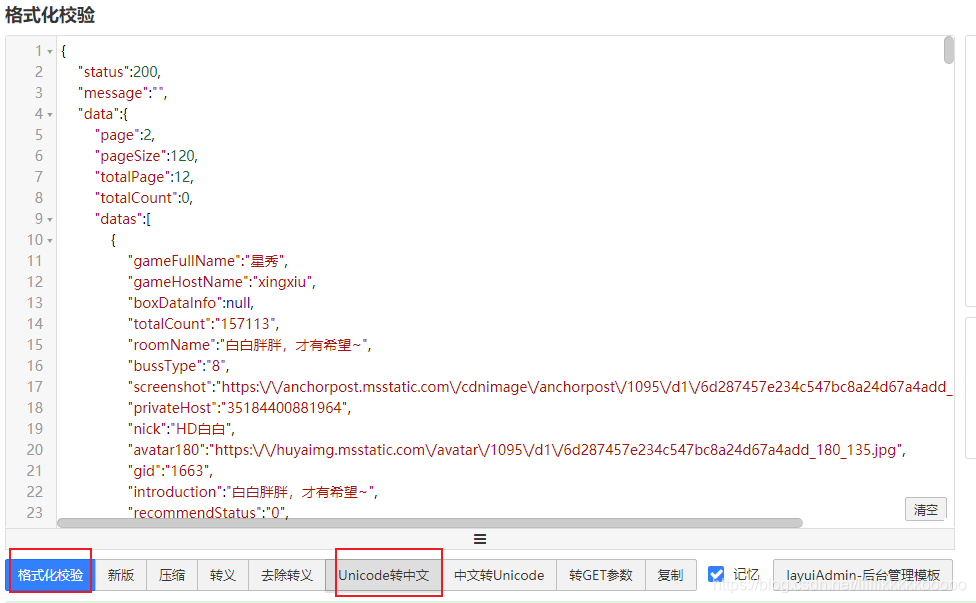
我们需要的数据位置

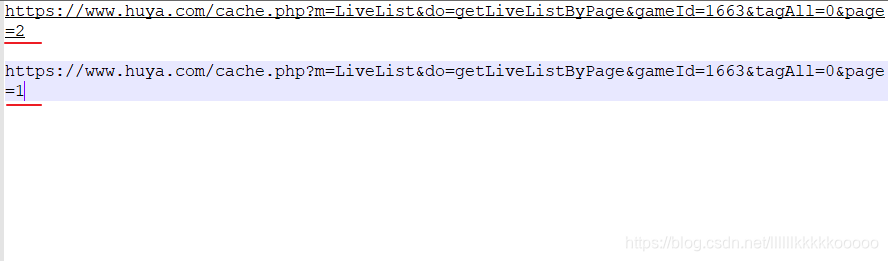
通过对请求链接分析知道,要想请求多页数据则可以通过更改page数值来得到
2.代码分析
huya.py
# -*- coding: utf-8 -*-
import scrapy
import json #导入json库
from Huya.items import HuyaItemclass HuyaSpider(scrapy.Spider):name = 'huya'allowed_domains = ['huya.com']start_urls = ['https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=1']num = 1 #页数def parse(self, response):#使用json.loads()将已编码的 JSON 字符串解码为 Python 对象,设置encoding='utf-8'可解决Unicode编码问题data_list = json.loads(response.text,encoding='utf-8')datas = data_list["data"]["datas"]for data in datas:#图片urlimg_url = data["screenshot"]#名称title = data["nick"]item = HuyaItem(img_url=img_url,title=title)yield item#进行多页请求,我们这测试只请求三页数据self.num += 1if self.num <= 3:next_url = "https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=" + str(self.num)yield scrapy.Request(url=next_url,encoding="utf-8")
pipelines.py
# -*- coding: utf-8 -*-# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlimport scrapy#导入ImagesPipeline库实现对图片的下载
from scrapy.pipelines.images import ImagesPipelineclass HuyaPipeline(ImagesPipeline):def get_media_requests(self, item, info):#获取图片url和名称img_url = item["img_url"]title = item["title"]yield scrapy.Request(url=img_url,meta={"title":title})#对图片进行重命名def file_path(self, request, response=None, info=None):name = request.meta["title"]#设置图片名称为主播名称return name + '.jpg'
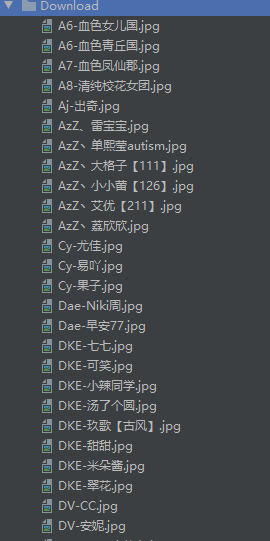
运行结果
三、完整代码
huya.py
# -*- coding: utf-8 -*-
import scrapy
import json
from Huya.items import HuyaItemclass HuyaSpider(scrapy.Spider):name = 'huya'allowed_domains = ['huya.com']start_urls = ['https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=1']num = 1def parse(self, response):data_list = json.loads(response.text,encoding='utf-8')datas = data_list["data"]["datas"]for data in datas:img_url = data["screenshot"]title = data["nick"]item = HuyaItem(img_url=img_url,title=title)yield itemself.num += 1if self.num <= 3:next_url = "https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=" + str(self.num)yield scrapy.Request(url=next_url,encoding="utf-8")
items.py
# -*- coding: utf-8 -*-# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass HuyaItem(scrapy.Item):img_url = scrapy.Field()title = scrapy.Field()
pipelines.py
# -*- coding: utf-8 -*-# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlimport scrapy
from scrapy.pipelines.images import ImagesPipelineclass HuyaPipeline(ImagesPipeline):def get_media_requests(self, item, info):img_url = item["img_url"]title = item["title"]yield scrapy.Request(url=img_url,meta={"title":title})def file_path(self, request, response=None, info=None):name = request.meta["title"]return name + '.jpg'
settings.py
# -*- coding: utf-8 -*-# Scrapy settings for Huya project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'Huya'SPIDER_MODULES = ['Huya.spiders']
NEWSPIDER_MODULE = 'Huya.spiders'LOG_LEVEL = "ERROR"# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'Huya (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'Huya.middlewares.HuyaSpiderMiddleware': 543,
#}# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'Huya.middlewares.HuyaDownloaderMiddleware': 543,
#}# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'Huya.pipelines.HuyaPipeline': 300,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'IMAGES_STORE = "Download"
觉得博主写的不错的可以关注收藏哦!
博主更多博客文章
这篇关于精美图片哪里找,保姆级教程爬取让你不再犹豫!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








